







Xilinx 7系列FPGA中CLB结构和内部资源使用
7系列FPGA内部资源更加的更富,性能更强悍,最吸引人的就是28nm工艺使得相同的逻辑资源功耗降低50%,这是一个很大的提升,在单板硬件上仅仅降低50%的功耗就能避免一大部分的问题。7系列逻辑资源和之前系列是一致的都是采用ASML架构,主要分为可编程逻辑资源、可编程I/O资源和布线资源这三大部分。
1、 CLB可配置逻辑资源
CLB可以说是FPGA最基本的一个模块,常用的查找表、选择器、触发器、进位链都是属于CLB的内部资源。一个CLB包含两个SLICE组成。每个Slice 包含查找表、寄存器、进位链和多个多数选择器构成。CLB分为CLBL和CLBM两类,每个SLICE都包含4个6输入LUT、3个数据选择器、一个进位链和8个触发器。SLICE内部资源如下图所示:
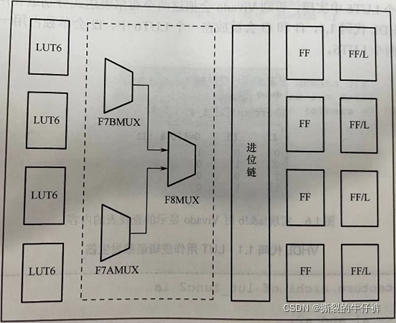
1、LUT
LUT功能如下图
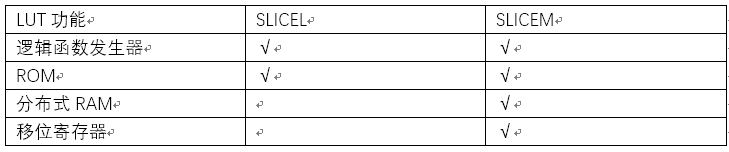
LUT在用在函数发生器时就是实现布尔运算,本质上就是一个RAM。它把数据事先写入RAM后,每当输入一个信号就等于输入一个地址进行查表,找出地址对应的内容,然后输出。
因此LUT在用在函数发生器时可以等价位:输入的信号 ==> 输入的地址 ==> 输出结果
这样的一个映射过程。
LUT用作ROM时每个SLICEL的6输入LUT可配置成64×1的ROM。
在SLICEM中LUT可以配置成RAM,这个RAM写操作为同步,读操作为异步,与时钟信号无关,如果配置成同步读写的话需要提供额外的触发器。SLICEM里面的LUT跟SLICEL里面的LUT相比多了DI2,WA[6:1],CLK,WE这几个端口。做RAM用的时候,其中DI1,DI2是写数据输入端口,O5,O6同样是数据输出端口,支持一次性两bit或者单bit读写。A[6:1]为读地址,WA[6:1]为写地址,WE为写使用,CLK为时钟端口。
RAM32X1D_1 #(
.INIT(32'h00000000), // Initial contents of RAM
.IS_WCLK_INVERTED(1'b0) // Specifies active high/low WCLK
) RAM32X1D_1_inst (
.DPO(DPO), // Read-only 1-bit data output
.SPO(SPO), // Rw/ 1-bit data output
.A0(A0), // Rw/ address[0] input bit
.A1(A1), // Rw/ address[1] input bit
.A2(A2), // Rw/ address[2] input bit
.A3(A3), // Rw/ address[3] input bit
.A4(A4), // Rw/ address[4] input bit
.D(D), // Write 1-bit data input
.DPRA0(DPRA0), // Read-only address[0] input bit
.DPRA1(DPRA1), // Read-only address[1] input bit
.DPRA2(DPRA2), // Read-only address[2] input bit
.DPRA3(DPRA3), // Read-only address[3] input bit
.DPRA4(DPRA4), // Read-only address[4] input bit
.WCLK(WCLK), // Write clock input
.WE(WE) // Write enable input
);
分布式RAM和 BLOCK RAM的选择遵循以下方法:
- 小于或等于64bit容量的的都用分布式实现
- 深度在64~128之间的,若无额外的block可用分布式RAM。 要求异步读取就使用分布式RAM。数据宽度大于16时用block ram.
- 分布式RAM有比block ram更好的时序性能。 分布式RAM在逻辑资源CLB中。而BLOCK RAM则在专门的存储器列中,会产生较大的布线延迟,布局也受制约
SLICEM中的LUT可以配置为32位移位寄存器,而无需使用slice中可用的触发器。以这种方式使用,每个LUT可以将串行数据延时1到32个时钟周期(A[4:0]为多少就是延时多少个时钟周期输出)。移入D(DI 1 LUT引脚)和移除Q31(MC31 LUT引脚)线路将LUT级联,以形成更大的移位寄存器。因此,SliceM中的四个LUT被级联可以产生高达128个时钟周期的延时。
SRLC32E #(
.INIT(32'h00000000), // Initial contents of shift register
.IS_CLK_INVERTED(1'b0) // Optional inversion for CLK
)
SRLC32E_inst (
.Q(Q), // 1-bit output: SRL Data
.Q31(Q31), // 1-bit output: SRL Cascade Data
.A(A), // 5-bit input: Selects SRL depth
.CE(CE), // 1-bit input: Clock enable
.CLK(CLK), // 1-bit input: Clock
.D(D) // 1-bit input: SRL Data
);
2、多路选择器
7系列FPGA LUT和F7AMUX、F7BMUX、F8MUX相配合可以实现以下类型的多路复选器:
使用1个LUT的4:1多路选择器(4输入,1输出)
使用2个LUT的8:1多路选择器(8输入,1输出),需要F7AMUX或者F7BMUX配合。
使用4个LUT的16:1多选择选器(16输入,1输出),需要F7AMUX、F7BMUX、F8MUX三个一起配合。这个多路选择是实现case语句用的的基础。
3、 进位链
进位链用于实现加法和减法运算的硬件电路,有固定的电路延时(在激光雷达测量TOF时间常用到)。
端口S[3:0]是(要求输入的两个数据a、b)数据的异或输入;端口DI[3:0]是数据的输入(a,b都可以),通过选择器判断是否是进位标志;MUXCY选择器作为向下一级输出标志的选择端口;
CARRY4 CARRY4_inst (
.CO(CO), // 4-bit carry out
.O(O), // 4-bit carry chain XOR data out
.CI(CI), // 1-bit carry cascade input
.CYINIT(CYINIT), // 1-bit carry initialization
.DI(DI), // 4-bit carry-MUX data in
.S(S) // 4-bit carry-MUX select input
);
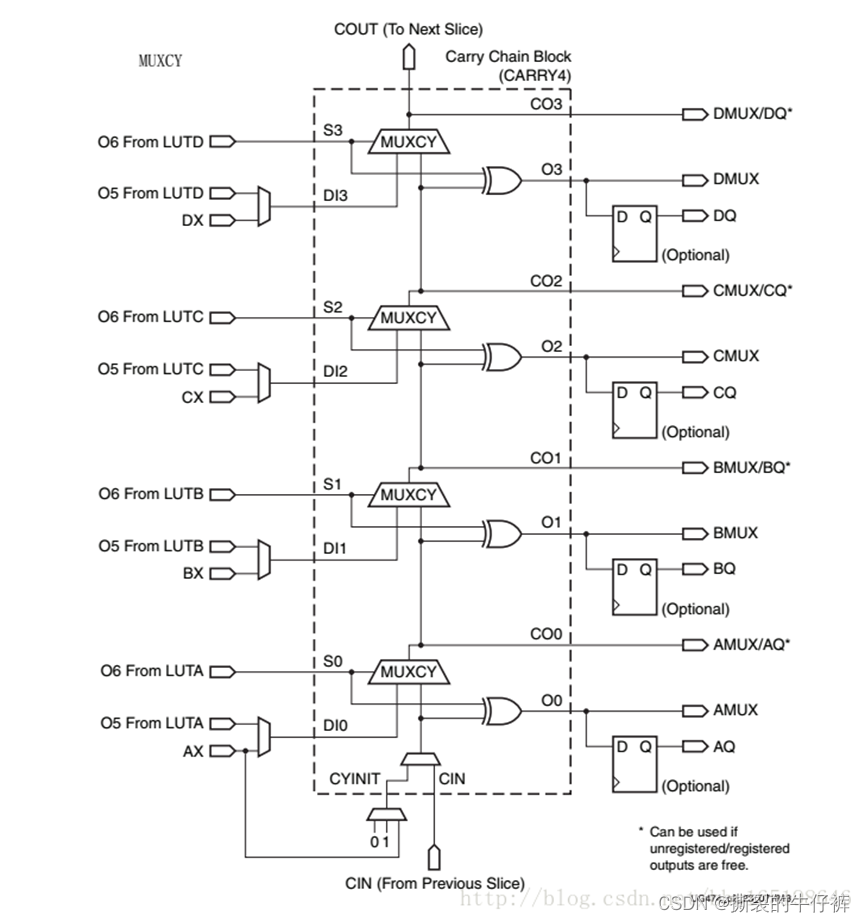
进位链是一个很重要的资源,这个在代码编译后可通过观察RTL图来进行查看。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









