







CAN
Context-Aware Crowd Counting
CVPR 2019
洛桑联邦理工学院
论文:https://arxiv.org/pdf/1811.10452.pdf
代码:https://github.com/weizheliu/Context-Aware-Crowd-Counting
Instruction
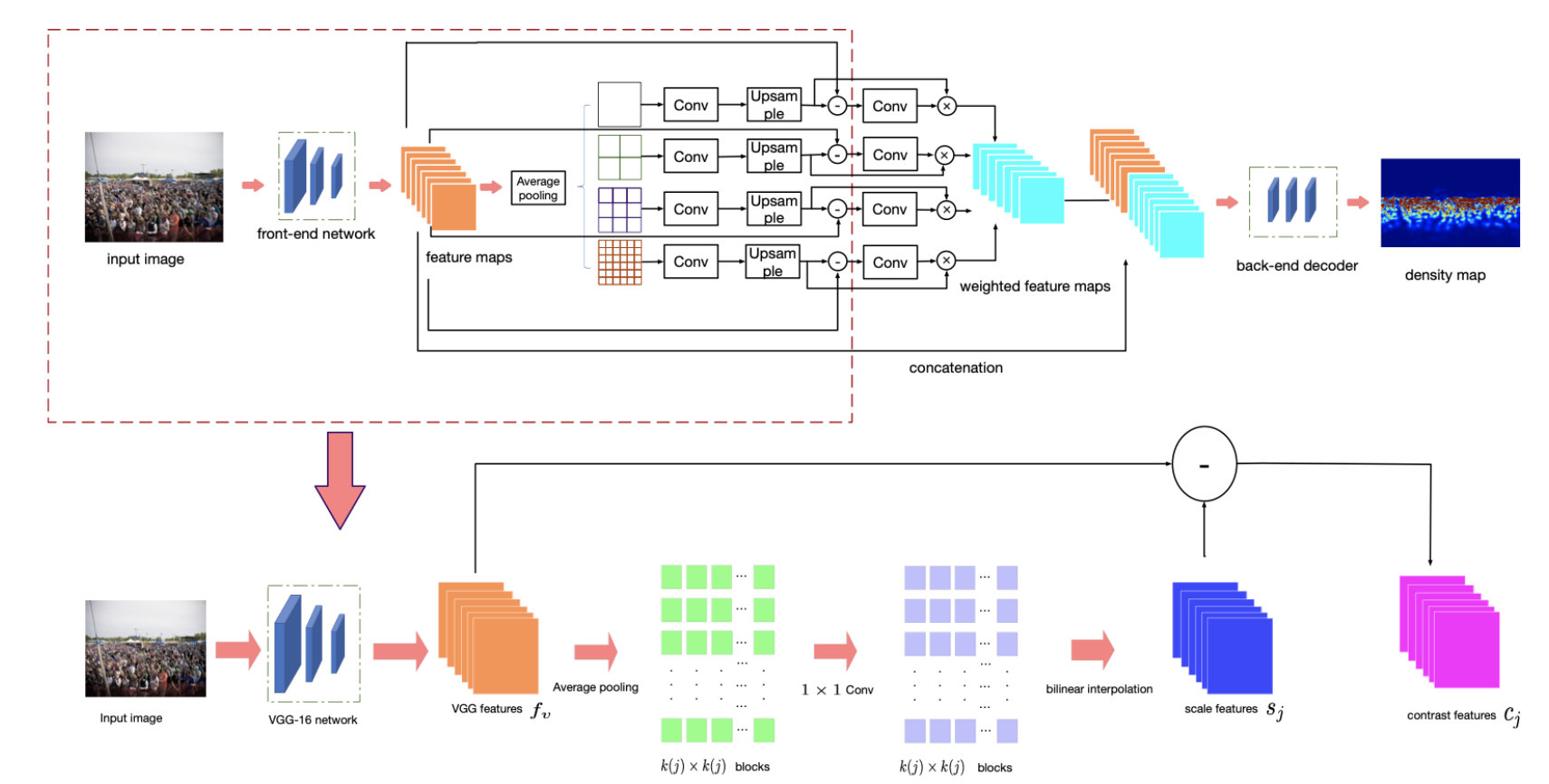
作者提出了一种end2end的网络,它可以在多个感受野(尺度)下进行特征提取,并且学习图像中的重要特征,从而解决快速尺度变化问题。
这篇文章是直接将多尺度的上下文信息整合到这个end2end的网络中,使其在每个图像位置能够利用到正确的上下文。
Scale-Aware Contextual Features
这些带有尺度信息和上下文信息的featrue map是怎么得到的呢?
网络的前10层用的是预训练好的VGG16的前10层,输出的特征图为

F v g g \mathcal{F}_{vgg} Fvgg的局限性在于它在整个图像上编码相同的感受野。为了解决这个问题,作者通过执行Spatial Pyramid Pooling从VGG特征中提取多尺度上下文信息来计算scale-aware特征。

s j s_j sj:最终得到的featrue map
j j j:尺度
θ \theta θ:网络参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7840
7840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









