







1 基本运算符
| / | 除法,运算结果为浮点数
|
| // | 除法,运算结果向下取整 也就是说,如果结果是负数的话,会找比它小的、最大的那个负数
|
| + | 布尔值的加减运算中,True被看作1,False被看作0 |
| % | 求模运算 x%y=x-(x//y)*y
|
| ** | 乘方运算符 a**b相当于pow(a,b)
|




2 进制、类型转换
| 0x 0b | 十六进制、二进制互相转换
|
| bin | 十进制转为二进制(转换之后的类型为string) |
| bytes | 字符串转字节 |
| chr | 十进制转化为ASCII码
|
| float | 转化为浮点类型
|
| hex | 十进制转换为十六进制
|
| int(x,base) | 将一个字符串或者数字转换成整形
|
| oct | 十进制转为八进制(转换之后的类型为string)
|
| ord | ASCII码转为十进制
|








3 比较、is和==
==比较两个对象的 值是否相等
is比较他们俩是否是一个对象(在内存中的地址是否一样)

4 数学函数
| abs | 绝对值/复数的模
|
| divmod(a,b) | 取商&取余数 返回(a//b,a-(a//b)*b)
|
| pow(a,b) | a的b次幂
|
| round(a,b) | 舍五入a,保留b位小数
|





5 复数运算(cmath包)
| 创建复数 |
|
| 复数运算 |  |
| conjugate | 计算共轭
|



6 文件操作
6.1 文件读写模式
| 'r' | 只读。如果文件不存在,会产生异常(报错) |
| 'r+' | 在'r'的基础上,同时可写。不建议使用 |
| 'w' | 覆盖写。如果文件不存在,创建文件;如果文件存在,覆盖文件(清空文件,从文件开头写) |
| 'w+' | 在'w'基础上,同时可读 |
| 'a' | 追加写。如果文件不存在,创建文件;如果文件存在,在文件末尾追加内容 |
| 'a+' | 在'a'的基础上,同时可读 |
| 'x' | 与'w'相比,如果文件不存在,则产生异常(报错) |
| 'x+' | 在'x'基础上,同时可读 |
6.1.1 文件格式
| 't' | 文本文件,默认情况 |
| 'b' | 二进制文件,例如图片、音乐、视频等 |
6.2 文件基本操作
| read | 读取文件,后面带一个可选参数,表示读取多少个字符
| |
| write | 写文件 用write()把字符串写入文件。注意和print()不同,不会自动换行,要手工标记'\n' 务必用close()关闭文件 | |
| 写 csv
| ||
| writelines | 1、用writelines(列表)把列表写入文件 2、注意,writelines不会自动加入换行。如需换行,要在列表的各元素末尾加'\n' | |
| readline | 读一行 读回的一行会自带换行符'\n' | |
| readlines | 读取文件 读回的每一行会自带换行符'\n' 返回一个列表,每一个元素代表文件的一行 | |



6.3 文件指针基本操作
| tell | 返回文件指针的当前位置 |
| seek | 改变文件操作指针的位置 fileObject.seek(offset[, whence])
|

6.3 复杂操作
| python 文件处理1:将某一目录下的文件合并_刘文巾的博客-CSDN博客 |
| python文件操作2:在指定目录下查找指定后缀名的文件_刘文巾的博客-CSDN博客 |
7 类和类的函数
7.1 类的定义
- 类名通常首字母为大写
- 类定义包含 属性 和 方法
- 其中方法(method)的形参self必不可少,而且必须位于最前面。
- self形参:类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称,但是在实例中调用这个方法的时候不需要为这个参数赋值, Python会提供指向实例的引用。

7.2 类的函数
| __class__ | 对象所属于的类的信息
|
| isinstance(object,class) | 判断一个对象是不是一个类的实例(一个类也是它的父类的instance)
|
| issubclass(class1, class2) | 判断一个类是不是另一个类的子类(object类是所有类的父类)
|
| hasattr | (has attribute)对象是否有这个属性值
|
| setattr | 设置对象的属性
|





7.3 类的继承
基类BaseClassName必须和派生类DerivedClassName定义在一个作用域内(如果不在,那么使用import将他们放入一个作用域内)


7.3.1 子类的构造函数

7.3.2 继承关系
继承关系构成了一张有向图。在python3中,调用super()函数,会返回广度优先搜索找到的第一个符合条件的函数
class A:
def print_(self):
print('A')
class B(A):
pass
class C(A):
def print_(self):
print('C')
def print_2(self):
super().print_()
class D(B,C):
pass
d=D()
d.print_() #C
d.print_2() #A- d调用print_()时,先广搜他的第一层父亲B和C,看看有没有print_函数,然后在C中找到了,所以这里print的是C
- 调用print_2()时,也是先广搜他的第一层父亲B和C,看看有没有print_2函数,然后再C中找到了,C继承的是A,于是调用的是A的print_()
7.4 类的私有属性和方法
用两个下划线开头,声明该属性为私有,不能在类的 外部被使用/直接访问
class A():
def __init__(self):
self.num=1
self.__nu=2
def print1(self):
print(self.num)
print(self.__nu)
def __print2(self):
print(self.num)
print(self.__nu)
a=A()
a.num
#1
a.__nu
'''
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[10], line 1
----> 1 a.__nu
AttributeError: 'A' object has no attribute '__nu'
'''
a.print1()
'''
1
2
'''
a.__print2()
'''
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[12], line 1
----> 1 a.__print2()
AttributeError: 'A' object has no attribute '__print2'
'''
a.__print2()
8 字符串
python字符串不可修改
8.1 长字符串
表示很长的字符串 可以跨越多行的字符串——用三引号(单引号双引号都可以)
这样的字符串内部单双引号不用转义(可同时解决字符串换行、字符串内单双引号的问题,同时也可以换行)

8.2 原始字符串
常规的字符串中,反斜杠\表示对字符串进行转义的意思
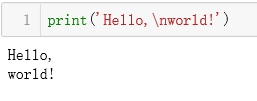
\n 表示的是换行符,但有的时候我们要在字符串中包含\n(比如计算机的路径【C:\nowhere\tere】的时候),我们有两种解决方法
1,双反斜杠,第一个反斜线是转义字符
2,字符串前面加r, r' '表示' '内部的字符串默认不转义

8.3 字符串换行
一行代码太长的时候,我们可以在任意位置用反斜杠结尾,换下一行继续写 。程序执行时,仍视为一行

8.4 字符串格式
8.4.1 format 函数
通过大括号占位,使用format()中的参数代替相应的位置
| 基本使用(不带任何参数) |  |
| 括号里面带数字 |  括号里面也可以不按顺序
|
| 括号里面命名 |  |
| 通过list,命名 |  |
| 【python3.6之后支持】 | 在字符串前面加上f,表明这是一个格式化字符串。然后在大括号内直接使用变量名来代替内容
|


8.4.2 指定格式
| b | 将整数表示成二进制数
|
| c | 将整数表示为Unicode码
|
| e | 使用科学计数法(用e表示指数) 冒号后面,e前面的.n表示精确到几位小数
|
| E | 使用科学计数法(用E表示指数) 默认精确到六位小数
|
| f | 将小数表示为定点数(默认的话是小数点后六位小数) :.0f——不带小数位
|
| o | 将整数表示为八进制数
|
| s | 字符串 |
| x | 将整数表示为十六进制,同时使用小写字母
|
| X | 将整数表示为十六进制,同时使用大写字母
|
| % | 表示为百分比值
|









8.4.3 填充与对齐
- 冒号前面
- 用于指定要格式化的参数的索引
- 如果没有提供索引,则默认从左到右顺序匹配参数

- 冒号
- 分隔符,用于将格式说明符与占位符分开
- 冒号后面跟的内容
- 用于填充值的字符,通常是零
- 数字
- 用于指定最小宽度,表示生成的字符串至少包含多少字符
| 指定字符串宽度 |
|
| 用零而不是空格填充 |
< ^ >分别表示向左、居中、向右对齐 后面跟的第一个0表示用0填充 之后表示填充到长度为10位 .2f就和前面一样了,表示精确到两位小数 |
| 同时设置类型和宽度 |
|
| 使用逗号来表示千位分隔符 |
|
| 左/右/居中对齐(用< > ^表示) |
|




8.4.4 %格式化输出方法
- 类C语言,用%参数作为格式化参数。在字符串变量的后面用%连接一个tuple,用来替换字符串中的参数

| 格式化符号 | 含义 |
| %c | 字符 |
| %s | 字符串 |
| %u | 无符号整型 |
| %o | 无符号八进制数 |
| %x | 无符号十六进制数(小写) |
| %X | 无符号十六进制数(大写) |
| %d | 数字 |
| %f | 浮点数字
|

8.5 字符串方法
| capitalize | 字符串首字母大写,其他字母小写(原字符串不会受影响)
|
| center(num,char) | 在原先字符串的基础上,在其两边填充字符达到center第一个参数这么多位数(默认为空格),使得字符串居中
|
| count | 计算里面的某一个子串的个数
|
| find | 在字符串中查找子串。 如果找到的话,返回字串出现的第一个字符 如果没有找到的话,返回-1
find(str,a,b) 在下标a~b范围内 找相应的str |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
|
| isdigit | 字符串中是否全是数字字符
|
| translate | 将字符串中某些字符换成其它字符
|
| join | 合并序列元素(不改变原先字符串)
|
| len | 字符串长度
|
| lower | 返回字符串的小写版本(原字符串不会受影响)
|
| replace | 将指定子串替换成另一个字符串,返回替代后的结果
|
| split | 将字符串拆分(默认是以空格拆分)
|
| startswith | 判断是否以一个字符/一串字符开始
|
| endswith | 判断是否以某一个字符/一串字符结束
|
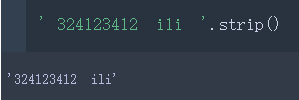
| strip | 将开头和结尾的空白删除(lstrip&rstrip,去掉左/右空格)
也可以指定要删除哪些字符
|
| swapcase | 大小写反转(原字符串不会受影响)
|
| title | 字符串每个词的词首大写(原字符串不会受影响)
|
| upper | 返回字符串的大写版本(原字符串不会受影响)
|


















8.6 f格式字符串
在使用 f 模式的情况下,我们要在字符串开头加上一个 f。然后用 {} 圈出你的变量名,直接在 {} 引用变量
pi=3.1415926
print(f"pi's value is {pi}")
#pi's value is 3.1415926和前面的format一样,也可以指定输出的格式
pi=3.1415926
print(f"pi's value is {pi}")
print(f"pi's value is {pi:.3%}")
print(f"pi's value is {pi:.0f}")
'''
pi's value is 3.1415926
pi's value is 314.159%
pi's value is 3
'''你也可以在大括号中进行运算操作
pi=3.1415926
print(f"pi's value is {pi+1}")
#pi's value is 4.14159268.7 字符串修改单个元素
直接修改元素值是不行的
a='Hello World'
a[0]='L'
#TypeError: 'str' object does not support item assignment可以借助列表实现之:
a='Hello World'
s=list(a)
s[0]='L'
''.join(s)
#Lello World9 列表生成式


10 列表
列表里面的元素可以不是一个类型
10.1 列表索引
负数索引表示从右向左

10.2 列表切片
范围是左闭右开

第二个冒号之后表示步长
步长为负数:从右向左

给切片赋值:可以将切片替换成长度与其不同的序列

给切片赋值还可以在不替换原有元素的情况下插入新元素

10.3 序列相加
可以用加法来拼接序列,但一般不同类型的序列不能拼接

10.4 序列数乘
重复这个序列n次

10.5 序列内置函数
| append | 将一个对象添加到列表的末尾
|
| count | 计算指定的元素在列表中出现了几次
|
| copy以及列表的复制 | 等号相当于是一个引用,相当于给列表设置了一个别名。新老名字指向同一个列表
copy相当于新建一个对象
另一种复制的方法是lst[:],这个也是生成新的列表
|
| clear | 清空列表
|
| del | 删除下标为x的元素
|
| extend | 将可迭代的元素添加到列表中(有别于append)
相当于+=
注:虽然效果是一样的,但是+会比extend的开销大很多,因为“+”运算时新建一个list,然后copy进去,开销会比extend大很多
|
| in | 运算符in返回一个布尔变量,判断特定的值在不在序列中
|
| index | 返回指定值第一次出现时候的索引
如果列表中没有这个值,报错
我们也可以人为定义index的范围
|
| insert(x,y) | 在指定位置插入对象(在第x个位置插入元素y)
|
| len | 序列长度
|
| max min | 最大最小值
|
| pop(i) | 从列表中删除下标为i的元素(如果没有参数的话,默认为最后一个元素),并返回这个元素
|
| remove | 删除第一个为指定值的元素 (如果没有这个元素,报错) 不按照序号,按照内容查
|
| reverse | 列表反转
|
| sort | 直接对列表进行排序,不返回任何值 (区别于sorted,sorted不改变原有列表;sort直接修改列表)
倒序排序:参数里面加上reverse=True
可以支持高级排序。key可以是我们定义的函数,lambda函数等
上例中,北京和南京的字符串长度是一样的。此时两者再比较字典序 如果列表的每个元素也是列表/元组,那么默认参数按照第0个元素进行排序
如果不想按照第0个元素排序,可以手动设置key 值
|
| sorted | 从小到大排序 不改变原有列表
可以接受一个key函数(参数为来实现自定义的排序
reverse——逆向排序(从大到小)
字符串排序默认使用ascii码
如果列表的每个元素也是列表/元组,那么默认参数按照第0个元素进行排序
|
| sum | 求和
|






























11 元组
元组值不可修改
11.1 元组的表达方式
11.1.1 不带括号的表达方式
注意单个值的元组,即使只有一个值,也要加逗号

11.1.2 带括号的表达方式
注意单个值的元组,即使只有一个值,也要加逗号


11.2 内置函数
大部分的内置函数和列表的一样,见10.5就可以了
11.3 序列和元组的相互转化

11.4 tuple的比较
tuple是一个一个比较的,第一个一样了再比较第二个。
第一个如果已经可以区分大小了,就不必看第二个了。
我们已知有这样的大小关系:(‘10’<‘9’是因为‘1’的字典序小于‘9‘)

那么接下来的这几个元组可以这么比较:

第一行和第二行,因为10<9,0<9,所以已经能比较了,就不用看第二个了。
第三行因为第一个对应的元素都一样,所以需要比较第二个元素.
11.5 tuple的展开
a=tuple('1234')
a
'''
('1', '2', '3', '4')
'''a,b,*_=tuple('1234')
a,b
'''
('1', '2')
'''12 集合
无序的集合,没有重复的元素
12.1 集合的声明

创建一个空的集合,必须使用set()而不能是{},因为{}是用来创建一个空的字典
12.2 集合的内置函数
| add | 添加元素
如果要add的值已经在集合里面,那这一步相当于啥也没做 |
| clear | 清空集合元素 |
| difference | 两个set里面不同的元素 a.difference(b)的意思是在a却不在b中的元素,也就是a和b的集合差
|
| symmetric_difference | a.difference(b) | b.difference(a) (或者^)
|
| intersection | 两个set的交集(或者&)
|
| discard | 移除集合中的元素x,且如果元素不存在,不会发生错误。 |
| remove | 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。 |
| union | 两个set的并集(huo
|
| issubset | 是不是子集(可以用<,<=代替)
|
| issuperset | 是不是包含着另一个set(可以用>,>=代替)
|
| isdisjiont | 判断两个set交集是否为空,是空集则为True
|













13 字典
13.1 字典的创建

13.1.1 从列表中创建字典

另一种写法
key_lst=['a','b']
value_lst=[1,2]
list(zip(key_lst,value_lst))
#[('a', 1), ('b', 2)]
dict(zip(key_lst,value_lst))
#{'a': 1, 'b': 2}13.2 字典内置函数
| clear | 删除所有的字典项
|
| del | 删除键值为k的项
|
| dict[k] | 返回和键值k相对应的值
如果字典中没有k这个键值,dict[key]=x,会新建一个新项,否则就是修改值
|
| get | 访问字典项,不同于直接dict[key],get访问的时候,如果没有这个键值,会返回none(或者自己指定的value),而不是报错
|
| keys | 返回键值
|
| len | 返回键值对数
|
| in | 字典中是否有包含键值为k的项
相当于__contains__(key)
|
| items | 返回包含键值对(元组)的列表
|
| pop | 获取与指定键值相关联的值,并将该键值对从字典中删除 如果要pop的内容不在字典中,那么会报错
|
| popitem | 随机弹出一个字典项(这个在需要逐个弹出字典项,但是又不要求弹出顺序的时候很有用)
|
| setdefault | 和get有点像,不一样的是,在字典中不包含指定的项的时候,添加指定的键值对(如果不指定键值的话,默认为None)
|
| update | 用另一个字典的项来更新一个字典 没有的——添加进来,有的——修改掉
|
| values | 返回值的list,可能会有重复值
|
















13.3 字典排序
| 利用key排序 |
|
| 利用value排序 |
|
| 利用value排序(反序) |
|
| 对dict_items进行排序 |
|




13.4 字典的复制
和列表一样,等号赋值相当于去取了一个别名,本质上这两个是一个字典


要达到复制的效果,需要建立一个空字典,再用update合并字典

13.5 字典数据筛选

14 其他函数
| all | 接受一个可迭代对象,如果可迭代对象的所有元素都为真,那么返回True,否则,返回False
|
| any | 接受一个可迭代对象,如果可迭代对象里至少有一个元素为真,那么返回True,否则返回False
|
| callable | 类型是否可调用
|
| eval | 执行一个字符串表达式,并返回表达式的值
|
| enumerate | 把一个可遍历对象(列表、元组、字符串)变成一个下标-元素对
可以有一个可选变量start,表示下标起始 的位置
enumerate +字典:对键值进行枚举
|
| filter ( func, iterable) | 过滤器,丢弃 func返回值为False的部分
|
| | 接受多个东西,用逗号隔开(遇到逗号输出一个空格)
|
| help(func) | 查看函数的帮助信息
Sep=‘ ’这样的话逗号不会被输出成空格
|
| id | 返回内存地址
|
| input | 让用户输入一个字符串
|
| map(function,iterable) | 根据提供的函数对指定序列做映射,返回一个新列表
上面的例子相当于l列表中每个元素乘方 |
| reduce(fucntion,iterable) | 对参数序列中的元素进行累积 将一个数据集合中的所有数据进行如下操作:用传给reduce中的函数function(这个函数有两个参数),先对集合中的第一和第二个元素进行操作,将得到的结果再与第三个数据用function函数进行运算,最后得到一个结果
上面的例子相当于(((1+2)+3)+4)+5 |
| type | 查看对象类型
|
| zip |
































 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











