







OffLoading技术
Dynamic Computation Offloading)/混合部署/混合推理
- Offload 技术(也可以理解为混合部署或混合推理)
- 将对象卸载到外部资源或将其分布在多种设备上以减少主设备的内存负载
- 常用用于在GPU显存有限的设备上优化内存使用。比如:将GPU显存中的权重卸载到CPU内存、NVMe/Disk。
对于推理场景下,Offload的对象有以下两种:
- 权重
- KV Cache
Accelerate
在 Transformers 库中利用Accelerate库来完成超大模型的加载。Accelerate 利用 PyTorch 来加载和运行大模型进行推理的具体步骤如下:
- 创建一个空模型(没有权重)
- 当有多个计算设备可用时,决定每一层权重的去向。Accelerate库提供了一个函数用来自动检测一个空模型使用的设备类型。它会最大化利用所有的GPU资源,然后再使用CPU资源,并且给不能容纳的权重打上标记,并 offload 到硬盘。
- 加载部分权重到内存
- 将内存中的这些权重加载到空模型中
- 将权重移动到计算设备上完成推理
- 对剩下的权重,重复步骤 3,直到加载完所有权重,并完成最终推理。
def get_llm(model_name, cache_dir="llm_weights"):
model = AutoModelForCausalLM.from_pretrained(
model_name,
max_memory={0:"12GiB",1:"12GiB",2:"12GiB",3:"12GiB","cpu":"150GiB"},
offload_folder="offload",
offload_state_dict=True,
torch_dtype=torch.float16,
cache_dir=cache_dir,
low_cpu_mem_usage=True,
device_map="auto"
)
model.seqlen = model.config.max_position_embeddings # 2048
return model
-
通过设置
device_map=auto,会根据可用资源自动确定模型每一层的放置位置"auto"或"balanced": Accelerate将会根据所有GPU均衡切分权重,尽量均匀的切分到各个GPU上;"balanced_low_0": Accelerate均匀分割权重到各个GPU上,除了第一个GPU(序号为0)。在第一个GPU上会尽量节省显存(这种模式可以有效节省第一个GPU的显存,以便使用generate函数用于模型生成);"sequential": Accelerate按照GPU的顺序占用显存(后面的GPU可能根本不会使用)。- 也可以根据需求设置
device_map参数,以决定各个部分权重应该放置的设备。
device_map = {"block1": 0, "block2.linear1": 0, "block2.linear2": 1, "- 还可以通过max_memory来控制各个设备使用的内存的大小。
max_memory={0: "10GiB", 1: "20GiB", 2: "20GiB", "cpu": "60GiB"} -
通过max_memory来控制各个设备使用的内存的大小。
-
模型加载完成后,通过model.hf_device_map查看模型中每一层放置的具体位置


DeepSpeed
deepspeed安装
首先要进行预备库安装,其次再进行源安装!
预备库安装
- 必须确保环境提前安装了gcc, g++, torch, cuda, cudnn, transformers相关库
-
gcc,g++安装命令
sudo apt-get install build-essential- 需要确保环境运行的g++与gcc版本一致,可以去查看gcc,g++安装位置-->/usr/bin/下的gcc与g++版本
-
这里gcc与g++都为11
-
使用软链接设置系统gcc与g++路径
sudo ln -sf /usr/bin/gcc-11 /usr/bin/gcc sudo ln -sf /usr/bin/g++-11 /usr/bin/g++
-
- 需要确保环境运行的g++与gcc版本一致,可以去查看gcc,g++安装位置-->/usr/bin/下的gcc与g++版本
-
torch,cuda, cudnn安装,参考之前发的教程win11 WSL ubuntu安装CUDA、CUDNN、TensorRT最有效的方式
- 这里我们的torch 为2.4.0
- cuda为12.1
- cudnn为8.9.7
-
transformers库相关安装,参考之前发的教程大模型基础配置之Win11安装HuggingFace Transformers库
-
deepspeed源安装
尽管可以直接通过pip安装,但安装不全后续会出现较多的错误,建议在已经进行了预备库的安装后,我们直接克隆deepspeed源码进行安装!
deepspeed git地址:https://github.com/microsoft/DeepSpeed
-
第一步,git clone
git clone https://github.com/microsoft/DeepSpeed/ -
切换到DeepSpeed目录下,开始安装
cd DeepSpeed TORCH_CUDA_ARCH_LIST="8.0" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1 | tee build.log-
上面的TORCH_CUDA_ARCH_LIST="8.0"根据自己的GPU参数进行调整,命令参考
CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())" -
若需要使用 CPU Offload 优化器参数,设置参数
DS_BUILD_CPU_ADAM=1 -
若需要使用 NVMe Offload,设置参数
DS_BUILD_UTILS=1
-
-
安装完成后,通过ds_report命令查看,是否还有未安装的包
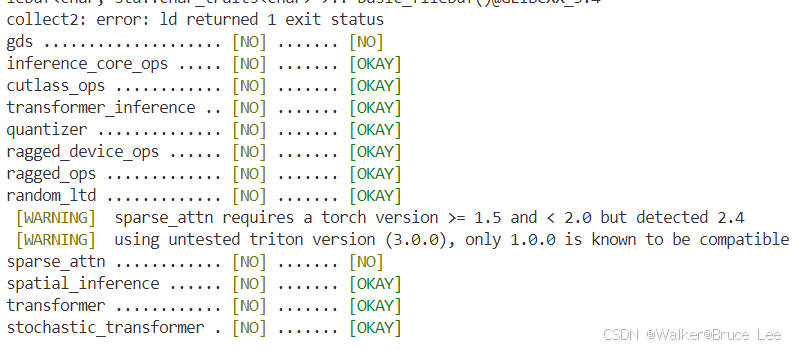
若存在,则通过pip install进行安装,对于sparse_attn需要安装Cython
pip install Cython
pip install torchsparseattn
运行deepspeed相关报错记录
- No module named 'mpi4py',不要pip安装,通过conda安装不会报错
conda install mpi4py
最后通过import deepspeed进行验证
deepspeed 代码测试
理想情况下当GPU充足,显存足够的话,我们可以直接训练或者推理大模型,但实际上通常面对GPU显存不足的情况,这个时候需要将模型部分参数卸载到CPU或者disk上运行大模型,deepspeed能够使用offload技术来卸载权重,将模型分布到多张GPU上或者Offload到内存或者NVMe上,使单GPU无法加载的模型进行推理。
这里介绍deepspeed的两种Inference
- ZeRO-Inference
- DeepSpeed-Inference
ZeRO-Inference
- 原理:在有限的 GPU 预算上进行大模型推理的一个重要设计决策是如何在模型权重、推理输入和中间结果之间分配 GPU 内存
- 卸载所有模型权重
- 将整个模型权重固定在 CPU 或 NVMe 中,并将权重逐层流式传输到 GPU 中以进行推理计算。计算完一层后,输出将保留在 GPU 内存中作为下一层的输入,而层权重消耗的内存将被释放以供下一层使用
- 因此, 模型推理时间由在 GPU 上计算各层的时间和通过 PCIe 获取各层的时间组成 。
- ZeRO-Inference 显著减少了推理大规模模型所需的 GPU 内存量
- 对于当前具有大约一百层的大模型(例如,GPT3-175B 和 Megatron-Turing-530B 中分别有 96 层和 105 层),ZeRO-Inference 将 GPU 内存需求降低了两个数量级。例如,通过ZeRO-Inference,Megaton-Turing-530B 半精度(FP16)推理的GPU内存消耗从1TB下降到10GB。
- 需要注意的是,zero-inference将模型参数卸载到CPU 或 NVMe,其主要延迟是模型的加载
- 但 ZeRO-Inference 仍可为面向吞吐量的推理应用程序提供高效计算。主要原因是 通过将 GPU 内存使用限制为模型的一层或几层权重,ZeRO-Inference 可以使用大部分 GPU 内存来支持大量以长序列或大批量形式出现的输入Token 。
- 卸载所有模型权重
主要代码示例
我们以OPT-125M为例
-
导入deepspeed及transformers库
import torch import deepspeed import os import time from transformers.deepspeed import HfDeepSpeedConfig from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLM -
预训练模型与tokenizer加载
def get_llm(model_name, cache_dir="llm_weights"):
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
cache_dir=cache_dir,
# low_cpu_mem_usage=True,
# device_map="auto"
)
model.seqlen = model.config.max_position_embeddings # 2048
return model
model= get_llm("./llm_weights/models--facebook--opt-125m/snapshots/opt-125m")
tokenizer = AutoTokenizer.from_pretrained("./llm_weights/models--facebook--opt-125m/snapshots/opt-125m")
- 设置deepspeed config
ds_config = {
"fp16": {"enabled": True},
"bf16": {"enabled": False},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu"
}
},
"train_micro_batch_size_per_gpu": 1
}
- deepspeed初始化
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
- 执行推理
ds_engine.module.eval()
start = time.time()
inputs = tokenizer.encode("DeepSpeed is", return_tensors='pt').to(f"cuda:{local_rank}")
outputs = model.generate(inputs, max_new_tokens=20)
output_str = tokenizer.decode(outputs[0])
end = time.time()
print(output_str)
print("ZeRO-Inference time:", end-start)
ds_engine的结构如下:
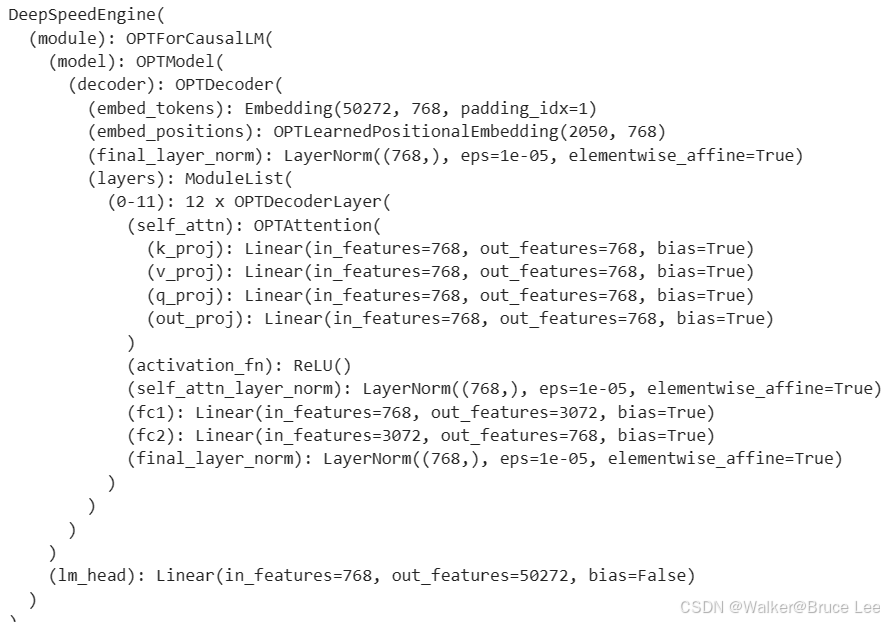
需要注意的是由于卸载了权重,通过ds_engine去打印模型参数,是空的

但依然能执行前向推理,目前我还不知道如何获取deepspeed的参数,若能获取权重参数可执行其他中间运算!
DeepSpeed-Inference
DeepSpeed-Inference是一个独立的引擎,为运行推理引入了大量优化。
- 支持对数万个模型进行自定义Kernel注入(它比 pytorch/transformers 提供的基准 Kernel 有更好的性能),可以显著提高延迟和吞吐量。
- 在进行推理时获得最低延迟的最佳选择,但代价是需要更多的 GPU 内存。
而ZeRO-Inference主要针对我们希望在非常有限的 GPU 内存上使用非常大的模型运行推理的情况。它利用 ZeRO Offload 功能将大部分模型权重移动到 CPU 内存(甚至 NVME 存储)。由于存在与卸载权重相关的开销,因此它通常不太适合低延迟推理的场景。
- ZeRO-Inference,较高的延迟推理
- 较少的GPU
代码示例
config = AutoConfig.from_pretrained("./llm_weights/models--facebook--opt-125m/snapshots/opt-125m")
tokenizer = AutoTokenizer.from_pretrained("./llm_weights/models--facebook--opt-125m/snapshots/opt-125m")
with deepspeed.OnDevice(dtype=torch.float16, device="meta", enabled=True):
model= AutoModelForCausalLM.from_config(config, torch_dtype=torch.float16)
checkpoint_dir = './llm_weights/models--facebook--opt-125m/snapshots/opt-125m'
checkpoint_files = [os.path.join(checkpoint_dir, "pytorch_model.bin")]
checkpoint_dict = {
"type": "DS_MODEL",
"checkpoints": checkpoint_files,
"version": 1.0
}
print(checkpoint_dict)
with deepspeed.OnDevice(dtype=torch.float16, device="meta", enabled=True):
# model= AutoModelForCausalLM.from_config(config, torch_dtype=torch.float16)
model= get_llm("./llm_weights/models--facebook--opt-125m/snapshots/opt-125m")
model = deepspeed.init_inference(
model,
replace_with_kernel_inject=False,
tensor_parallel={'tp_size':world_size},
dtype=torch.float16,
checkpoint=None,
)
通过打印模型参数可以发现,参数分配在gpu上不为空(未卸载在cpu上)

- 执行推理
start = time.time()
inputs = tokenizer.encode("DeepSpeed is", return_tensors='pt').to(f"cuda:{local_rank}")
outputs = model.generate(inputs, max_new_tokens=20)
output_str = tokenizer.decode(outputs[0])
end = time.time()
print(output_str)
print("DeepSpeed-Inference time:", end-start)
















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









