






作者:邓晓志,黄东,b, *,陈定华,王昌东,d,赖建煌c,d a华南农业大学数学与信息学院b农业农村部热带华南智慧农业技术重点实验室c中山大学计算机科学与工程学院d广东省信息安全技术重点实验室
引用:Deng X, Huang D, Chen D H, et al. Strongly augmented contrastive clustering[J]. Pattern Recognition, 2023, 139: 109470.
一、摘要
近年来,深度聚类因其通过深度神经网络进行联合表示学习和聚类而引起了越来越多的关注。在其最新发展中,对比学习已经成为一种有效的技术,可以显著提高深度聚类性能。然而,现有的基于对比学习的深度聚类算法主要集中在一些精心设计的增强方法上(通常只有有限的变换来保留结构),称为弱增强,但无法超越弱增强以探索更多的强增强机会(具有更激进的转换或甚至严重的扭曲)。在本文中,我们提出了一种端到端的深度聚类方法,称为强增强对比聚类(SACC),它将传统的双增强视图范例扩展到多个视图,并联合利用强增强和弱增强来增强深度聚类。特别地,我们利用具有三重共享权重的骨干网络,其中包含一个强增强视图和两个弱增强视图。基于骨干网络产生的表示,弱-弱视图对和强-弱视图对同时被利用于实例级对比学习(通过实例投影器)和类簇级对比学习(通过类簇投影器),这与骨干网络一起可以在纯无监督的情况下进行联合优化。对五个具有挑战性的图像数据集的实验结果表明,我们的SACC方法优于最先进的方法。
二、引言
数据聚类是无监督学习中的基本任务,其目标是将一组数据样本分组到不同的未标记的簇中[1]。传统的聚类算法[2–6],如K均值[2]、凝聚聚类(AC)[3]和谱聚类(SC)[4],通常依赖于手工设计的数据特征,这些特征缺乏表示学习能力,当处理一些复杂的高维数据(如图像和视频)时,可能会导致聚类性能次优,因为这些高维数据不容易人工提取合适的特征。
随着深度学习的快速发展,深度神经网络最近被采用来学习复杂高维数据聚类任务的适当表示。在过去几年中,许多基于深度神经网络的聚类算法(称为深度聚类算法)已经被设计出来[7–12]。作为最早的深度聚类工作之一,谢等人[13]提出了一种称为深度嵌入聚类(DEC)的方法,在深度神经网络中同时进行特征表示学习和聚类,其中通过基于Kullback–Leibler(KL)散度的损失来约束软标签的分布和辅助目标分布。郭等人[8]通过学习特征表示和保持局部结构来开发了改进的深度嵌入聚类(IDEC)方法。Caron等人[9]通过K均值迭代地对学习到的特征进行聚类,并使用聚类分配作为软标签来更新深度神经网络的权重。季等人[10]设计了一种称为不变信息聚类(IIC)的深度聚类方法,该方法旨在通过最大化原始图像和增强图像之间的互信息来进行更稳健的表示学习和聚类。
尽管取得了相当大的进展,这些方法[7–10]通常通过考虑整体分布(如软标签的分布或其他一些目标分布)来执行特征表示学习和聚类,而忽略了样本间的关系及其对比性。最近,对比学习已经成为提高深度聚类性能的有效技术,通常通过数据增强生成正样本对和负样本对,旨在最大化正样本对之间的一致性,并最小化负样本对之间的一致性。例如,van Gansbeke等人[14]提出了一种名为语义聚类自适应最近邻(SCAN)的两阶段深度聚类方法,该方法首先利用对比学习学习判别特征以找到K个最近邻,然后通过一个旨在将每个样本及其K个最近邻拉近的损失函数来训练网络。Dang等人[15]通过匹配局部和全局最近邻扩展了SCAN方法。Li等人[16]设计了一种称为对比聚类(CC)的单阶段方法,该方法以端到端方式联合利用实例级和类簇级对比学习。
尽管这些基于对比学习的深度聚类方法[14–16]在一些复杂图像数据集上显示出了实质性的改进,但它们仍然存在两个主要限制。首先,先前的基于对比学习的深度聚类方法倾向于利用一些弱增强来处理原始图像,但大多数忽视了更强的增强机会,以探索更具对比性的区分信息。虽然对于弱增强和强增强没有严格的定义,但通常认为,限制转换以保留结构的增强可以视为弱增强,而更激进的转换或扭曲可以视为强增强(如图1所示)[17]。
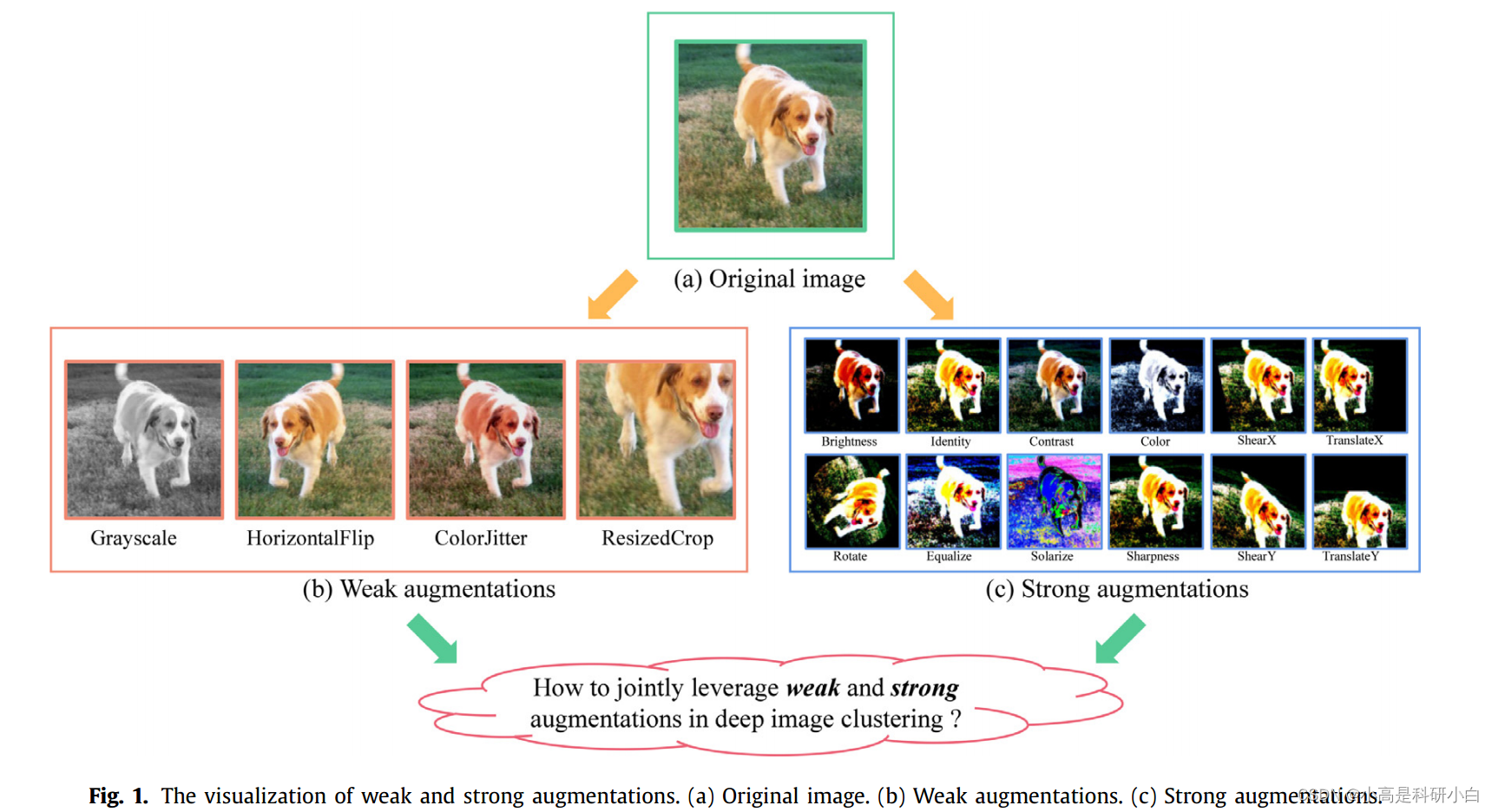
其次,它们大多采用一些具有两个增强视图的网络架构(通常来自相同的增强家族),但无法超越两个增强视图来探索多个增强视图(特别是具有不同程度的转换或扭曲)。最近,王和齐[17]表明,引入更强的增强可以显著增强对比学习所学习的特征表示,然而,这种方法是为通用对比学习而设计的,但缺乏同时实现表示学习和聚类的能力。如何在将传统的两视图网络架构扩展到多增强视图的同时,同时利用强增强和弱增强,仍然是一个未解决的问题,以在统一的深度聚类框架中探索多个增强视图的机会。
基于此,本文提出了一种新颖的端到端深度聚类方法,称为强度增强对比聚类(SACC),能够在一个多增强视图网络中同时利用强增强和弱增强,共同学习特征表示和聚类分配(如图2所示)。

具体而言,我们的SACC方法利用具有三重共享权重的骨干网络来生成强度增强视图和两个弱度增强视图的特征嵌入,然后可以构建弱-弱视图对和强-弱视图对进行实例级和群集级对比学习。通过联合利用强增强和弱增强以及实例级和群集级对比学习,网络训练可以纯粹以无监督方式进行,因此可以得到深度聚类结果。我们在五个具有挑战性的图像数据集上进行了大量实验,结果表明我们的SACC方法优于现有最先进的深度聚类方法。
本文的主要贡献总结如下。
1. 据我们所知,本文首次联合利用强增强和弱增强来进行无监督图像聚类任务。
2. 提出了一种新颖的端到端深度聚类方法,称为SACC,该方法利用三个增强视图同时进行实例级和类簇级对比学习。
3. 大量实验证实我们的SACC方法在多个具有挑战性的图像数据集上优于最先进的深度聚类方法。
三、相关工作
深度学习已被证明是一种优势技术,用于对非常复杂的数据进行无监督聚类。许多深度聚类方法已经被设计出来[7–11,18–24],它们的区别通常可以通过它们的网络损失来反映,如自动编码器(AE)的重建损失、变分自动编码器(VAE)的变分损失[25]、生成对抗网络(GAN)的损失[26]以及一些特定的聚类损失[27,28]。
基于AE的深度聚类方法通常通过重建损失和一些聚类损失来优化网络。重建损失衡量了原始输入和重建之间的不一致性。Yang等人[18]提出了深度聚类网络(DCN)方法,该方法联合建模了K均值聚类的降维。Ji等人[19]提出了一种基于AE的深度聚类方法,该方法利用自表达层进行深度子空间聚类。Dizaji等人[20]基于AE嵌入和相对熵最小化开发了深度嵌入正则化聚类(DEPICT)方法。
基于VAE的深度聚类方法利用VAE来规范网络训练,以避免过拟合,通过强制潜在空间遵循一些预定义的分布。Jiang等人[21]提出了一种变分深度嵌入(VaDE)方法,该方法通过最大化证据下界来优化VAE。Dilokthanakul等人[22]提出了一种高斯混合变分自动编码器(GMVAE)方法,通过在其优化目标中引入变分贝叶斯。
基于GAN的深度聚类方法试图通过最小-最大对抗博弈来训练网络。Springenberg[29]提出了一种分类生成对抗网络(CatGAN)方法,该方法联合利用GAN和正则化信息最大化(RIM)来训练网络。Chen等人[30]开发了一种信息最大化生成对抗网络(InfoGAN)方法,旨在提取可解释和解缠的特征用于深度聚类。
与通常将聚类损失与一些网络损失(如AE、VAE和GAN的损失)结合的上述三类不同,另一类深度聚类方法旨在仅使用聚类损失来训练网络。例如,Yang等人[27]利用卷积神经网络通过加权三元损失来学习表示特征和图像簇。Xie等人[13]设计了一种深度嵌入聚类(DEC)方法,该方法通过软标签的分布与辅助目标分布之间的KL散度损失联合优化深度嵌入和聚类。Guo等人[28]开发了一种自适应自主深度聚类与数据增强(ASPC-DA)方法,将数据增强和自主学习结合到深度聚类中。
最近,对比学习已成为一个热门话题[31],并且已经有几次尝试利用对比损失来提高深度聚类性能[14–16]。通常,van Gansbeke等人[14]提出了一种两阶段深度聚类方法,该方法采用对比学习作为一种前置任务来学习判别特征,然后利用第二阶段网络训练中的K个最近邻(通过学习到的特征)。Dang等人[15]提出了一种最近邻匹配(NNM)方法,不仅考虑全局最近邻,还考虑了局部最近邻。Li等人[16]在实例级和聚类级上执行对比学习,并通过聚类投影器获得聚类结果。
四、方法提出
4.1 Framework overview 架构概述
SACC的整体框架如图2所示。在SACC中,我们利用具有三重共享权重的骨干网络,学习三种增强视图(包括一个强增强视图和两个弱增强视图)的表示。具体而言,给定一个包含N个图像样本的小批量,我们对每个输入图像xi执行一种强增强和两种弱增强,表示为{v1 1, . . ., v1 N, v2 1, . . ., v2 N, v3 1, . . ., v3 N},其中包含N个强增强样本和2 · N个弱增强样本。骨干网络fθ将每个增强样本vj i转换为z j i,其中i ∈ [1, N],j ∈ {1, 2, 3},然后将其输入到实例投影器和群集投影器。通过实例投影器gθ将z j i转换为yj i,通过群集投影器hθ将z j i转换为c j i,分别通过这两个投影器在这个小批量的样本上构建了两种类型的特征矩阵。然后,通过同时优化实例级对比损失(在实例投影器中的特征矩阵的行空间中)和类簇级对比损失(在群集投影器中的特征矩阵的列空间中),可以进行无监督网络训练。
4.2 Augmentations: from weak to strong 增强:由弱到强
对比学习已经显示出在无监督表示学习中的良好能力[31],并且已经被一些最近的深度聚类方法[14–16]所利用。在先前基于对比学习的深度聚类方法中,通常利用一些弱增强(具有有限的变换以保留图像结构)来形成正样本对。然而,很少有方法超越了弱增强,利用了一些更强的增强(具有更激进的变换或甚至严重的扭曲)。
在本文中,我们已经表明,联合使用强增强和弱增强可以显著增强深度聚类框架中的对比学习能力,用于表示学习和聚类。具体来说,关于弱增强,我们采用了五种常用的增强方式,分别是ResizedCrop、HorizontalFlip、ColorJitter、Grayscale和GaussianBlur,用于生成弱增强样本。对于SACC中的两个弱增强视图,从弱增强中随机选择两种增强方式用于每个输入图像。除了弱增强外,我们还采用了一个包含十四种更强变换的增强[17],包括AutoContrast、Brightness、Color、Contrast、Equalize、Identity、Posterize、Rotate、Sharpness、ShearX/Y、Solarize和TranslateX/Y。由于强增强会更激进地转换原始图像,因此它可以提供一些在弱增强中不存在的额外线索,用于学习具有区分性的表示。通过联合建模强增强和弱增强,所提出的SACC框架能够获得更具代表性的图像模式和语义信息,用于学习聚类友好的表示。
4.3 . Network architecture 网络架构
SACC的网络架构由三个模块组成,即骨干网、实例投影器和类簇投影器。在实例投影器和类簇投影器中分别使用实例级对比损失和类簇级对比损失,它们分别使用弱增强视图和强增强视图进行联合训练。下面,我们将详细描述这三个模块以及总体目标函数。
1. Backbone network with triply-shared weights 共享权重的骨干网络
在提出的框架中,我们利用具有三重共享权重的骨干网络(如图2所示)。具体而言,三个增强视图,包括一个强增强视图和两个弱增强视图,共享骨干网络fθ,通过这个网络可以学习三个视图的表示,表示为z1 i = f(v1 i )、z2 i = f(v2 i )和z3 i = f(v3 i )。然后,这三个特征表示被馈送到每个投影器中,用于后续的实例级和群集级对比学习。需要注意的是,我们可以采用不同的网络结构作为骨干网络。在本文中,我们采用了广泛使用的ResNet-34 [32]作为我们的骨干网络。
 2. Instance projector with weak-strong augmentations 具有弱强增强的实例级投影器
2. Instance projector with weak-strong augmentations 具有弱强增强的实例级投影器
在实例投影器中,使用一个两层的非线性多层感知器(MLP),表示为g(·),将z j i转换为一个低维空间,即yj i = g(z j i),其中yj i被解释为实例表示,其中i ∈ [1, N],j ∈ {1, 2, 3}。
由于有三个增强视图,包括两个弱增强视图和一个强增强视图,我们使用一个弱-弱对和一个强-强对来形成正样本对和负样本对。具体而言,对于每个输入图像,其两个弱增强样本形成一个正样本对,而其强增强样本和其第一个弱增强样本形成另一个正样本对。同时,负样本对由来自不同输入图像的增强样本形成。
定义了正样本对和负样本对后,实例级对比损失被用来最大化正样本对的一致性,同时增加负样本对之间的距离。为了衡量实例对的相似度,可以使用余弦相似度,即:


3. Cluster projector with weak-strong augmentations 具有强弱增强的类簇级投影器
类簇级投影器是一个带有softmax层的两层非线性MLP,表示为h(·)。类簇级投影器的输出层维度,表示为M,等于类别数量(或期望的聚类数量)。通过类簇级投影器计算得到的每个样本的输出表示,表示为˜c j i = h(z j i),可以视为该样本属于不同类别的概率。因此,c˜ j i可以作为增强样本的软标签。
对于三个增强视图中的每一个,对于一个包含N个样本的小批量,可以得到一个具有N行和M列的特征矩阵,其中c j m表示特征矩阵的第m列,其中m ∈ [1, M],j ∈ {1, 2, 3}。也就是说,c j m可以被视为增强j的第m个聚类中N个样本的分布。我们将来自两个不同增强视图的相同聚类视为一个正聚类对,将其他聚类对视为负聚类对。然后,对于一个聚类c j m,可以定义群类簇级对比损失为:
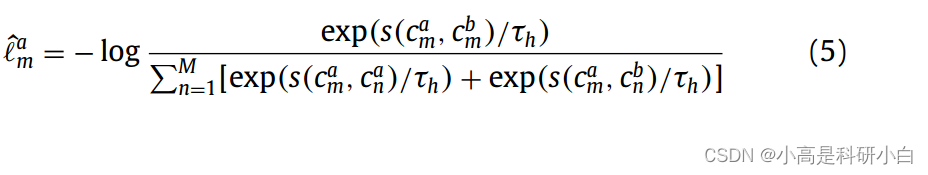

对于每个原始图像,我们在类簇级投影器中使用三个增强视图对,即每两个增强视图形成一个视图对。然后将类簇级投影器的对比度损失定义为:
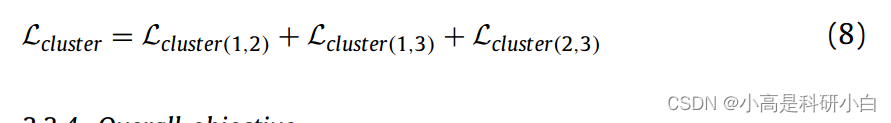 4 .Overall objective 总损失
4 .Overall objective 总损失
骨干网、实例级投影器和类簇级投影器的优化以端到端方式共同完成。总体目标函数由实例级对比损失和类簇级对比损失组成,即

 五、实验
五、实验
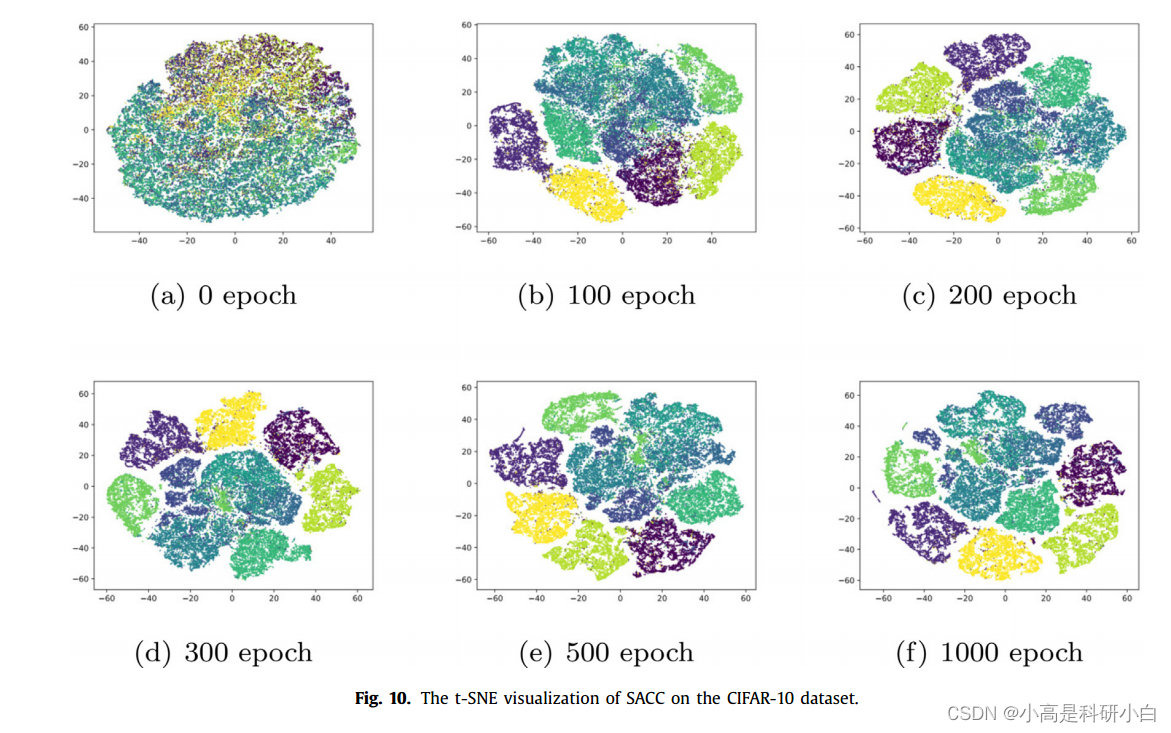
六、结论与展望
本文提出了一种名为SACC的新型深度聚类方法。与以往基于对比学习的深度聚类方法不同,这些方法通常将一些弱增强与有限变换结合起来,我们的SACC方法能够同时利用强增强和弱增强来增强对比表示学习和聚类。具体而言,我们利用具有三重共享权重的骨干网络,用于三种增强视图,包括一个强增强视图和两个弱增强视图。从骨干网络中可以得到三个视图的表示(对于弱增强和强增强样本),然后将它们馈送到两种类型的投影器,即实例投影器和聚类投影器,以便分别进行实例级对比学习和聚类级对比学习。此外,无监督训练是以端到端的方式同时优化骨干网络和两个投影器进行的,因此最终的聚类结果可以在聚类投影器中实现。我们在五个基准图像数据集上进行了大量实验,结果表明,与最先进的深度聚类方法相比,所提出的SACC方法具有更优越的聚类性能。
在本文中,我们主要关注图像数据的深度聚类任务。在未来的工作中,将所提出的SACC框架扩展到其他类型的数据可能是一个有前景的方向,例如时间序列数据和文档数据,这涉及如何在这些类型的数据上共同强化弱增强和强增强,以及如何设计具有多个增强视图的混合对比学习网络。

















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









