







FPGA中一种乘加运算的资源优化写法注意事项
最近在FPGA里面做小波变换提升算法,由于是多条流水线进行,里面会多次用到乘加的运算结构,最后导致工程占用资源刚刚不够用(105%),很是苦闷,在此记录一下资源优化的一种案例(quartus ii 17.1)。
这是原始算法中的一次分解步骤(中间拎出来的,可能没有实际意义,只适用于分析结构与资源):
demo0:
//临时测试:demo0
module test(
input clk50M,
input [2:0] cnt_rbio,
input signed [15:0] ram1_rbio_s16,
input signed [15:0] ram2,
output reg signed [15:0] out
);
localparam signed MULTI_N1D12_P = 17'b00000101010101011; //1/12
localparam signed MULTI_N1D12_N = 17'b11111010101010101; //-1/12
localparam signed MULTI_N4D9_P = 17'b00011100011100011; //4/9
reg signed [31:0] data32_mid3;
wire signed [15:0] data16_mid3;
reg signed [15:0] ram2_rbio_s16[2:0];
reg signed [15:0] ram3_rbio_s16[2:0];
always@(posedge clk50M) begin
ram2_rbio_s16[0] <= ram2;
ram2_rbio_s16[1] <= ram2_rbio_s16[0];
ram2_rbio_s16[2] <= ram2_rbio_s16[1];
end
always @(*) begin
if(cnt_rbio == 1)
data32_mid3 = ram2_rbio_s16[0]*MULTI_N1D12_N + ram2_rbio_s16[1]*MULTI_N4D9_P + ram2_rbio_s16[1]*MULTI_N1D12_P ; // 延拓: C(1)代替C(-1)
else if(cnt_rbio <= 3)
data32_mid3 = ram2_rbio_s16[1]*MULTI_N1D12_N + ram2_rbio_s16[1]*MULTI_N4D9_P + ram2_rbio_s16[2]*MULTI_N1D12_P ; // 延拓: C(2047)代替C(2049)
else
data32_mid3 = ram2_rbio_s16[0]*MULTI_N1D12_N + ram2_rbio_s16[1]*MULTI_N4D9_P + ram2_rbio_s16[2]*MULTI_N1D12_P ;
end
assign data16_mid3 = data32_mid3[30:15];
always @(posedge clk50M) begin
if(cnt_rbio>0 ) begin
if(cnt_rbio[0]) begin
if(cnt_rbio> 1 && cnt_rbio < 3)
ram3_rbio_s16[0] <=ram1_rbio_s16+ data16_mid3;
else
ram3_rbio_s16[0] <= 16'd0;
ram3_rbio_s16[1] <= ram3_rbio_s16[0];
ram3_rbio_s16[2] <= ram3_rbio_s16[1];
end
else begin
ram3_rbio_s16[0] <= ram3_rbio_s16[0];
ram3_rbio_s16[1] <= ram3_rbio_s16[1];
ram3_rbio_s16[2] <= ram3_rbio_s16[2];
end
end
else begin
ram3_rbio_s16[0] <= 15'd0;
ram3_rbio_s16[1] <= 15'd0;
ram3_rbio_s16[2] <= 15'd0;
end
end
always@(posedge clk50M)
out <= ram3_rbio_s16[2];
endmodule
大致结构就是,always @()内的组合逻辑对上一条流水线的中间输出进行1617的有符号乘、加运算,然后赋值到本次流水线的寄存器。
上述代码可以明显看到消耗资源的大头就是在always@(*)块内,
always @(*) begin
if(cnt_rbio == 1)
data32_mid3 = ram2_rbio_s16[0]*MULTI_N1D12_N + ram2_rbio_s16[1]*MULTI_N4D9_P + ram2_rbio_s16[1]*MULTI_N1D12_P ; // 延拓: C(1)代替C(-1)
else if(cnt_rbio <= 3)
data32_mid3 = ram2_rbio_s16[1]*MULTI_N1D12_N + ram2_rbio_s16[1]*MULTI_N4D9_P + ram2_rbio_s16[2]*MULTI_N1D12_P ; // 延拓: C(2047)代替C(2049)
else
data32_mid3 = ram2_rbio_s16[0]*MULTI_N1D12_N + ram2_rbio_s16[1]*MULTI_N4D9_P + ram2_rbio_s16[2]*MULTI_N1D12_P ;
end
乍一看,9个乘法、6个加法,实际上里面有些相同的组分,如第一列第一个if下的 ram2_rbio_s16[0]*MULTI_N1D12_N 与第三个else下的 ram2_rbio_s16[0]*MULTI_N1D12_N 是相同的,第二列三个都是相同的,第三列下的后两个也是相同的。这种相同的成分还是能够被编译器识别到的,并优化成一个结构然后再加一个类似MUX的东西,从而节约资源,优化后应该是5个乘法。
还有个问题,上述这种乘法结构,被乘数是用localparameter定义的常量,会比两个纯变量的乘法节约资源吗?答案是,会一点点,最终会被当成两个纯变量乘法,常量的位宽会被优化少几位。
最后综合后资源情况:
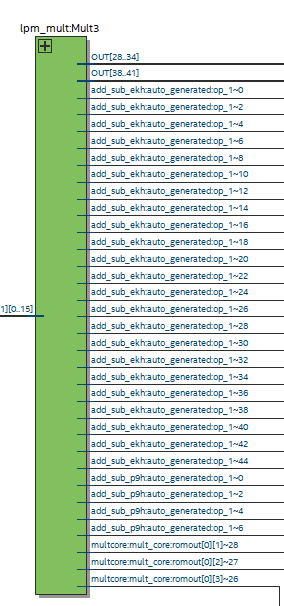
这是一个乘法
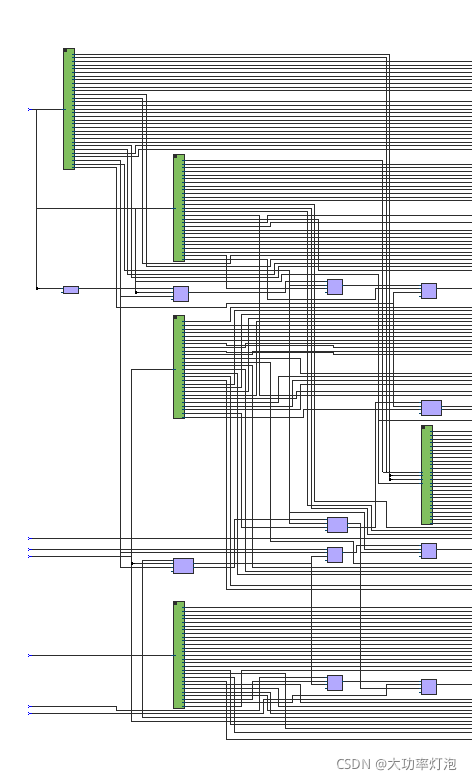
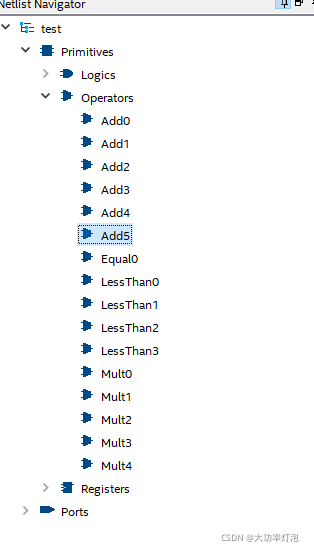

总的乘法数量:5
以及资源占用情况:695 LE
这说明,如果上述被乘数、乘数不重复的话,真的会生成9个multi!既然是相同的a0b0+a1b1+a2*b2的结构,为什么不只生成一个结构,分情况给乘数和被乘数赋不同值就行了?
既然quartus ii软件不优化,那就手动优化:
demo2:只改动乘加部分
//临时测试:demo1
module test(
input clk50M,
input [2:0] cnt_rbio,
input signed [15:0] ram1_rbio_s16,
input signed [15:0] ram2,
output reg signed [15:0] out
);
localparam signed MULTI_N1D12_P = 17'b00000101010101011; //1/12
localparam signed MULTI_N1D12_N = 17'b11111010101010101; //-1/12
localparam signed MULTI_N4D9_P = 17'b00011100011100011; //4/9
wire signed [31:0] data32_mid3;
wire signed [15:0] data16_mid3;
reg signed [15:0] ram2_rbio_s16[2:0];
reg signed [15:0] ram3_rbio_s16[2:0];
reg signed [15:0] a0,a1,a2;
always@(posedge clk50M) begin
ram2_rbio_s16[0] <= ram2;
ram2_rbio_s16[1] <= ram2_rbio_s16[0];
ram2_rbio_s16[2] <= ram2_rbio_s16[1];
end
assign data32_mid3 = a0*MULTI_N1D12_N + a1*MULTI_N4D9_P + a2*MULTI_N1D12_P;
always@(*) begin
if(cnt_rbio == 1) begin
a0 = ram2_rbio_s16[0];
a1 = ram2_rbio_s16[1];
a2 = ram2_rbio_s16[1];
end
else if(cnt_rbio <= 3) begin
a0 = ram2_rbio_s16[1];
a1 = ram2_rbio_s16[1];
a2 = ram2_rbio_s16[2];
end
else begin
a0 = ram2_rbio_s16[0];
a1 = ram2_rbio_s16[1];
a2 = ram2_rbio_s16[2];
end
end
assign data16_mid3 = data32_mid3[30:15];
always @(posedge clk50M) begin
if(cnt_rbio>0 ) begin
if(cnt_rbio[0]) begin
if(cnt_rbio> 1 && cnt_rbio < 3)
ram3_rbio_s16[0] <=ram1_rbio_s16+ data16_mid3;
else
ram3_rbio_s16[0] <= 16'd0;
ram3_rbio_s16[1] <= ram3_rbio_s16[0];
ram3_rbio_s16[2] <= ram3_rbio_s16[1];
end
else begin
ram3_rbio_s16[0] <= ram3_rbio_s16[0];
ram3_rbio_s16[1] <= ram3_rbio_s16[1];
ram3_rbio_s16[2] <= ram3_rbio_s16[2];
end
end
else begin
ram3_rbio_s16[0] <= 15'd0;
ram3_rbio_s16[1] <= 15'd0;
ram3_rbio_s16[2] <= 15'd0;
end
end
always@(posedge clk50M)
out <= ram3_rbio_s16[2];
endmodule
最后综合情况:
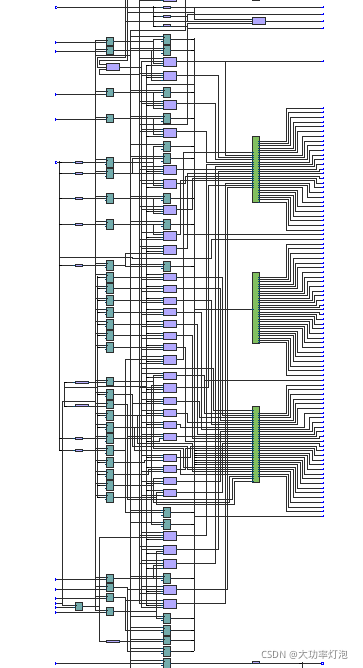
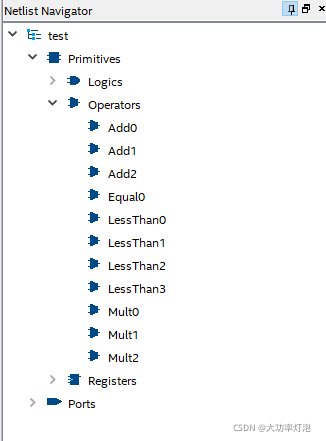
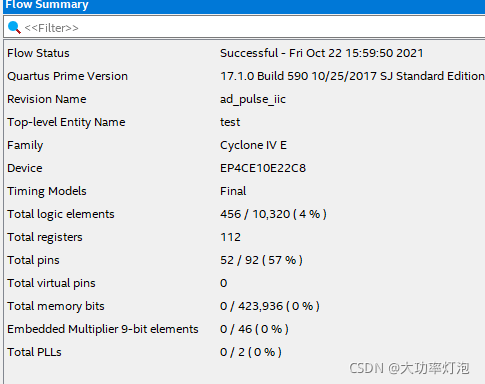














 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









