







- 题目:GraphSR: A Data Augmentation Algorithm for Imbalanced Node Classification
- 链接:https://arxiv.org/pdf/2302.12814.pdf
- 源码:
- 会议:AAAI (CCF-A)
- 时间:2023.02
- 机构:澳门大学智慧城市物联网国家重点实验室
- 摘要:图神经网络(gnn)在节点分类任务中取得了巨大的成功。然而,现有的gnn自然倾向于具有更多标记数据的多数类别,而忽略那些具有相对较少标记数据的少数类别。传统的方法往往采用过采样的方法,但往往会导致过拟合问题。最近,一些工作提出从标记的节点中合成额外的少数类节点,然而,不能保证这些生成的节点是否真的代表相应的少数类。事实上,节点合成不当可能会导致算法泛化不足。为了解决这个问题,在本文中,我们寻求从图的大量未标记节点中自动增加少数类。具体来说,我们提出了GraphSR,这是一种新的自训练策略,基于相似性的选择模块和强化学习(RL)选择模块,以增加具有显著多样性的未标记节点的少数类。第一个模块找到与标记的少数节点最相似的未标记节点子集,第二个模块通过RL技术进一步从子集中确定具有代表性和可靠的节点。此外,基于RL的模块可以根据当前训练数据自适应确定采样尺度。这种策略是通用的,可以很容易地与不同的gnn模型相结合。我们的实验表明,所提出的方法在各种类别不平衡数据集上优于最先进的基线.
1. 介绍


2. 方法
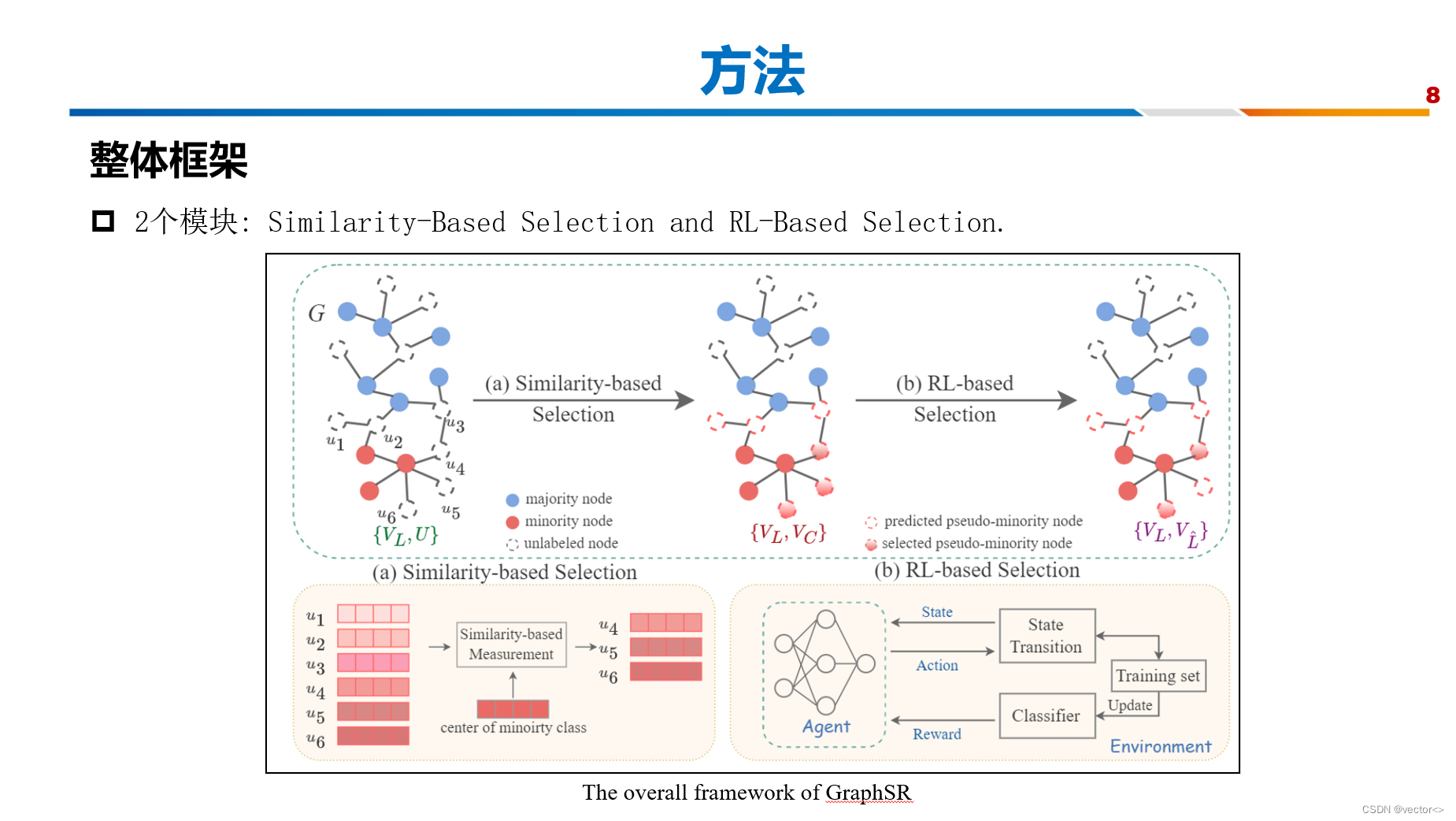
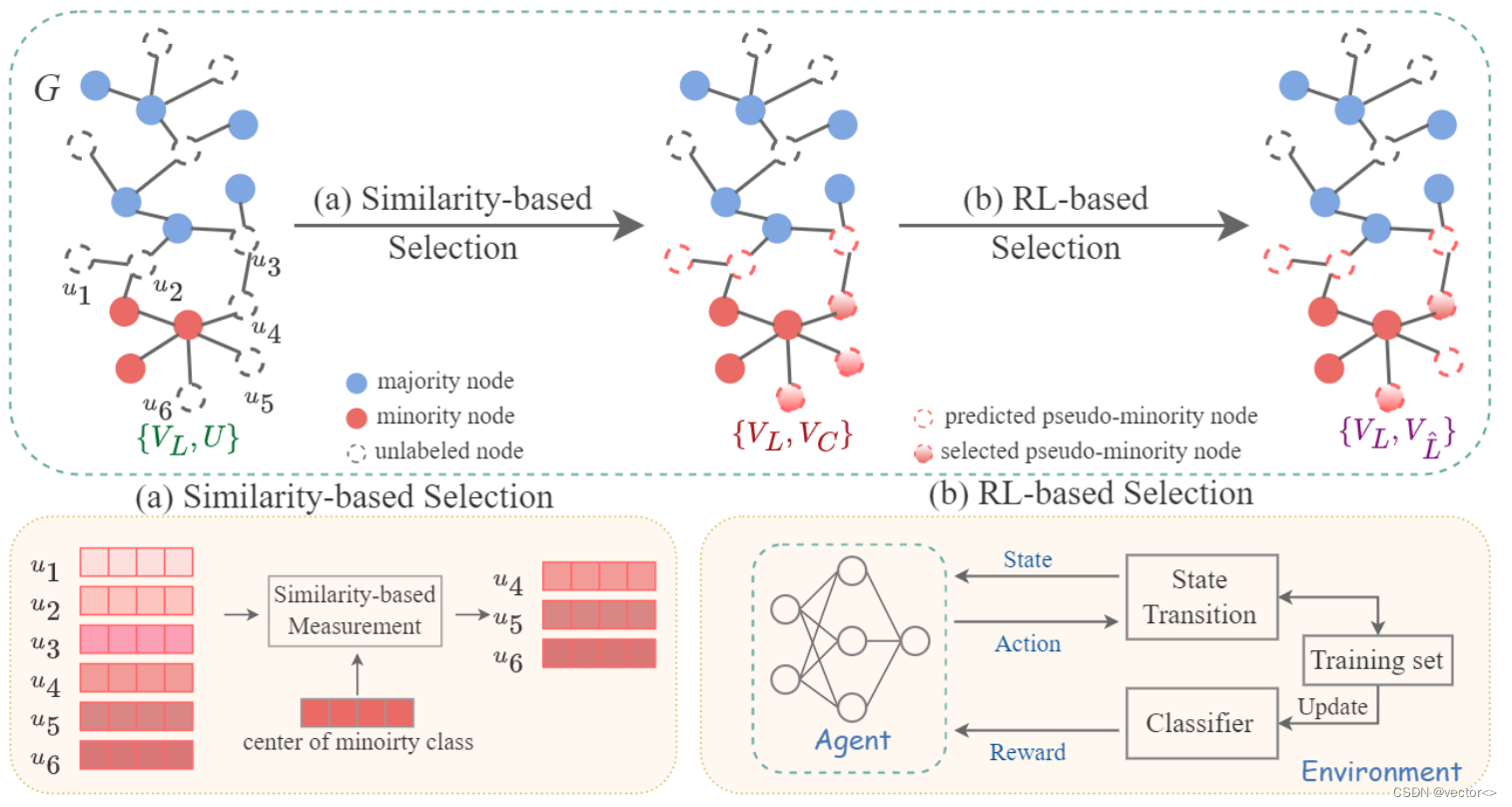
- 基于这两步选择,模型会为自动地在无标签节点中,挑选出那些最有可能是少数类的节点来补充少数类,使得训练数据集从之前的不平衡状态达到平衡状态。
- 在这两步选择之前,首先会用目前已有的带标签数据集训练一个初始的gnn,使用这个gnn求得图上所有结点的嵌入,当然这个给gnn是有偏差的,因为属实的训练数据集是很不平衡的
-
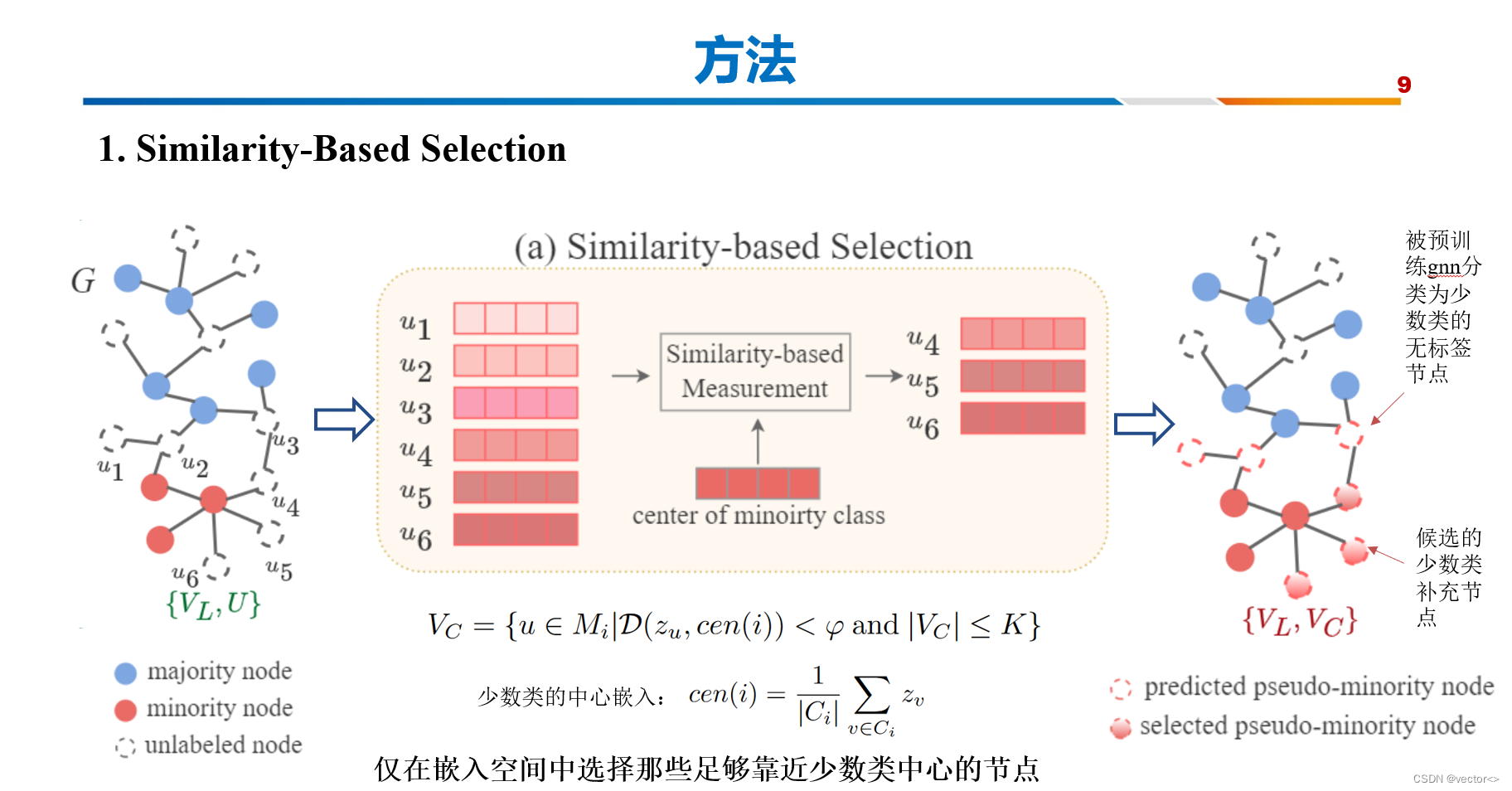
首先我们来看基于相似性的选择,通过这个模块,数据集从左图变成了右图,我们先看一下发什么什么变化
-
蓝色节点代表多数类,红色节点代表少数类,白色的虚线节点代表的是无标签节点。经过选择之后,有一些白色的虚线节点变成了红色的虚线节点,这代表的是为这些节点打上了少数类的伪标签,并且有一部分红色的虚线节点被挑选为了红色的实心节点,这代表这将这些伪标签节点有可能被选中并归入到候选集中,这里我们城他们为候选补充节点。
-
我们来看一下如何实现的
-
首先根据预训练的gnn,拿到被分类为少数类的无标签节点的嵌入,也就是这里的u1到u6
-
然后计算少数类的中心嵌入
-
然后计算这些少数类无标签节点到少数类中心嵌入之间的欧几里得距离,仅挑选top K 个足够靠近少数类中心的节点作为候选补充节点
-
D:使用欧几里得距离来度量 伪标签少数类结点 与 少数类的中心嵌入 之间的相似度
-
K:只选择最相似的K个结点,图中K=3

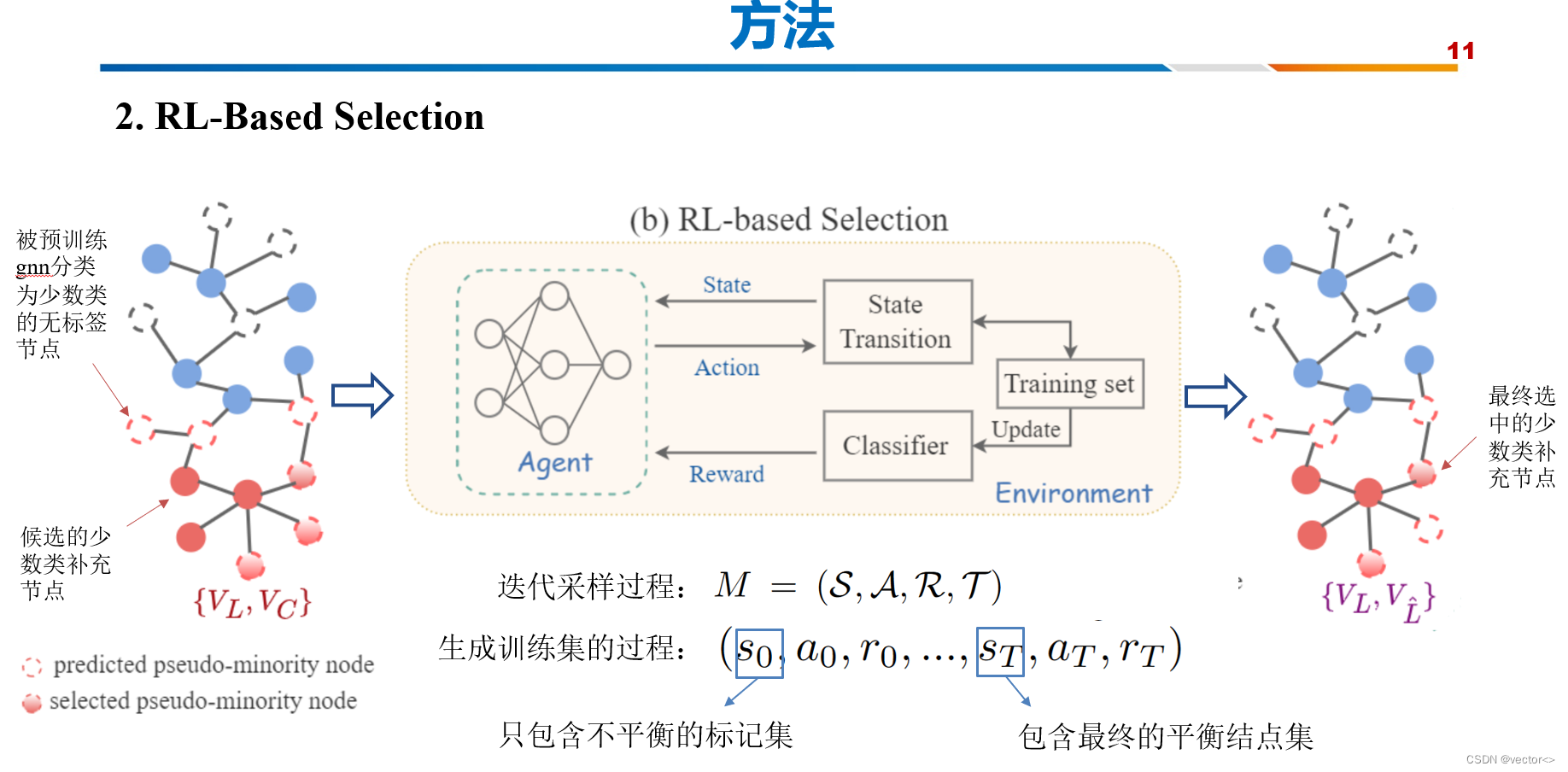
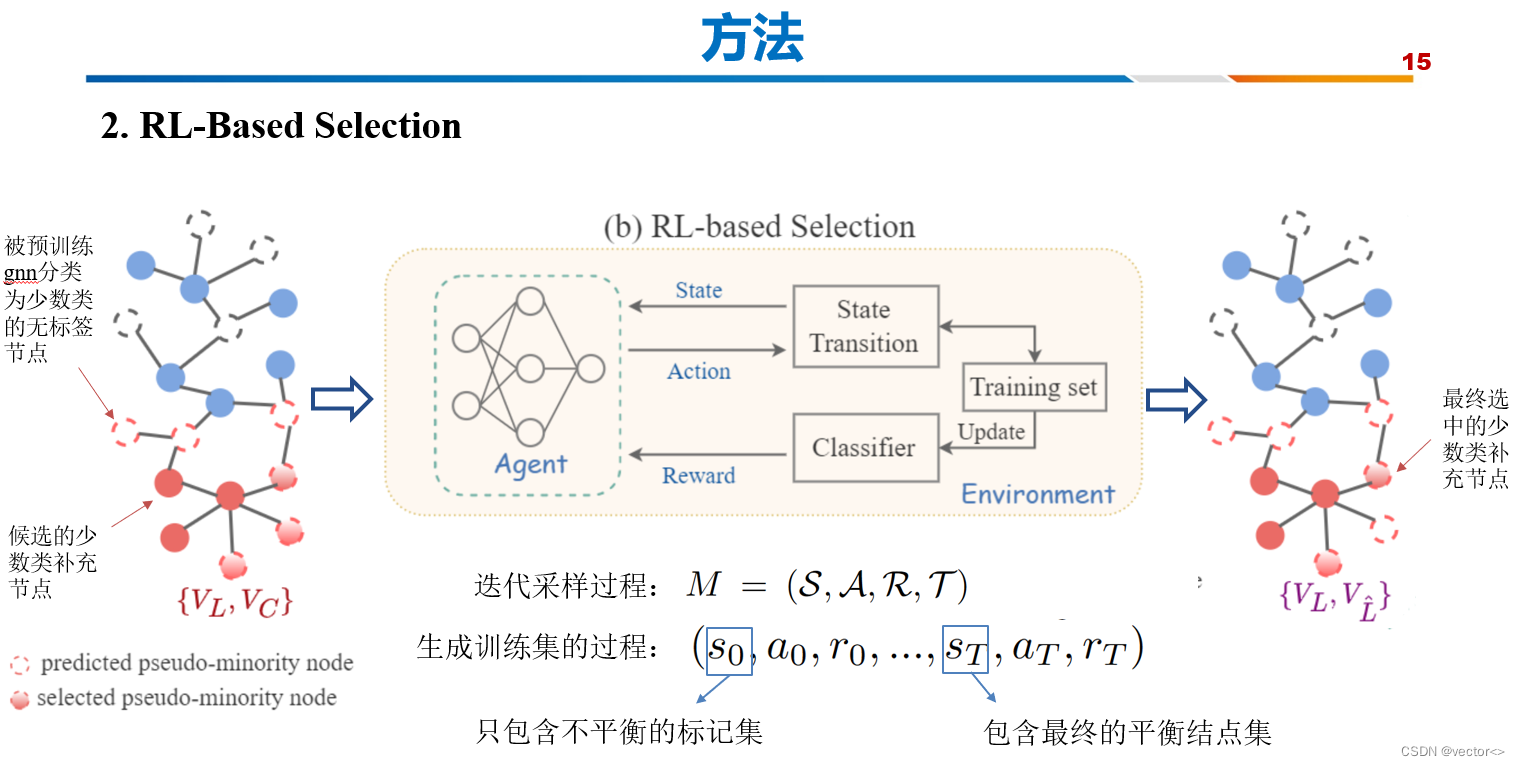
- 经过强化学习模块,上一步得到的这个图进一步变成了右边这个样子,可以看到主要的变化是上一步挑选的 候选少数类补充结点集合缩小了,有一些噪声的结点被排除掉了。
- 这个过程是一个自动实现的,这篇文章设计了一个迭代采样过程,它被表述为马尔可夫链, M = (S, A, R, T)。
- 生成平衡训练集的过程可以用(0,a0, r0,…), sT, aT, rT),其中初始状态so0只包含不平衡的标记集,最后状态sT包含最终补充的平衡节点集。



- 最后我们来看一些整体的决策过程
- Agent根据当前状态作出行动,更新状态,同时训练集也会发生改变,通过这个训练一个分类器,将分类效果作为agent的奖励来调整它的下一步决策过程。
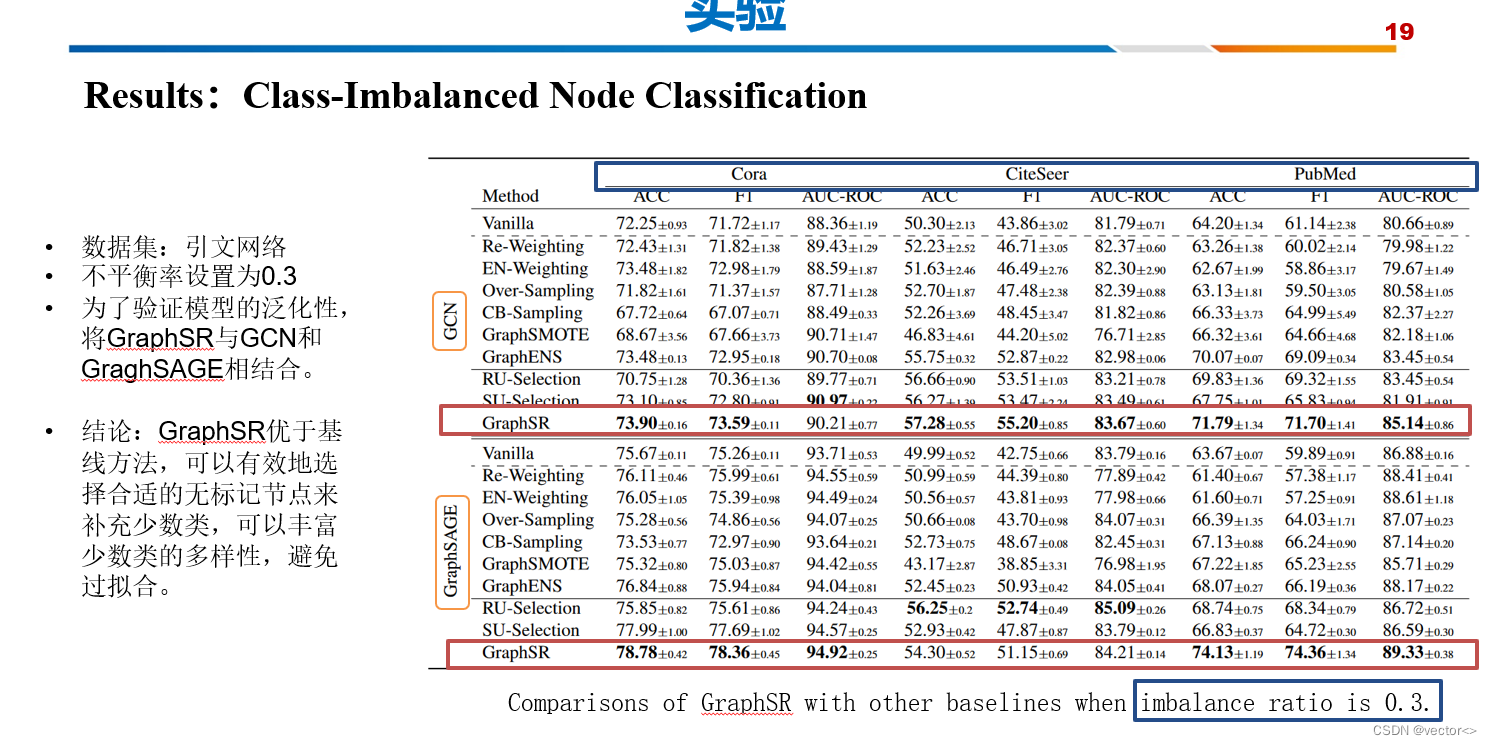
3. 实验

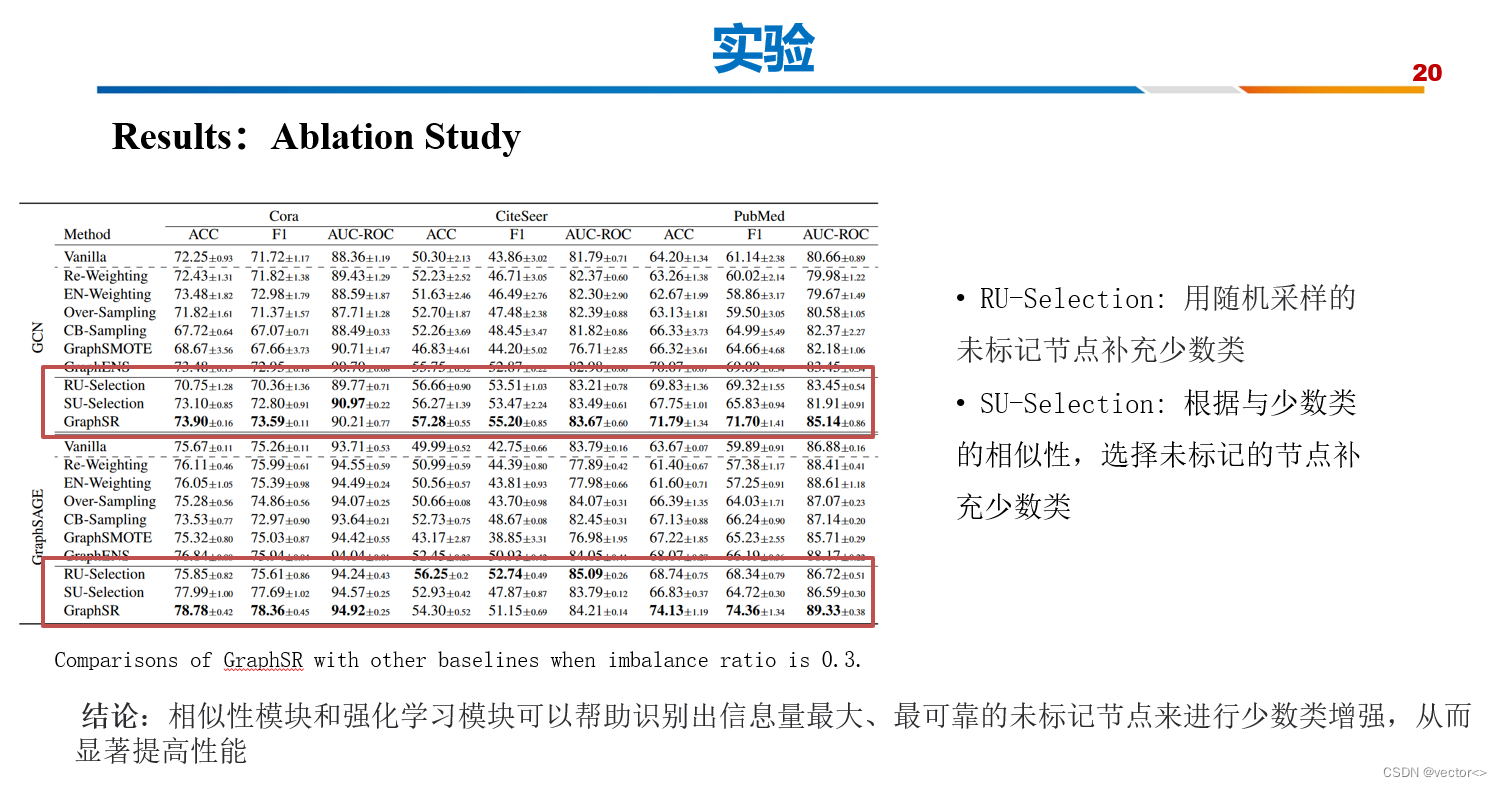
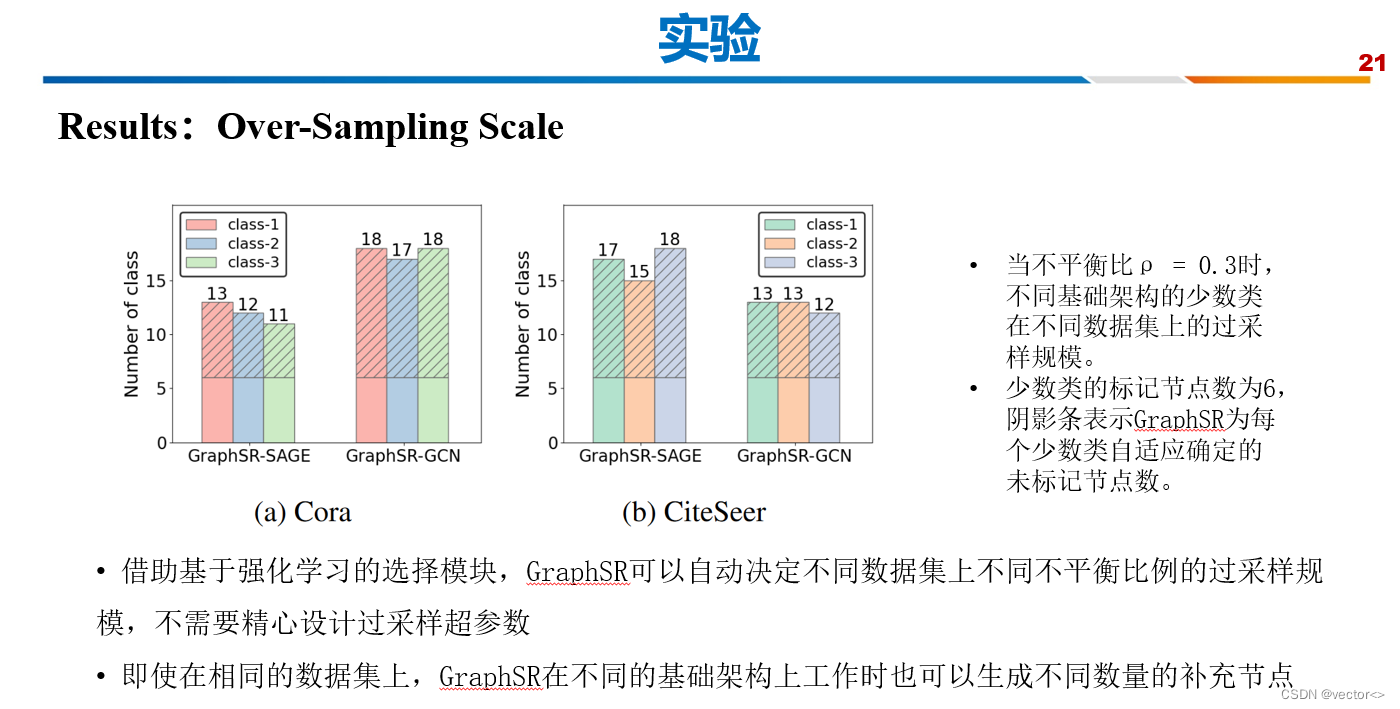
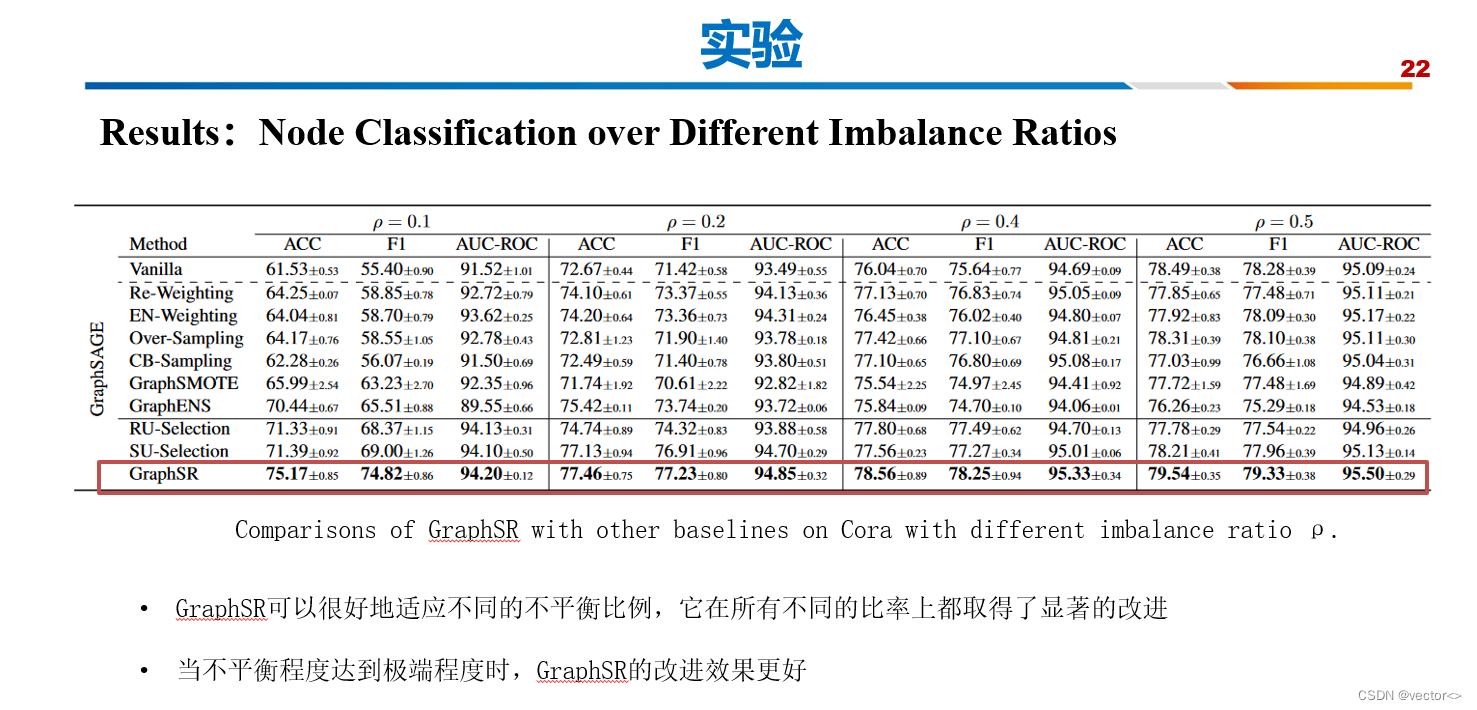
4. 结论

翻译
1. 介绍
研究动机:
-
图数据分析的相应技术受到了社区的极大关注。而gnn(图神经网络)是节点分析最成功的技术之一。
-
然而,大多数现有的gnn都是在节点类别平衡的假设下训练的。不幸的是,这个假设在许多现实世界的情况下并不正确,在训练过程中,某些类别的节点可能比其他类别的节点少得多。例如,在欺诈检测任务中,社交网络中的欺诈者数量远小于良性网络的数量(Liu et al. 2021)。类别不平衡问题可能会导致算法在表示学习中偏向多数类而忽略少数类。因此,将gnn直接应用于许多现实世界的类不平衡图是具有挑战性的。
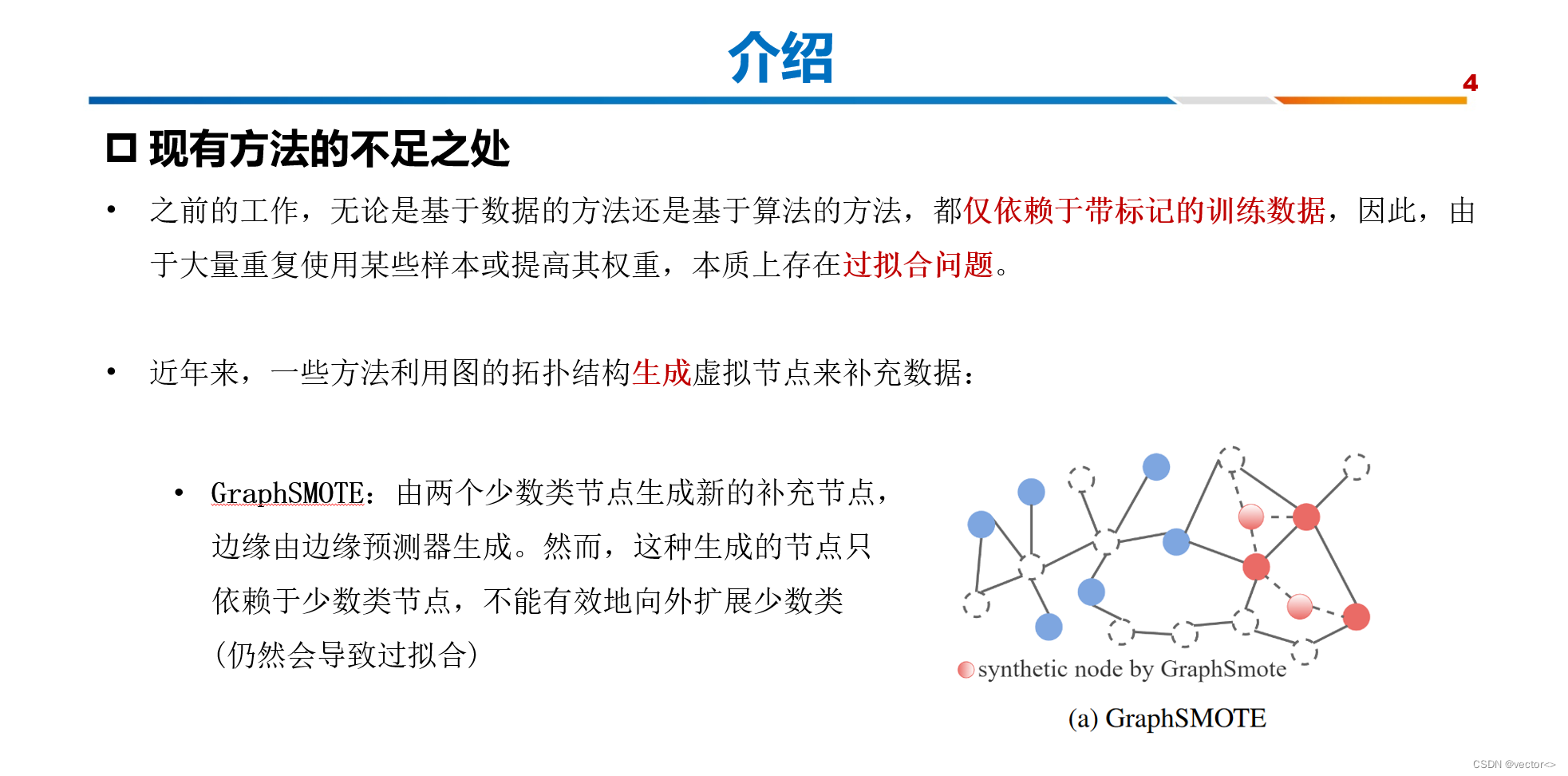
现有方法的不足之处:
-
事实上,不平衡问题已经被解决了很长时间,机器学习领域已经取得了一些重大进展。一般来说,解决方案可以归纳为3个流:数据级方法、算法级方法和混合方法。数据级方法试图通过过采样(Chawla et al. 2002)或欠采样(Kubat, Matwin et al. 1997)对训练样本进行预处理来平衡类分布; 算法级方法考虑误分类代价(Ling and Sheng 2008)或修改损失函数(Cui et al. 2019)以缓解类别不平衡问题的影响; 混合方法结合了以上两种方法(Batista, Prati和Monard, 2004)。然而,无论是基于数据的方法还是基于算法的方法,都仅仅依赖于标记的训练数据,因此,由于大量重复使用某些样本或提高其权重,本质上存在过拟合问题。
-
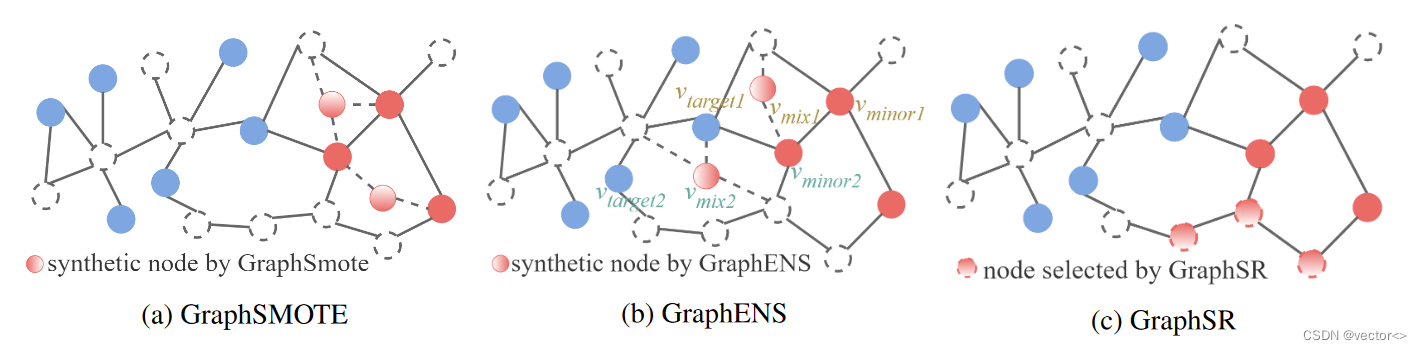
实际上,图数据自然地呈现了节点的拓扑结构,可以利用这些拓扑结构生成虚拟节点作为训练算法的数据扩充。在这方面,最近GraphSMOTE (Zhao、Zhang和Wang 2021)扩展了SMOTE (Chawla et al. 2002),在嵌入空间中的两个少数类节点之间进行插值以合成新样本,并利用边缘预测器来确定合成样本的邻域,如图1a所示。然而,这种生成的节点只依赖于少数类节点,不能有效地向外扩展少数类(仍然会导致过拟合)。
-
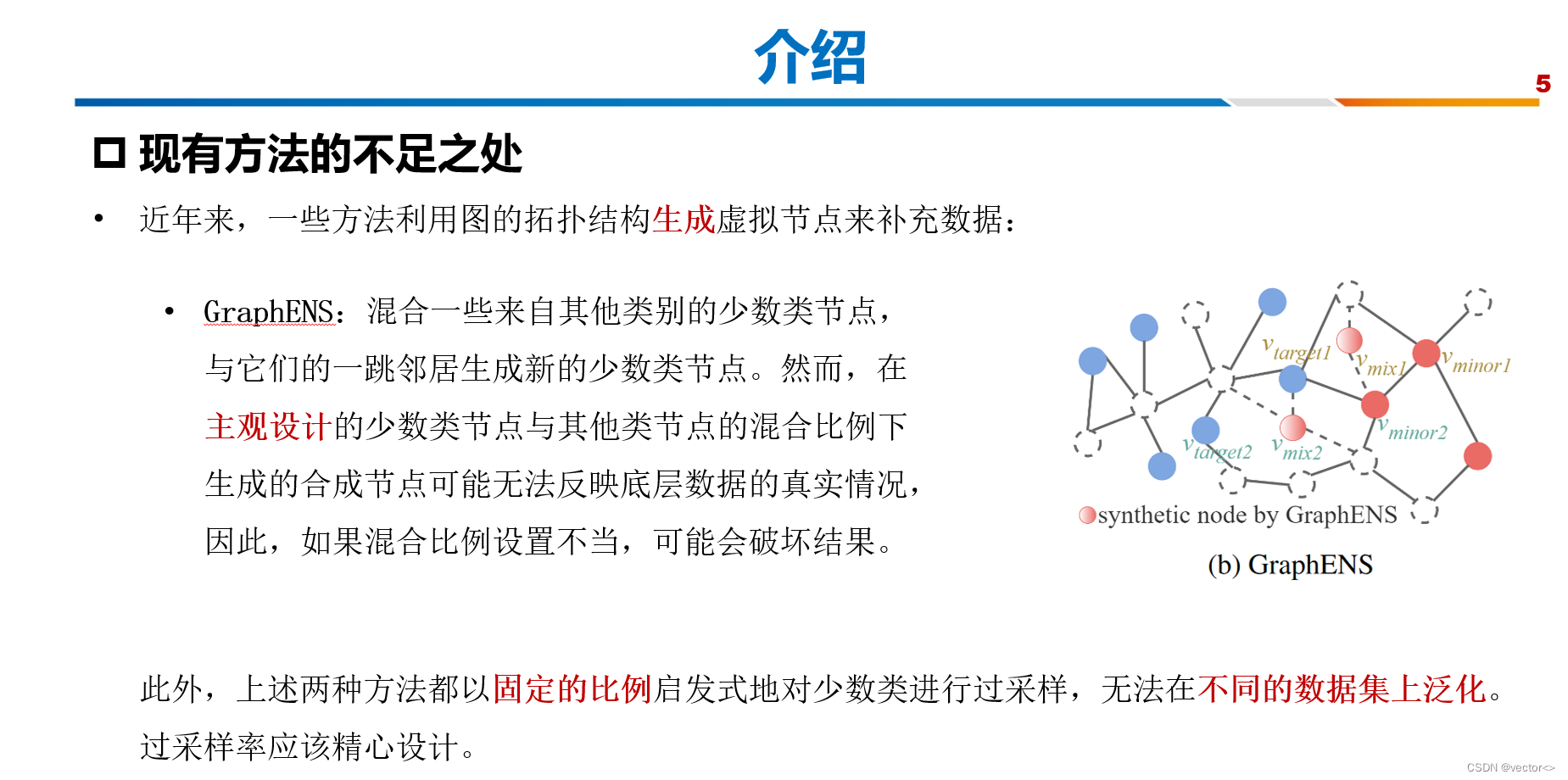
为了进一步解决这个问题,GraphENS (Park, Song, and Yang 2022)通过混合一些来自其他类别的少数类节点,与它们的一跳邻居合成新的少数类节点,从而可以丰富这些少数类的多样性,如图1b所示。然而,在主观设计的少数节点与其他节点的混合比例下生成的合成节点可能无法反映底层数据的真实情况,因此,如果混合比例设置不当,可能会破坏结果。此外,上述两种方法都以固定的比例启发式地对少数类进行过采样,**无法在不同的数据集上泛化。**过采样率应该精心设计,否则当对少数类设置过大的过采样率时,多数类的性能会下降。
-
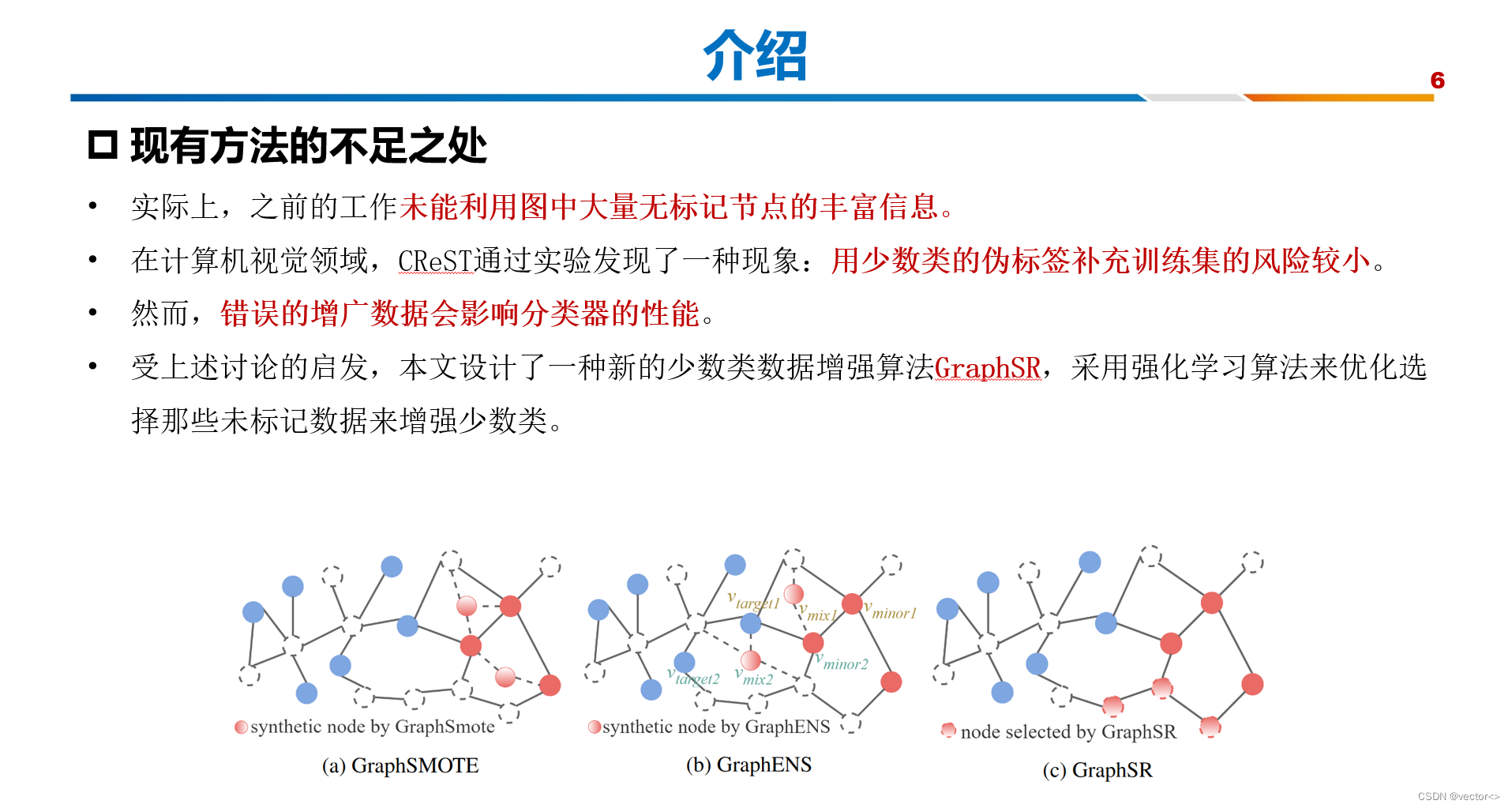
事实上,之前的工作未能利用图中大量无标记节点的丰富信息,这些信息是生成更有希望的数据以增强少数类的宝贵资源。在计算机视觉领域,CReST (Wei et al. 2021)通过实验发现了一种现象,即少数类的召回率很低,但达到了令人惊讶的高精度,因此少数类伪标签补充训练集的风险较小。然而,在图上的节点分类任务中,仍有许多误分类的节点位于少数类中,详情见附录。直接在图上应用CReST效果不好,因为少数伪标签不够可靠,而且没有机制限制这些有噪声的未标记样本补充到训练集。错误的增广数据会影响分类器的性能。
本文的方法:
-
受上述讨论的启发,本文设计了一种新的少数类数据增强算法GraphSR,如图1c所示,其中采用强化学习算法 来优化选择那些未标记数据来增强少数类的策略。
-
首先用标记的数据预训练一个基线GNN模型,然后可以为那些未标记的数据生成伪标签。然而,在不平衡数据上训练的基线GNN模型可能会偏向大多数类别,导致对未标记数据的预测很差。为了解决这个问题,GraphSR没有通过仅根据伪标签随机选择一些未标记的节点来补充少数类,而是首先利用基于相似性的选择模块为每个少数类过滤出最相似的未标记节点,旨在从大量未标记节点中有效地发现潜在节点,并维护一个潜在数据池来增强这些少数类。在第二步中,为了降低噪声节点的影响,设计了另一个模块,通过强化学习技术从候选集中自适应地选择信息丰富且可靠的节点,称为基于强化学习的选择模块。在实践中,GraphSR训练一个选择器作为代理来决定保留候选集中的哪个节点,然后使用使用增强后的数据集训练的改进分类器对该动作进行环境评估,奖励是根据类平衡验证集的性能分配的。通过两步选择,GraphSR可以获得最优的无标记节点来补充不平衡的训练数据。这样,我们可以使用新的训练集来训练一个无偏的GNN分类器。
主要贡献:
- 本文提出在半监督环境下研究类不平衡节点分类问题,利用大量未标记节点来补充少数类。
- 设计了一种新的数据增强策略GraphSR,有效地对信息丰富和可靠的无标记节点进行采样,以增强少数类的多样性。该方法能够根据当前训练数据自适应地确定采样规模,对不同的数据集具有更强的泛化能力。
- 在多个数据集上的实验结果表明,所提出的方法优于所有基线方法。更重要的是,该技术可以注入到任何GNNs算法中。
2. 相关工作
- 重加权方法试图通过提高少数类的权重来修改损失函数(Lin et al. 2017;Cui et al. 2019),或扩大少数类的边际(Cao et al. 2019;Liu等。2019;Menon et al. 2020)。
- 重采样方法试图通过有意地预处理训练样本来平衡数据分布,例如对少数类进行过采样(Chawla等人2002年),对多数类进行欠采样(Kubat、Matwin等人1997年),以及两者的结合(Batista、Prati和Monard 2004年)。随着神经网络的改进,重采样策略不仅通过采样技术来增强少数类(Liu等人2020),还通过生成思想(Kim, Jeong和Shin 2020;Wang et al. 2021)。典型的方法SMOTE (Chawla et al. 2002)是利用插值技术在少数类样本及其最近邻样本上生成新样本。其他作品(金、郑、申2020;Wang et al. 2021)通过迁移多数类的公共知识来合成少数类样本。然而,现有的方法大多针对单一性数据,不能直接用于需要考虑对象之间关系的图数据。
3. 问题定义
-
本文针对图上的半监督类不平衡节点分类问题,即标记节点的比例很小,而未标记节点的比例很大。我们将使用有限数量的标记节点来训练分类器,并在同一图的节点上进行测试。在我们的设置中,每个节点只属于一个类别,类别分布不平衡,即训练集中多数类别的样本明显多于少数类别的样本。
-
给定一个带有标记节点集 V L V_L VL的 G G G,它是类不平衡的,我们的目标是训练一个无偏分类器 f f f,在 U U U中的未标记节点的帮助下,它可以很好地适用于整个类。
4. 方法
在本节中,我们将介绍GraphSR的细节,它基于自我训练技术。事实上,自训练(Scudder 1965)是半监督学习中广泛使用的一种经典方法。原则上,该算法在可用的标记集上迭代训练模型,并使用训练好的模型为那些未标记的数据生成伪标记; 然后,从未标记集合中选择置信样本与训练集结合,进一步重新训练模型,直至收敛。
为了适应图中类不平衡的问题,基于自训练的思想,我们提出了两种组件来自适应地从未标记的数据中选择信息丰富且可靠的节点来补充少数类,如图2所示。
- 首先,GraphSR基于标记的集合 V L V_L VL训练一个GNN模型,并为 U U U中的未标记节点生成伪标签。
- 然后设计一个基于相似度的选择模块,识别与少数类节点最相似的未标记节点,筛选出少数类的候选节点集 V C V_C VC;
- 其次,GraphSR利用强化学习模块自适应地选择信息丰富且可靠的节点以获得适当的补充集 V ˆ L VˆL VˆL,以优化和有效地丰富少数类的多样性,最终增强训练集。
- 通过增强训练数据{VL, VˆL},我们可以训练一个类别平衡的节点分类器。
基于相似性的选择
在半监督环境下扩充少数类的一个简单方法是从原始图中找到类似的无标记节点。一般来说,由GNNs衍生的节点表示可以反映节点的类间和类内关系,即同类的节点在嵌入空间中会更近,而不同类的节点在隐空间中应该更远。因此,不直接使用节点的原始属性来比较节点,而是在标记集上训练GNN模型来学习节点表示,可以同时捕获节点的特征属性和拓扑信息。具体而言,我们在不平衡训练集 { V L , Y L } \left\{ V_L, Y_L\right\} {VL,YL}上训练GNNs分类器g,其消息传递和融合过程表示为:
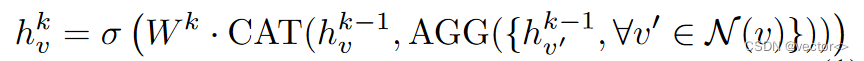
通过这种选择,我们可以找到最有可能被预测为少数类的节点,但是g是不可靠的,因为它是用不平衡的数据训练的。为了解决这个问题,GraphSR利用强化学习的另一个选择模块,抽取出能够准确提高分类器性能的可靠节点,并自适应地确定每个少数类的过采样尺度。
基于强化学习的选择
这个选择模块的关键任务是指定一个采样程序,可以自适应地选择未标记的节点来补充少数类。由于无标记节点缺乏监督信息,采用强化学习方法进行节点选择。本文设计了一个迭代采样过程,它被描述为一个马尔可夫决策过程(MDP), M = (S, a, R, T)。生成平衡训练集的过程可以用轨迹(s0, a0, r0,…, sT, aT, rT),其中初始状态s0只包含不平衡的标记集合,末状态sT包含最终的补充平衡节点集合。
GraphSR试图使用强化学习算法来学习一个最优策略,以允许代理决定在部分观察到的环境中保留或丢弃未标记的节点。特别地,代理(即选择器)顺序遍历 V C V_C VC中的少数候选节点。对于每个节点ut,智能体根据当前状态通过πθ表示的策略网络采取行动,然后环境根据行动分配奖励。智能体根据奖励更新策略网络。在智能体与环境进行足够的交互后,智能体可以学习一个最优策略,以最优地选择未标记节点来补充少数类。通过基于强化学习的选择,该算法更容易推广到不同的数据集,而无需额外确定过采样规模。接下来,我们将详细讨论基于强化学习的选择模块的主要组成部分。



















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











