







作者及发刊详情
@article{wang2021spatten,
title={SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning},
author={Wang, Hanrui and Zhang, Zhekai and Han, Song},
journal={HPCA},
year={2021}
}
摘要
正文
主要工作贡献
1)Cascade Token Pruning根据累计的token重要性score移除了不重要的token计算
减少了DRAM访问和计算
2)Cascade Head Pruning移除了不重要的head
减少了DRAM访问和计算
3)Progressive Quantization用小部分增加的计算换取较小的memory访问
基于attention可能性分布,改变了不同head和layer的位宽,减少了DRAM访问
4)专用的高并行top-k引擎有效支持on-the-fly的token和head选择,获得了O(n)时间复杂度
即时的token和head选择
实验评估
实验验证平台:SpinalHDL+Verilator
通过SpinalHDL编写并编译成RTL,通过Verilator进行仿真
HBM采用Ramulator模型[15]
选用模型: BERT 和 GPT-2
包括BERT-Base和 BERT-Large,以及 GPT-2-Small 和GPT-2-Medium
测试集
包括GLUE set [4], SQuAD [8], Wikitext-2 [9], Wikitext-103 [9], Pen Tree Bank [10] 和Google One-Billion Word [11] 在内的30个benchmark
PPA表现
在没有精度损失下减少了10倍的DRAM访问
获得了计算加速和能量节约。
与其他ASIC对比
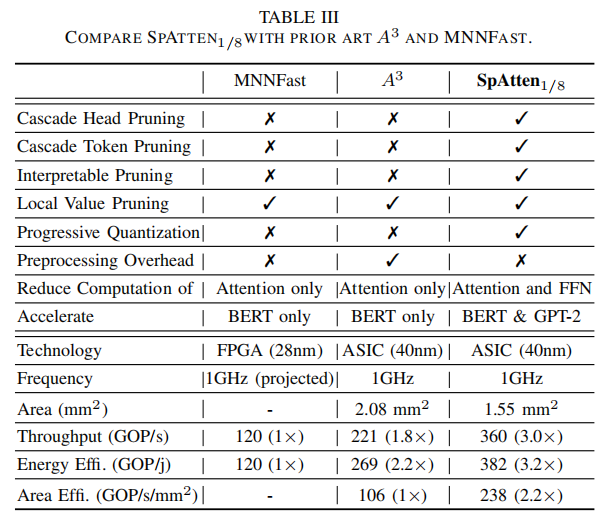
设计思想
通过级联token剪枝、级联head剪枝以及量化减少计算和存储访问。
剪枝与传统方法不同,用于token和head,而不是weights;级联是指一旦一个token或者head被剪掉了,其会在后续所有层中被除去,所以一层只需要处理以前层中余下的tokens和heads。
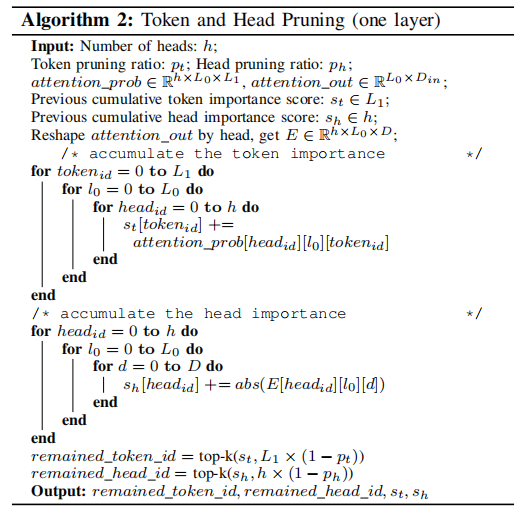
Token和Head的级连剪枝
- 人类语言中有很多结构性的无异于的token,比如介词、副词等,这些是不重要的,对结果影响较小。
- attention使用很多head来抓取依赖,但部分是冗余的,可以被剪枝掉
通过attention_prob和attention_out计算head和token的重要性值:
局部V值剪枝
根据当前atterntion_prob的值,如果该值较小则修剪,softmax与V将不在计算
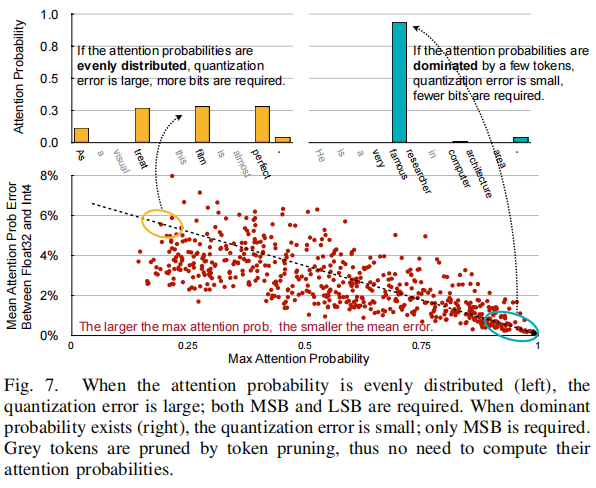
渐进量化
公式验证表明当attention_prob值满足
0
<
=
P
<
=
1
,
2
P
(
1
−
P
)
<
0.5
0<=P<=1, 2P(1-P)<0.5
0<=P<=1,2P(1−P)<0.5,softmax后的整体量化误差会减小。
开始时采用最积极的量化策略,即只采用MSB计算,当计算后attention_prob分布被几个token占据,量化误差就很小;如果比较平坦,误差就大,将计入LSB重新计算attention_prob。
硬件设计
top-k根据token的重要性score排序获取最终的k值Ks,数据获取器计算Ks的地址并将其填充到32x16的crossbar中,两个crossbar连接着16通道的HBM,再通过一个反向的16x32的crossbar获取数据;Q和K通过一个举证向量乘模块计算,获取attention_score,随后通过softmax模块计算attention_prob,然后将结果发送到渐进量化模块,判断LSB是否需要;局部Value 剪枝的TopK引擎获取attention_prob并计算局部最重要的Vs,并将其编号发送到数据获取器;最终幸存的attention_prob乘以V,得到attention输出,
在计算完一个head后,head重要性score将会被累计,完成一层所有的head计算后,top-k模块将会剪去不重要的head,这些head在后续的层中不被计算。
在识别阶段,在cascade token剪枝中幸存下来的K和V将被传输到SRAM,并将在多个Q中重用。
在生成阶段,Q是一个单一向量,不存在KV的复用,无需再片上SRAM中存储。
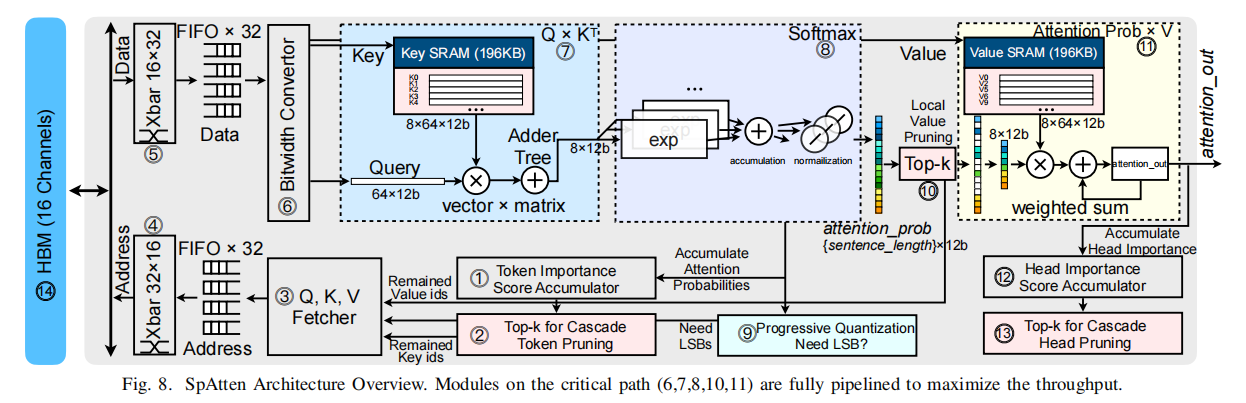
关键路径6、7、8、10、11是全流水化的;
模块3中QKV三个分支需要同步,fetcher处理请求并把地址发送给FIFO
对于渐进量化模块9,如果LSB需要,将放弃当前attention_prob并重新计算,此时模块10和11将处于空闲状态,等待重新计算attention_prob 。
top-k引擎
支持token/head剪枝以及局部V值剪枝,需要找到阵列中top的k个要素
随机选择一个中枢将输入整列划分成2部分:比中枢大的部分和小的部分,并储存在两个FIFO中。
左右比较器整列分别保存比pivot小和大的元素,其他的将被置为零或者被零消除器(Zero Eliminator)消除为零。
快速选择器(Quick Select)将会迭代运行,知道找到第k个最大的元素。
第k个最大元素用于过滤输入阵列,过滤掉的阵列将被缓存到另一个FIFO中。
过滤掉的输出将被另一个零消除器处理从而或则最终的top-k元素,其可以很容易地用更多的比较器进行扩展。每个阵列中使用16个比较器从而使该模块不会成为整个流水线的瓶颈。
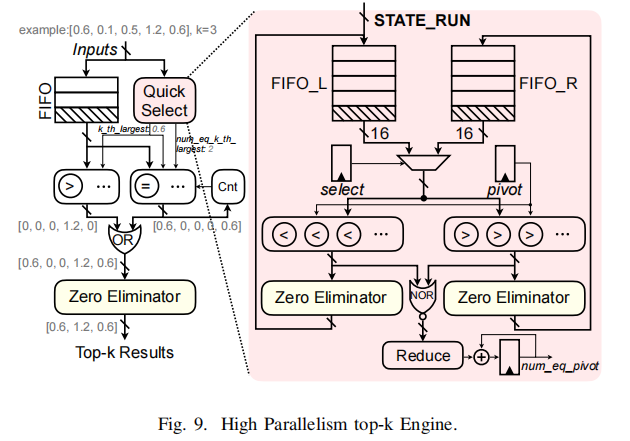
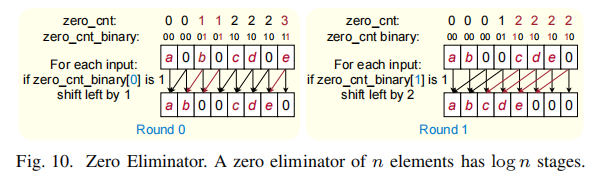
Zero Eliminator
Crossbar和Data Fetcher
剪枝将会导致随机的memory访问,crossbar处理地址,保持访存通道busy,增加带宽的使用率。
QKV数据获取器用于将多个read请求发送到所有的16个HBM通道,这些QKV数据在不同的通道中是交错的,通过32-16 crossbar来路由这些读请求到正确的通道上。
bitwidth converter
为了支持渐进量化,通过位宽转换器实现MSB和LSB的分离与聚合。
将DRAM来的4、8、12bit数据统一转换乘12bit,转换器包含很多MUX模块来选择输入数据正确的bit,以及一个位移器允许从非对齐的地址读取数据。
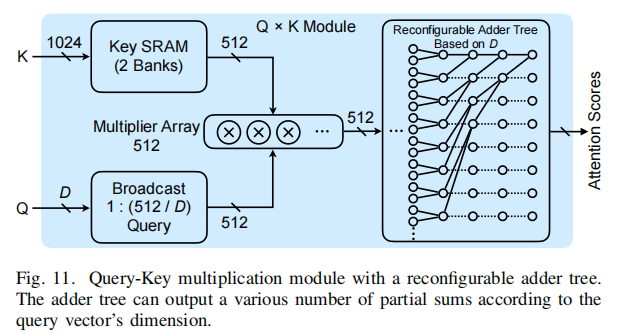
QK乘模块
计算QK的矩阵乘
每个周期,K矩阵的一行从K SRAM中加载出来通过一个乘法阵列乘以Q,后填充到加法树中。
加法树通过减少所有乘的记过来计算Attention Score。
本设计采用512个乘法器来充分使用DRAM带宽。
为了支持维度D低于512的QK计算,在每个周期获得512/D个attention score。
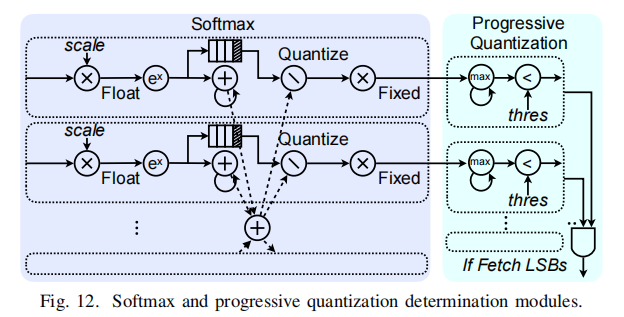
softmax和渐进量化模块
从乘模块输出的attention score定点数据需要先通过一个缩放因子(scaling factor)解量化。该因子包括了标准化因子
D
\sqrt{D}
D的计算。
在softmax计算后将重新量化输入到渐进量化模块,判断LSB是否需要。
两个SRAM
地址FIFO:32个64深度的8B
数据FIFO:32个64深度的16B
参考文献
[15] Y. Kim et al., “Ramulator: A fast and extensible dram simulator,” IEEE Computer architecture letters, 2015.
评
提出了一个算法和硬件架构协同设计的加速器,将算法的优化用硬件实现,加速了Attention的计算,减少了DRAM的访问,但不加速FC层,全连接层仍由GPU、CPU或tensor代数加速器计算
该项目已开源,采用chisal语言编写
Github开源链接


















 9205
9205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











