







摘要
Mobile vision transformers(MobileViT)在包括分类和检测在内的多个移动视觉任务上可以达到state-of-the-art的性能。尽管这些模型参数较少,但与基于卷积神经网络的模型相比,它们的延迟较高。MobileViT中的主要效率瓶颈是transformer中的multi-headed self-attention(MHA),其计算复杂度相对于token(或patch)数量k为 O ( k 2 ) O(k^2) O(k2)。此外,MHA需要代价高昂的操作(例如,按batch的矩阵乘法)来计算self-attention,这会影响在资源受限设备上的延迟。本文提出了一种具有线性复杂度 O ( k ) O(k) O(k)的可分离self-attention方法。该方法的一个简单但有效的特性是,它使用逐元素操作来计算self-attention,使其成为资源受限设备的良好选择。改进后的模型MobileViTv2在多个移动视觉任务上达到了state-of-the-art的性能,包括ImageNet目标分类和MS-COCO目标检测。在仅有大约三百万参数的情况下,MobileViTv2在ImageNet数据集上达到了75.6%的top-1准确率,比MobileViT高出约1%,同时在移动设备上的运行速度提高了约3.2倍。我们的源码可在以下地址获得:https://github.com/apple/ml-cvnets
1 引言
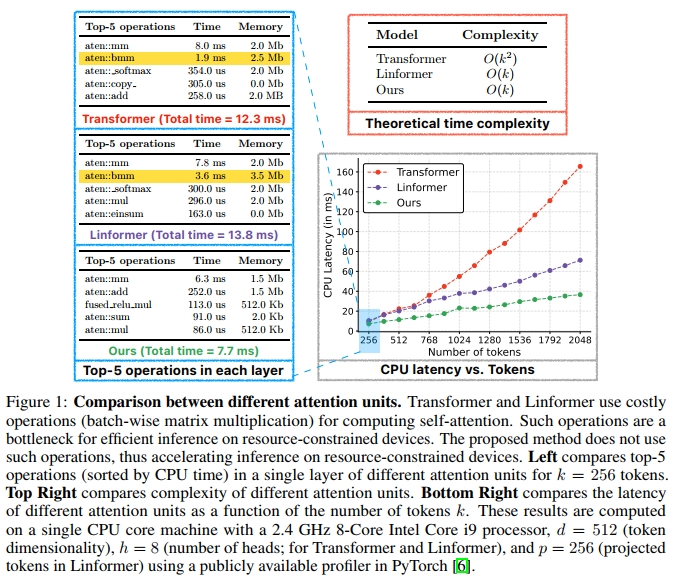
Vision transformers(ViTs)[1] 已广泛应用于各种视觉识别任务 [2, 3],包括移动视觉任务 [4]。在包括mobile vision transformers在内的ViT模型的核心,是transformer block [5]。ViT模型的主要效率瓶颈,尤其是在资源受限设备上的推理过程,是multi-headed self-attention(MHA)。MHA允许token(或patch)之间相互交互,是学习全局表示的关键。然而,transformer block中self-attention的复杂度为 O ( k 2 ) O(k^2) O(k2),即相对于token(或patch)数量k呈二次增长。除此之外,为计算MHA中的attention矩阵,还需要代价高昂的操作(例如,按batch的矩阵乘法;见图1)。这对于在资源受限设备上部署ViT模型尤其令人担忧,因为这些设备具有较低的计算能力、有限的内存约束和有限的电源预算。因此,本文试图回答以下问题:transformer block中的self-attention是否可以为资源受限设备进行优化?
已有多种方法(例如,[7–10])被提出用于优化transformer中的self-attention操作(并不特指用于ViTs)。其中,在序列建模任务中被广泛研究的一种方法是,在self-attention层中引入稀疏性,使得每个token仅关注输入序列中的一个子集 [7, 9]。尽管这些方法将时间复杂度从 O ( k 2 ) O(k^2) O(k2)降低到 O ( k p k ) O(kp_k) O(kpk)或 O ( k log k ) O(k \log k) O(klogk),但代价是性能下降。另一种流行的self-attention近似方法是使用低秩近似。Linformer [10]通过线性投影将self-attention操作分解为多个较小的self-attention操作,从而将其复杂度从 O ( k 2 ) O(k^2) O(k2)降低到 O ( k ) O(k) O(k)。然而,Linformer仍然使用代价高昂的操作(例如,按batch的矩阵乘法;见图1)来在MHA中学习全局表示,这可能会妨碍这些模型在资源受限设备上的部署。
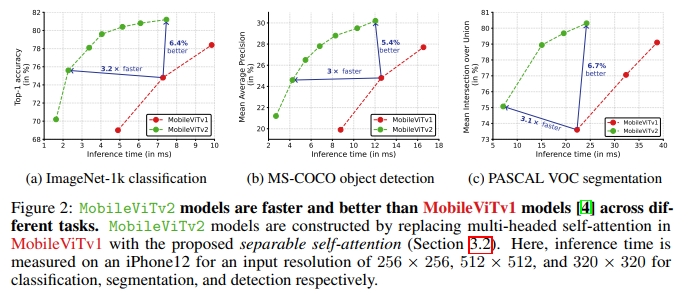
本文提出了一种新颖的方法——可分离self-attention,其计算复杂度为 O ( k ) O(k) O(k),用于解决transformer中MHA的瓶颈问题。为实现高效推理,该self-attention方法还将MHA中计算代价高昂的操作(例如,按batch的矩阵乘法)替换为逐元素操作(例如,加法和乘法)。在标准视觉数据集和任务上的实验结果展示了该方法的有效性(见图2)。
2 相关工作
提升self-attention效率 提高transformer中MHA效率是一个活跃的研究领域。第一类研究通过引入局部性来应对MHA中的计算瓶颈 [例如,7, 9, 11, 12]。这些方法并不对所有 k k k个token进行attention,而是使用预定义的模式将self-attention的感受野从所有 k k k个token限制为其子集,从而将时间复杂度从 O ( k 2 ) O(k^2) O(k2)降低为 O ( k k ) O ( k { \sqrt { k } } ) O(kk)或 O ( k log k ) O(k \log k) O(klogk)。然而,与transformer中标准MHA相比,这类方法在仅带来适度训练/推理加速的同时,会导致较大的性能下降。为了提升MHA的效率,第二类研究使用相似性度量对token进行分组 [8, 13, 14]。例如,Reformer [8]使用局部敏感哈希(locality-sensitive hashing)对token分组,将理论self-attention计算成本从 O ( k 2 ) O(k^2) O(k2)降低为 O ( k log k ) O(k \log k) O(klogk)。但该方法只有在序列较长( k > 2048 k > 2048 k>2048)时,效率提升才显著 [8]。由于在ViT中 k < 1024 k < 1024 k<1024,这些方法并不适用于ViT。第三类研究则通过低秩近似来提升MHA的效率 [10, 15]。其主要思想是用低秩矩阵近似self-attention矩阵,将计算成本从 O ( k 2 ) O(k^2) O(k2)降低到 O ( k ) O(k) O(k)。尽管这些方法显著加快了self-attention的计算,但仍然依赖计算代价高昂的操作来计算attention,这可能会阻碍其在资源受限设备上的部署(见图1)。
综上所述,现有提高MHA效率的方法在推理时间和内存消耗的降低方面存在局限,尤其是在资源受限设备上。本文提出了一种快速且内存高效的可分离self-attention方法(见图1),这对资源受限设备来说是理想的选择。
提升基于transformer的模型 有大量工作致力于提升transformer模型的效率 [3, 4, 16–18]。其中多数方法通过下采样 [19, 18] 和金字塔结构 [3, 20, 4] 等手段减少transformer block中的token数量。由于我们提出的可分离self-attention模块可以直接替换MHA,因此它能够轻松集成到任意基于transformer的模型中,从而进一步提升效率。
其他方法 transformer模型的性能还可以通过其他方法提升,例如混合精度训练 [21]、高效优化器 [22, 23] 和知识蒸馏 [2]。这些方法与本文方法正交,在默认情况下我们采用混合精度进行训练。
3 MobileViTv2
MobileViT [4] 是一种结合CNN和ViT优势的混合网络。MobileViT将transformer视为卷积操作,使其能够同时利用卷积的先验偏置(例如归纳偏置)和transformer对长距离依赖建模的能力,从而构建适用于移动设备的轻量网络。尽管MobileViT网络参数显著少于轻量CNN(如MobileNets [24, 25]),并能取得更好的性能,但其延迟较高。MobileViT中的主要效率瓶颈在于multi-headed self-attention(MHA,见图3a)。
MHA使用scaled dot-product attention来捕获 k k k个token(或patch)之间的上下文关系。然而,MHA计算成本高,其时间复杂度为 O ( k 2 ) O(k^2) O(k2)。这种二次成本在token数量 k k k较大时成为transformer的瓶颈(见图1)。此外,MHA使用计算和内存密集型的操作(例如用于计算attention矩阵的按batch矩阵乘法与softmax;见图1),这在资源受限设备上也可能成为瓶颈。为了解决MHA在资源受限设备高效推理方面的局限性,本文提出了复杂度为线性的可分离self-attention(见图3c)。
我们提出的可分离self-attention方法的核心思想如图4b所示,是相对于一个潜在token L L L来计算context score。这些分数用于对输入token进行加权,以生成一个上下文向量,从而编码全局信息。由于self-attention是相对于一个潜在token进行的,该方法将transformer中self-attention的复杂度降低了一个 k k k的因子。该方法的一大特点在于其使用逐元素操作(例如加法与乘法)进行实现,使其成为资源受限设备的理想选择。我们之所以称该方法为“可分离self-attention”,是因为它允许我们通过两次线性计算来替代二次复杂度的MHA,从而实现对全局信息的编码。改进后的模型MobileViTv2即通过将MobileViT中的MHA替换为可分离self-attention而得。
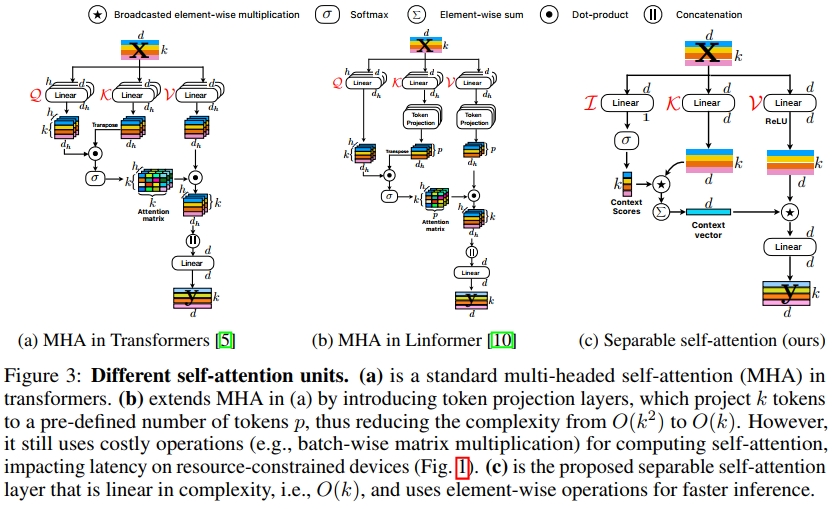
本节其余部分将首先简要介绍MHA(第3.1节),随后详细阐述可分离self-attention方法(第3.2节)以及MobileViTv2架构(第3.3节)。
3.1 多头自注意力概述
MHA(图 Ba)使得 transformer能够编码token之间的关系。具体来说,MHA 接收一个输入 x ∈ R k × d x \in \mathbb{R}^{k \times d} x∈Rk×d,该输入包含 k k k个 d d d-维的token(或补丁)嵌入。输入 x x x随后被送入三个分支,即查询 Q Q Q、键 K K K和值 V V V。每个分支(( Q 、 K 、 K 、K和 V V V)都包含
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











