








一、论文信息
论文题目:CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
中文题目:CAS-ViT:用于高效移动应用的卷积加法自注意力视觉Transformer
论文链接:https://arxiv.org/pdf/2408.03703?
官方github:https://github.com/Tianfang-Zhang/CAS-ViT
所属机构:商汤科技研究院,清华大学自动化系,华盛顿大学电气与计算机工程系,哥本哈根大学计算机科学系
核心速览:本文介绍了一种名为CAS-ViT(Convolutional Additive Self-attention Vision Transformers)的新型视觉Transformer,旨在移动应用中实现效率与性能之间的平衡。
二、论文概要
Highlight
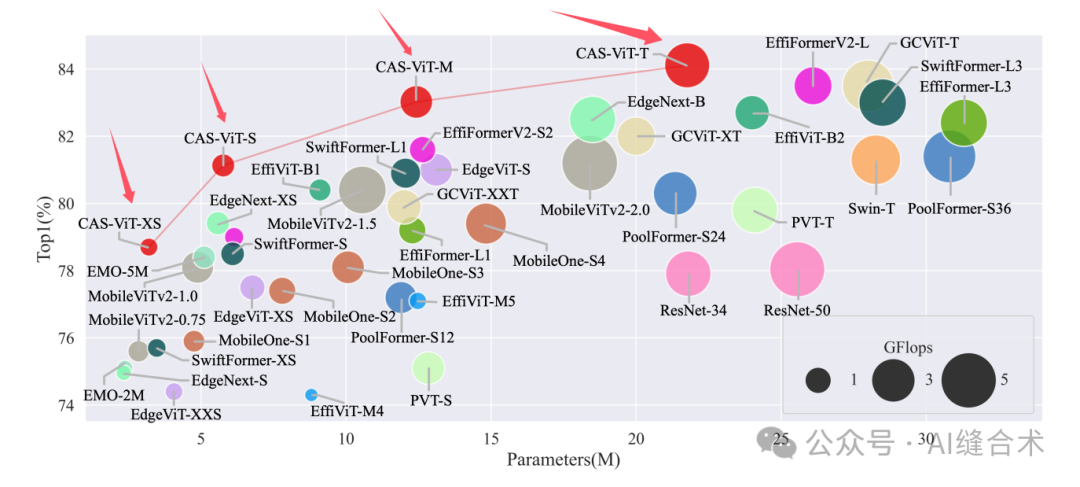
图1. ImageNet-1K上的参数与Top-1准确率对比。圆圈大小表示Gflops,最好以彩色查看。
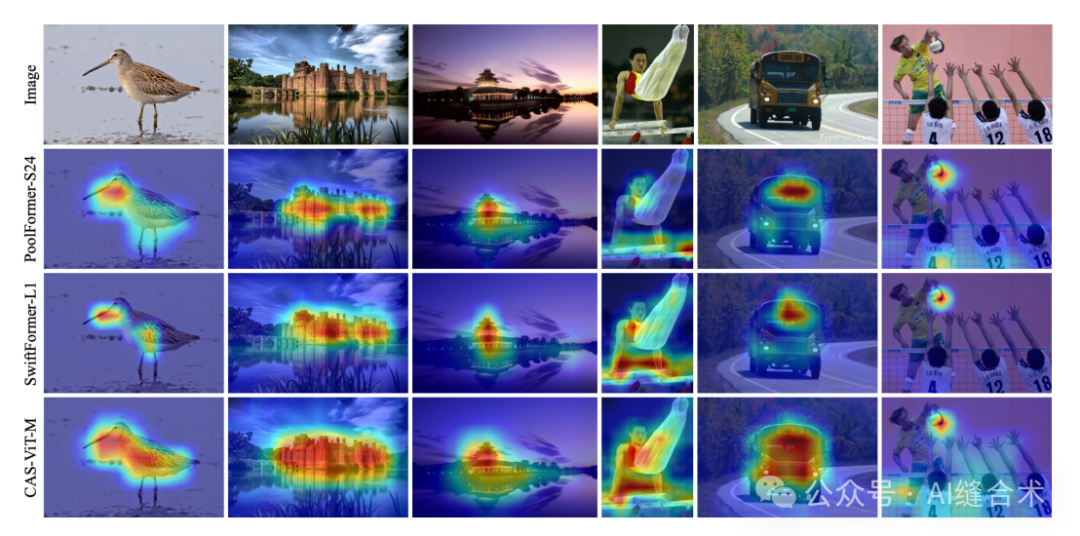
图4. 背部最后一层的热图可视化。从上到下依次是原始图像、PoolFormer-S24、SwiftFormer-L1 和CAS-ViT-M。我们的模型准确捕捉了全局上下文,并且相比于其他SOTA(State Of The Art)模型,实现了更大的感受野,这对于密集预测任务是有益的。

图5. 在COCO 2017上对目标检测和实例分割结果的可视化。上图:PoolFormer-S12 的预测结果,下图:CAS-ViT-M的预测结果。我们的方法能够准确地检测和分割实例。
1. 研究背景:
-
研究问题:尽管视觉变换器(ViTs)在捕获长距离依赖、全局建模和表示方面具有优势,但其成对的标记亲和性和复杂的矩阵操作限制了其在资源受限场景和实时应用中的部署,如移动设备。如何设计一种既能在移动设备上高效运行又能保持高性能的视觉变换器模型,是当前研究的热点问题。
-
研究难点:ViT模型中的多头自注意力(MSA)机制具有二次复杂度,导致计算效率低下,难以满足应用需求。此外,ViT中的复杂矩阵乘法和Softmax操作在部署到边缘设备时会遇到操作不支持和模型转换失败的问题。因此,开发一种结合了高效部署和强大性能的标记混合器,如混合模型,已成为移动设备上的迫切问题。
-
文献综述:为了改进标记混合器,研究者们尝试了多种方法,包括MSA的改进和异构MSA(H-MSA)。MSA的改进侧重于在自注意力机制下增强捕获长距离依赖的能力,同时降低算法复杂性。H-MSA是一种进化变体,打破了Q和K矩阵乘法的限制,以探索更灵活的网络设计。尽管最近的研究取得了一定进展,但仍然存在效率和准确性之间难以取得满意平衡的问题。
2. 本文贡献:
-
CAS-ViT网络架构:提出了一种名为CAS-ViT的卷积加法自注意力网络,旨在移动应用中实现效率与性能之间的平衡。该网络通过引入卷积加法令牌混合器(CATM)和卷积加法自注意力(CAS)块,简化了复杂的矩阵运算,如矩阵乘法和Softmax,从而提高了效率。
-
令牌混合器设计:CATM模块通过空间和通道注意力实现信息交互,消除了复杂的矩阵运算。该模块采用Sigmoid激活的加法相似性函数,实现了自注意力的卷积替代。
-
轻量级网络构建:构建了一系列轻量级网络模型,这些模型可以轻松扩展到各种下游任务。这些模型在ImageNet-1K数据集上进行了评估,取得了优异的性能。
-
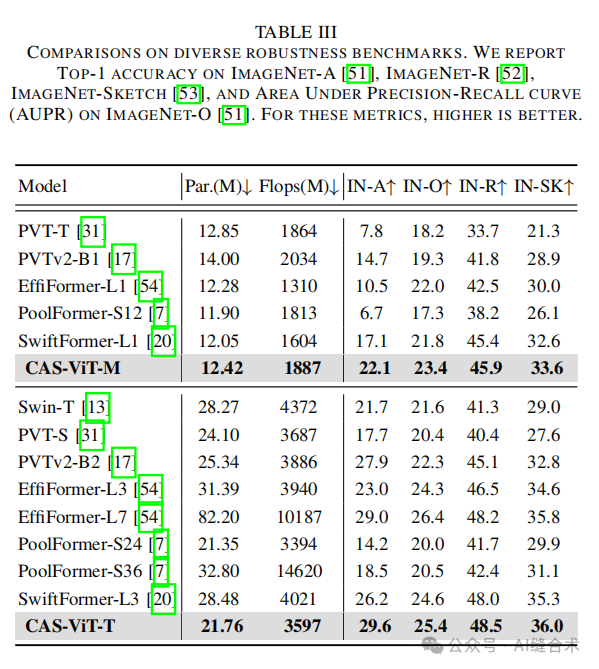
实验结果:CAS-ViT模型在多个视觉任务上取得了优异的性能,包括图像分类、对象检测、实例分割和语义分割。在ImageNet-1K数据集上,CAS-ViT模型的M和T模型分别以12M和21M参数取得了83.0%/84.1%的top-1准确率。
三、方法
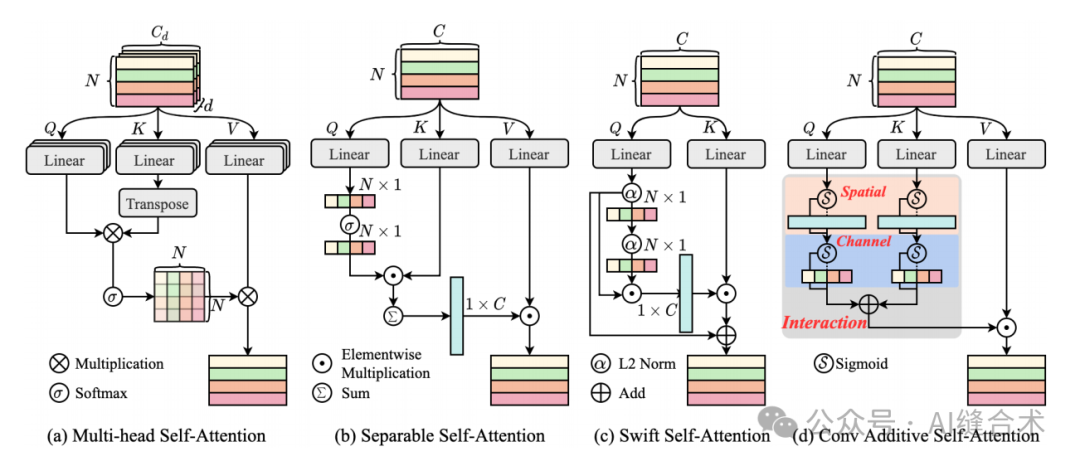
图2. 不同自注意力机制的比较。(a) 是ViT 中的经典多头自注意力。(b) 是MobileViTv2 中的可分离自注意力,它将矩阵的特征度量降低到一个向量。(c) 是SwiftFormer 中的快速自注意力,仅使用Q和K实现高效的特征关联。(d) 提出的卷积加性自注意力。
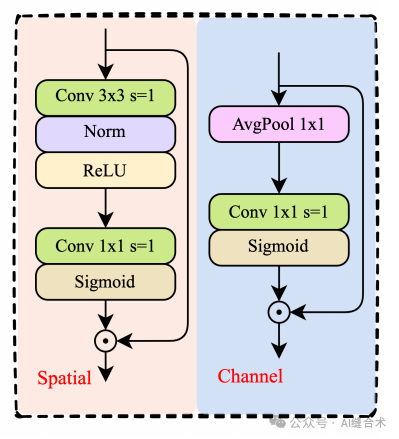
CASAtt模块结合了空间注意力和通道注意力机制来增强特征表达。该模块的核心思想是通过空间操作和通道操作分别对查询(Q)和键(K)进行增强,最终生成注意力加权的特征输出。其主要流程如下:
1. Q、K、V的计算:首先,通过一个1x1卷积将输入特征图x映射为查询(Q)、键(K)和值(V),这三个张量被分割成相应的维度。
2. 空间注意力:该操作首先通过一个深度可分离卷积(depthwise convolution)提取空间信息,接着通过BatchNorm和ReLU激活,最后通过1x1卷积生成空间注意力权重,并通过Sigmoid激活得到一个0到1之间的权重值,用于加权输入特征图。
3. 通道注意力:该操作通过全局平均池化(AdaptiveAvgPool2d)聚合通道信息,然后通过1x1卷积生成通道注意力权重,同样使用Sigmoid激活生成最终的权重值。
4. 注意力操作:空间操作和通道操作分别作用在Q和K上,经过加权得到新的Q和K。然后,通过深度可分离卷积(dwconv)对加权后的Q和K进行处理,得到融合后的特征图。
5. 融合与输出:最后,将加权后的V和Q、K的融合结果进行卷积和dropout操作得到最终的输出。
四、实验分析
1. 图像分类——ImageNet-1K: CAS-ViT模型在ImageNet-1K数据集上取得了优异的分类性能。具体来说,M和T模型分别达到了82.8%/83.0%和83.9%/84.1%的top-1准确率,且参数量分别为12M和21M。这些结果表明CAS-ViT在保持高准确率的同时,参数量和计算复杂度较低,非常适合移动设备部署。
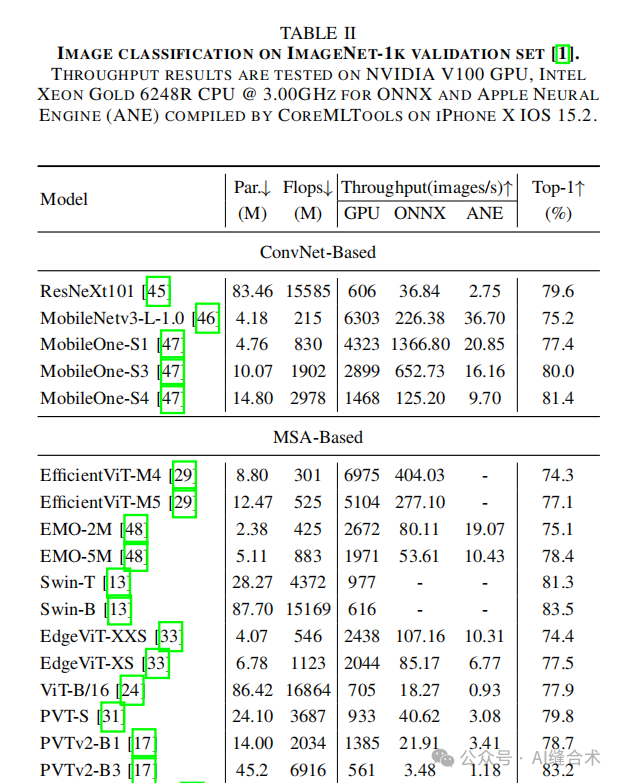
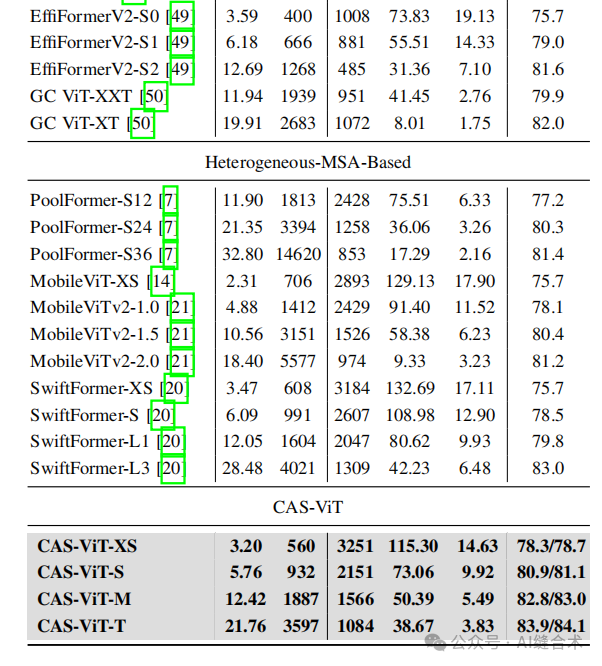
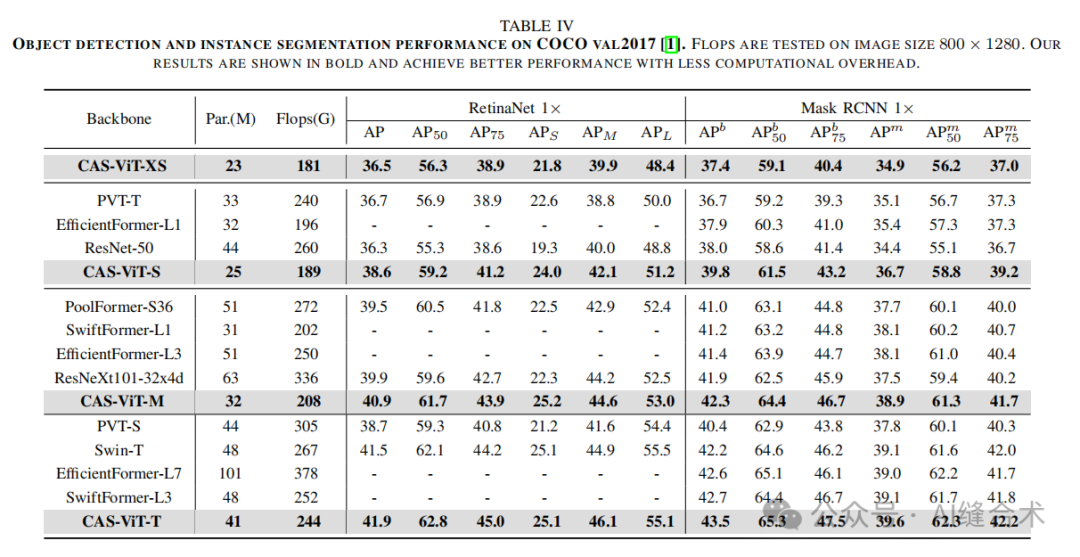
2. 目标检测和实例分割——COCO val 2017: 在COCO数据集上,CAS-ViT模型同样表现出色。例如,T模型在使用Mask RCNN时,AP box和AP mask分别达到了43.5和39.6,超过了其他一些模型,如Swin-T和EfficientFormer-L1,且参数量更少。
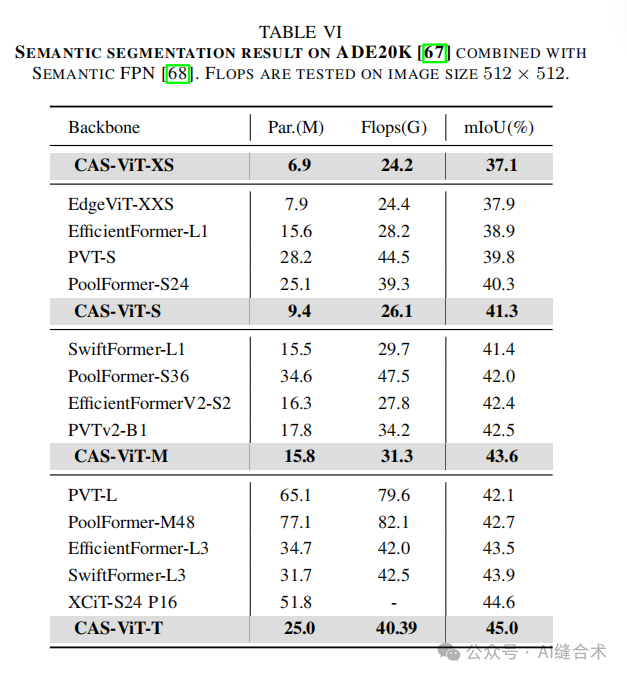
3. 语义分割——ADE 20K: 在ADE 20K数据集上,CAS-ViT模型同样展现了良好的性能。M和T模型在使用Semantic FPN时,mIoU分别达到了45.0%和43.6%,优于其他一些模型,如PVT和EfficientFormer等,且参数量更少。
五、代码
https://github.com/AIFengheshu/Plug-play-modules
2025年全网最全即插即用模块,全部免费!适用于图像分类、目标检测、实例分割、语义分割、单目标跟踪(SOT)、多目标跟踪(MOT)、RGBT、图像去噪、去雨、去雾、去模糊、超分等计算机视觉(CV)和图像处理任务,持续更新中......
欢迎转发、点赞、收藏~


















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











