









 本文介绍了如何使用Python处理GeoLife数据,通过多步骤操作包括读取、筛选、生成staypoints和triplegs,构建用户行为模型。重点在于使用自注意力机制预测用户下一站的位置,以及对数据进行预处理和清洗,为接下来的序列预测任务做准备。
本文介绍了如何使用Python处理GeoLife数据,通过多步骤操作包括读取、筛选、生成staypoints和triplegs,构建用户行为模型。重点在于使用自注意力机制预测用户下一站的位置,以及对数据进行预处理和清洗,为接下来的序列预测任务做准备。
类似于
对应命令行里
python preprocessing/geolife.py 20这一句,但是会稍有不同
1 读取geolife数据
from trackintel.io import read_geolife
pfs, _ = read_geolife(config["raw_geolife"], print_progress=True)
2 截取北京五环内的记录
2.1 北京五环大致位置
import folium
m=folium.Map(location=(39.8,116.2))
folium.Marker(location=(40.004123,116.549478)).add_to(m)
folium.Marker(location=(39.75835,116.207786)).add_to(m)
m 
2.2 获取五环的polygon
from shapely import Polygon
five_ring=Polygon([(116.549478,40.004123),(116.207786,40.004123),(116.207786,39.75835),(116.549478,39.75835)])
five_ring
2.3 截取五环内的记录
import pandas as pd
import geopandas as gpd
from shapely import wkt, Polygon
# 将DataFrame转换为GeoDataFrame
gdf = gpd.GeoDataFrame(pfs, geometry='geom')
# 使用空间索引快速筛选在多边形内的点
sindex = gdf.sindex
'''
从GeoDataFrame gdf中生成一个空间索引
空间索引允许快速的空间查询,如确定某个点是否在特定区域内。
'''
possible_matches_index = list(sindex.intersection(five_ring.bounds))
'''
five_ring.bounds 返回多边形的边界框(一个矩形,可以完全包含这个多边形)
sindex.intersection() 方法找出所有在这个边界框内的地理对象的索引
这一步不完全精确,因为它基于边界框而非多边形精确形状
【其实对于我们现在这个问题来说,因为五环已经简化成了长方形,这一步就够了】
'''
possible_matches = gdf.iloc[possible_matches_index]
'''
使用前一步获取的索引从gdf中选出可能在多边形内的地理对象,这些是possible_matches
'''
precise_matches = possible_matches[possible_matches.intersects(five_ring)]
'''
进一步使用intersects方法筛选出真正与five_ring多边形相交的地理对象,这些是precise_matches
'''
# 将结果添加到原始GeoDataFrame
gdf['is_in_five_ring'] = gdf.index.isin(precise_matches.index)
gdf
gdf_bj=gdf[gdf['is_in_five_ring']==True]
gdf_bj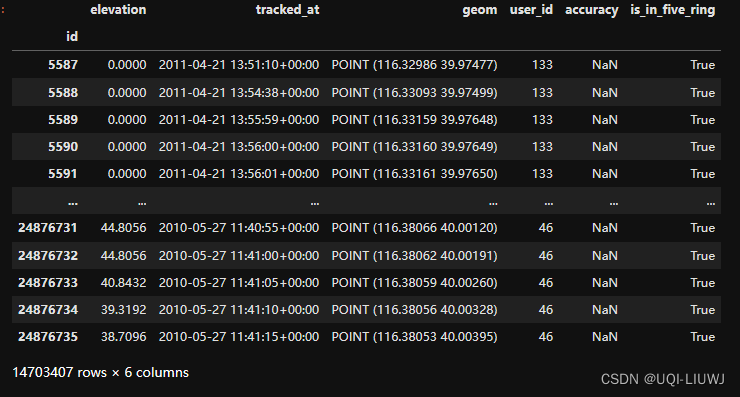
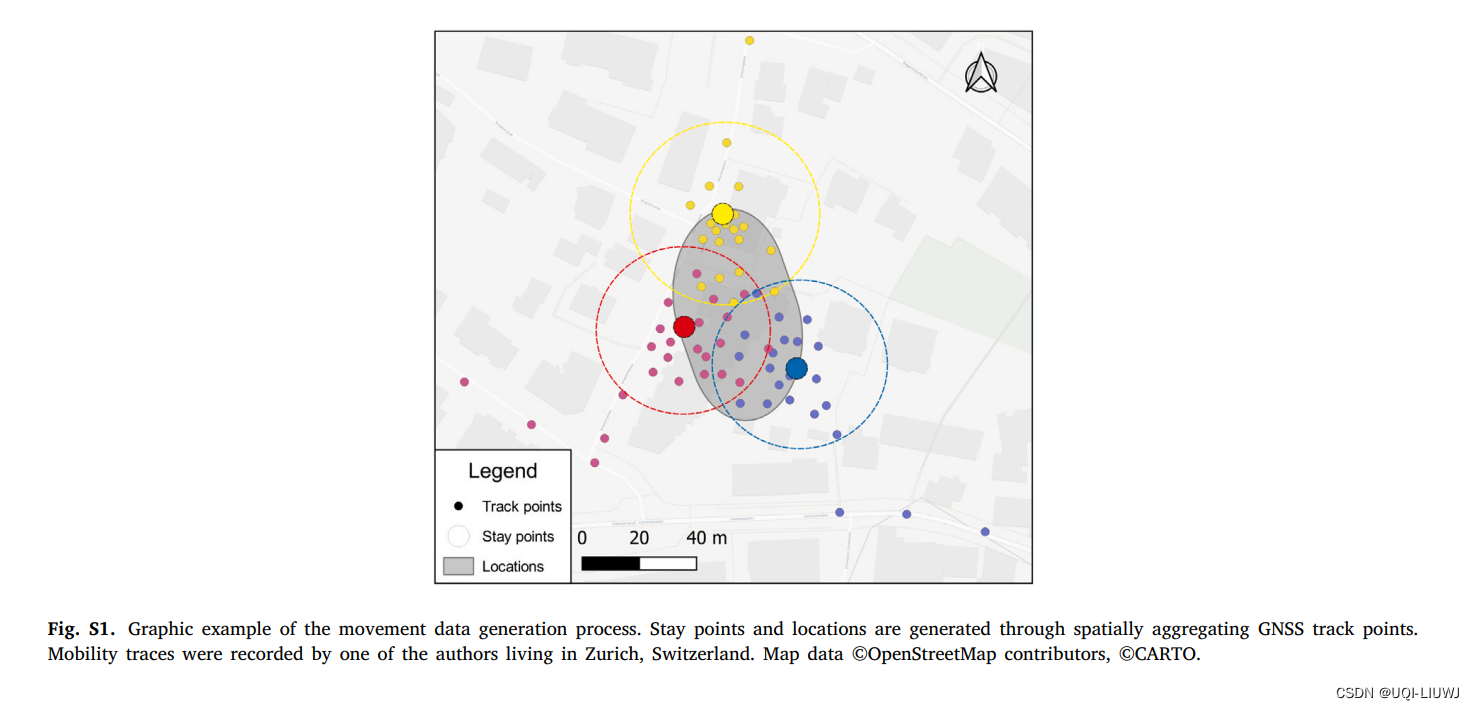
3 生成staypoint 数据
根据geolife数据,使用滑动窗口的方法获取staypoint
同时geolife DataFrame加一列staypoint
pfs_bj, sp = gdf_bj.as_positionfixes.generate_staypoints(
gap_threshold=24 * 60,
include_last=True,
print_progress=True,
dist_threshold=200,
time_threshold=30,
n_jobs=-1
)
pfs_bj 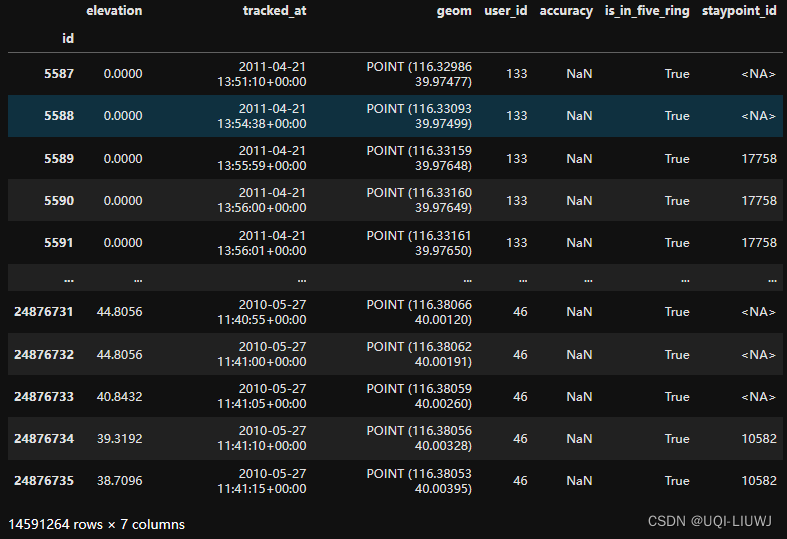
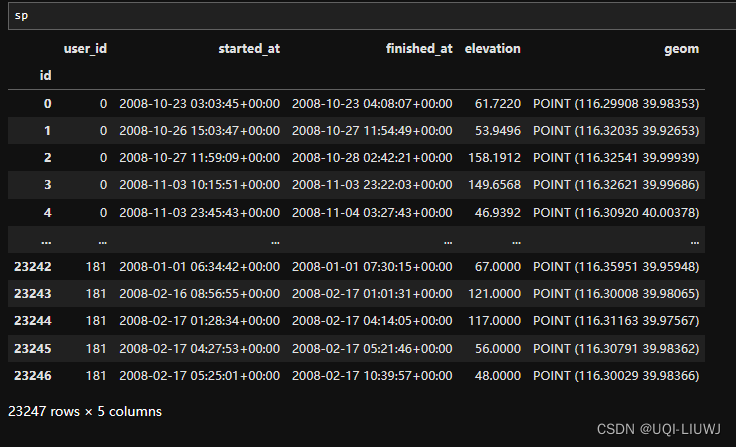
3.1 判断staypoint是否是活动对应的staypoint
sp = sp.as_staypoints.create_activity_flag(
method="time_threshold",
time_threshold=25)如果staypoint停留时间>25min,那么是为一个活跃的staypoint

4 在两个stypoint之间的部分创建行程段
在两个stypoint之间的部分创建行程段
【如果两个非staypoint之间的时间间隔大于阈值的话,视为两个行程段】
pfs_bj, tpls = pfs_bj.as_positionfixes.generate_triplegs(sp)

5 根据停留点和行程段创建trip数据集
from trackintel.preprocessing.triplegs import generate_trips
sp, tpls, trips = generate_trips(sp, tpls, add_geometry=False)
staypoint之前的trip_id,之后的trip_id
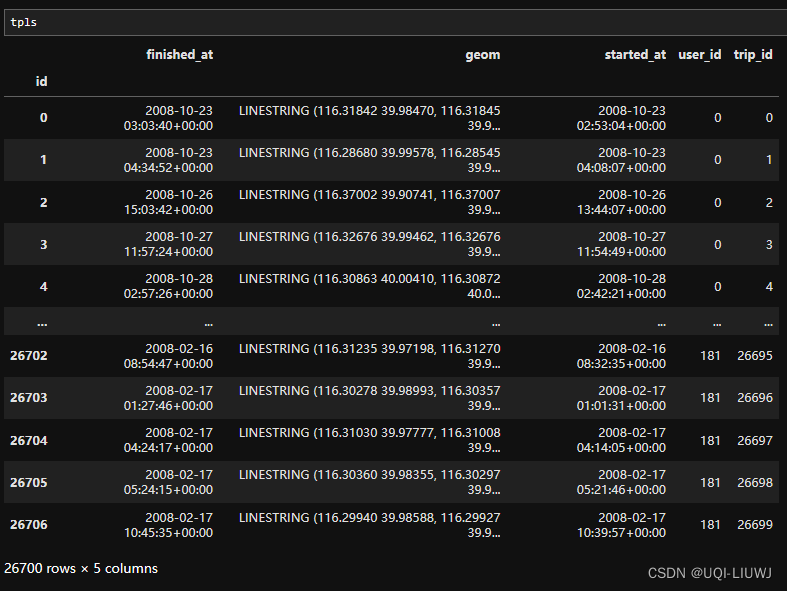
行程和行程的trip_id

行程和行程的始末staypoint_id
6 找到有>50天记录的用户id
6.0 准备部分(合并trips和sp)
trips["started_at"] = pd.to_datetime(trips["started_at"]).dt.tz_localize(None)
trips["finished_at"] = pd.to_datetime(trips["finished_at"]).dt.tz_localize(None)
sp["started_at"] = pd.to_datetime(sp["started_at"]).dt.tz_localize(None)
sp["finished_at"] = pd.to_datetime(sp["finished_at"]).dt.tz_localize(None)
sp["type"] = "sp"
trips["type"] = "tpl"
df_all = pd.concat([sp, trips])
df_all
6.1 横跨多天的staypoint/行程段进行拆分
from trackintel.analysis.tracking_quality import _split_overlaps
df_all = _split_overlaps(df_all, granularity="day")
'''
如果一个trips/staypoint横跨多天了,那么就拆分成两个trips/staypoint
'''
6.2计算每个user id的持续时间
usr_duration=pd.DataFrame(df_all.groupby("user_id").apply(lambda x: (x["finished_at"].max() - x["started_at"].min()).days),
columns=['duration'])
usr_duration 
6.3 过滤有50天以上记录的user
valid_user=usr_duration[usr_duration['duration']>50].index
valid_user
'''
Index([ 0, 1, 2, 3, 4, 5, 9, 10, 11, 12, 13, 14, 15, 16,
17, 20, 22, 23, 24, 25, 26, 28, 29, 30, 34, 35, 36, 37,
38, 39, 40, 41, 42, 43, 44, 46, 50, 51, 52, 55, 56, 58,
59, 62, 65, 66, 67, 68, 69, 71, 73, 74, 75, 78, 81, 82,
83, 84, 85, 89, 91, 92, 95, 96, 97, 99, 101, 102, 104, 110,
111, 112, 114, 115, 119, 122, 125, 126, 128, 129, 130, 131, 133, 134,
140, 141, 142, 144, 145, 147, 148, 153, 155, 163, 167, 168, 174, 179,
181],
dtype='int64', name='user_id')
'''7 筛选staypoint
7.1 筛选在valid_user里面的
sp = sp.loc[sp["user_id"].isin(valid_user)]
7.2 筛选活跃的
sp = sp.loc[sp["is_activity"] == True]
sp
8 聚合staypoint(成为station)
8.0 datetime 加时区
sp["started_at"] = pd.to_datetime(sp["started_at"]).dt.tz_localize('UTC')
sp["finished_at"] = pd.to_datetime(sp["finished_at"]).dt.tz_localize('UTC')
# 将 'started_at' 和 'finished_at' 转换为带 UTC 时区的 datetime8.1 聚合staypoint
sp, locs = sp.as_staypoints.generate_locations(
epsilon=50,
num_samples=2,
distance_metric="haversine",
agg_level="dataset",
n_jobs=-1
)

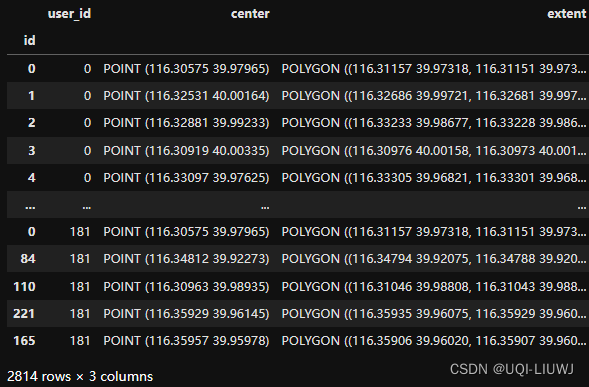
8.2 去除不在station里面的staypoint(因为这个任务是next station prediction)
sp = sp.loc[~sp["location_id"].isna()].copy()
8.3 station去重
不同user 可能共享一个location,相同位置的location只保留一个
locs = locs[~locs.index.duplicated(keep="first")]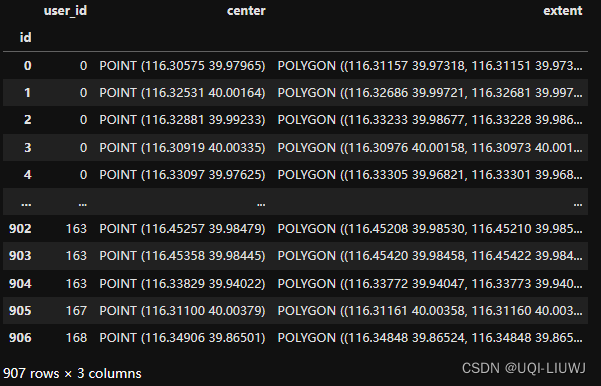

9 合并时间阈值内的staypoint
sp_merged = sp.as_staypoints.merge_staypoints(
triplegs=pd.DataFrame([]),
max_time_gap="1min",
agg={"location_id": "first"}
)
sp_merged如果两个停留点之间的最大持续时间小于1分钟,则进行合并
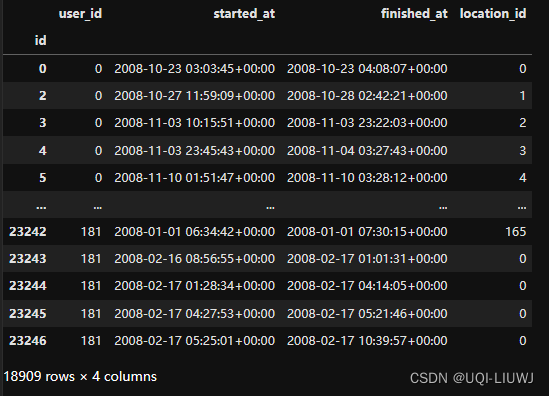
10 每个staypoint的持续时间
sp_merged["duration"] = (sp_merged["finished_at"] - sp_merged["started_at"]).dt.total_seconds() // 60
11 保存staypoint 记录
sp_merged.to_csv('geolife_processed_location_origintime_all.csv')12 添加和计算新的时间相关字段
12.1 _get_time
修改staypoint记录开始时间/结束时间,开始日期/结束日期的表达方式
def _get_time(df):
min_day = pd.to_datetime(df["started_at"].min().date())
#将 started_at 的最小日期(min_day)作为基准点,用于计算其他时间点相对于此日期的差异
df["started_at"] = df["started_at"].dt.tz_localize(tz=None)
df["finished_at"] = df["finished_at"].dt.tz_localize(tz=None)
df["start_day"] = (df["started_at"] - min_day).dt.days
df["end_day"] = (df["finished_at"] - min_day).dt.days
#计算 start_day 和 end_day 字段,这两个字段表示相对于 min_day 的天数差异。
df["start_min"] = df["started_at"].dt.hour * 60 + df["started_at"].dt.minute
df["end_min"] = df["finished_at"].dt.hour * 60 + df["finished_at"].dt.minute
#计算 start_min 和 end_min 字段,这些字段表示一天中的分钟数,用于精确到分钟的时间差异计算
df.loc[df["end_min"] == 0, "end_min"] = 24 * 60
#如果 end_min 等于 0,表示结束时间为午夜,为了避免计算错误,手动将其设置为 1440(即24小时*60分钟)
df["weekday"] = df["started_at"].dt.weekday
#计算 weekday 字段,表示 started_at 所在的星期几(0代表星期一,6代表星期日)
return df12.2 enrich_time_info
对每一个用户的记录,应用一次_get_time
def enrich_time_info(sp):
sp = sp.groupby("user_id", group_keys=False).apply(_get_time)
#使用 groupby 根据 user_id 对数据进行分组,并应用辅助函数 _get_time 处理每个组的数据。
sp.drop(columns={"finished_at", "started_at"}, inplace=True)
#删除 finished_at 和 started_at 列
sp.sort_values(by=["user_id", "start_day", "start_min"], inplace=True)
#对数据进行排序
sp = sp.reset_index(drop=True)
#
sp["location_id"] = sp["location_id"].astype(int)
sp["user_id"] = sp["user_id"].astype(int)
# final cleaning, reassign ids
sp.index.name = "id"
sp.reset_index(inplace=True)
return sp12.3 转换原先staypoint记录的时间属性
sp_time = enrich_time_info(sp_merged)
sp_time
13 拆分训练测试验证
13.0 辅助函数
13.0.1 根据日期拆分训练集、验证集、测试集
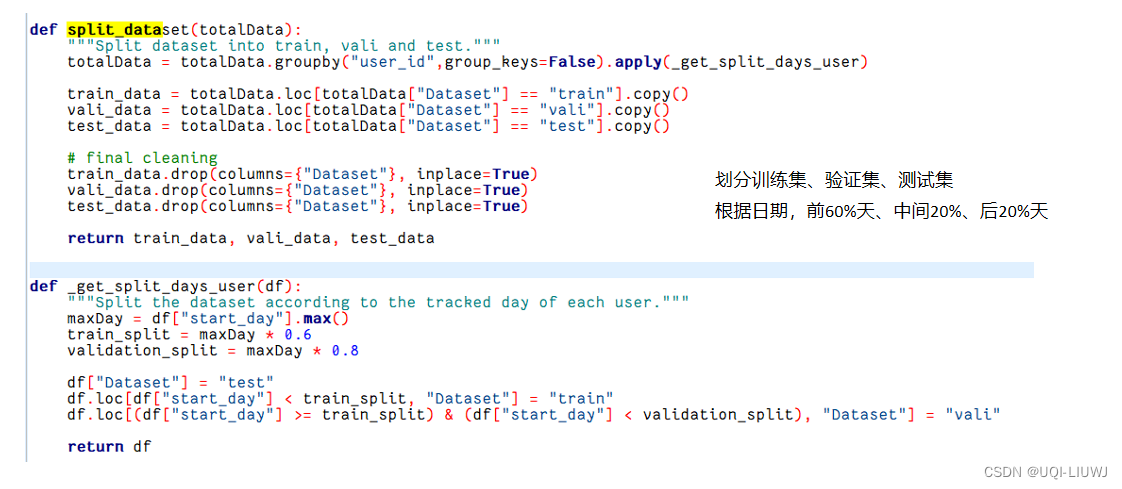
13.0.2 验证有效行id
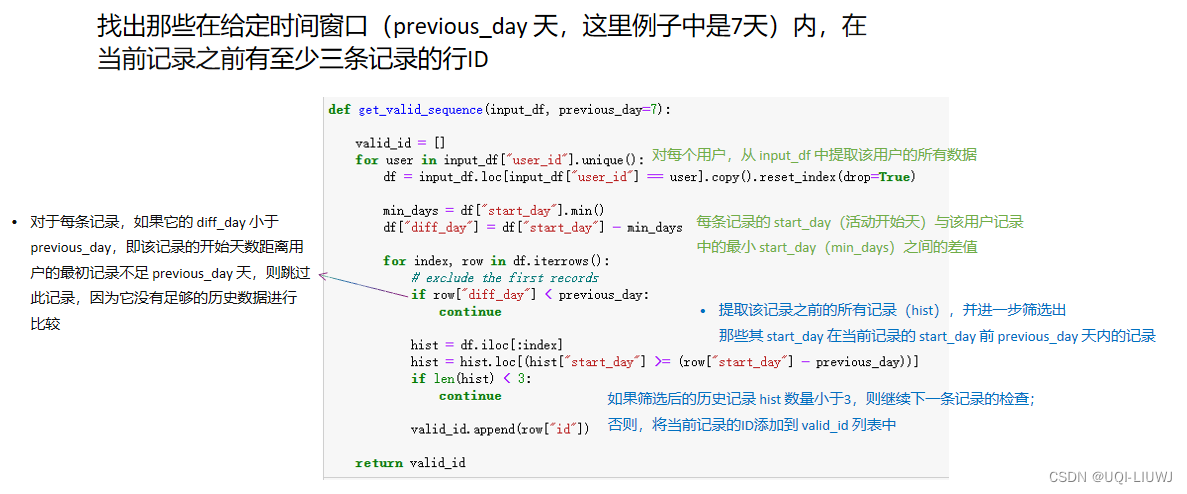
(这里我后续是把三条记录改成了五条【也就是3改成5就行】)
13.1 划分训练、验证、测试集
train_data, vali_data, test_data = split_dataset(sp_time)每一个user 前60%天 训练,中间20%天验证,后20%天测试


13.2 获取所有“valid”的行id
所谓valid,指的是那些在给定时间窗口(previous_day 天,这里例子中是7天)内,在当前记录之前有至少五条记录的行ID
valid_ids = get_valid_sequence(train_data)
valid_ids.extend(get_valid_sequence(vali_data))
valid_ids.extend(get_valid_sequence(test_data))
valid_ids 
筛选所有valid的行id
13.3 筛选train、valid、test中valid的行对应的user_id
valid_users_train = train_data.loc[train_data["id"].isin(final_valid_id), "user_id"].unique()
valid_users_vali = vali_data.loc[vali_data["id"].isin(final_valid_id), "user_id"].unique()
valid_users_test = test_data.loc[test_data["id"].isin(final_valid_id), "user_id"].unique()
valid_users_train
13.4 在train、test、valid上都有的user
valid_users = set.intersection(set(valid_users_train), set(valid_users_vali), set(valid_users_test))
len(valid_users)
#3513.4-5 (后补的一步)
此时这三个文件的user_id不是从1开始到35的,不连贯,所以一开始跑Mob-LLM的时候会有问题
添加这两步,再保存
user_id_dict=dict()
#目前的user-id和之后的user-id的映射
num=1
for i in valid_users:
user_id_dict[i]=num
num+=1
user_id_dict
'''
{0: 1,
128: 2,
2: 3,
3: 4,
4: 5,
11: 6,
12: 7,
13: 8,
14: 9,
140: 10,
144: 11,
17: 12,
22: 13,
153: 14,
25: 15,
30: 16,
35: 17,
163: 18,
39: 19,
167: 20,
41: 21,
42: 22,
52: 23,
62: 24,
68: 25,
71: 26,
73: 27,
74: 28,
84: 29,
85: 30,
96: 31,
112: 32,
115: 33,
119: 34,
126: 35}
'''train_data_valid_user['user_id']=train_data_valid_user['user_id'].apply(lambda x:user_id_dict[x])
train_data_valid_user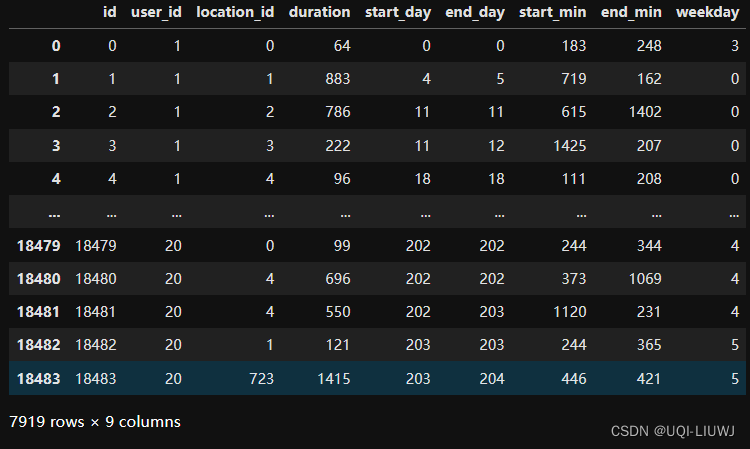
13.5 筛选对应的staypoint,并修改各列类型,然后保存之
13.5.1 训练集
train_data_valid_user=train_data[train_data['user_id'].isin(valid_users)]
train_data_valid_user
train_data_valid_user=train_data_valid_user.astype({
'user_id': int,
'location_id': int,
'duration': int,
'start_day': int,
'end_day': int,
'start_min': int,
'end_min': int,
'weekday': int})
train_data_valid_user 
train_data_valid_user.to_csv('processed_geolife_bj_train.csv')13.5.2 验证集
vali_data_valid_user=vali_data[vali_data['user_id'].isin(valid_users)]
vali_data_valid_user=vali_data_valid_user.astype({
'user_id': int,
'location_id': int,
'duration': int,
'start_day': int,
'end_day': int,
'start_min': int,
'end_min': int,
'weekday': int})
vali_data_valid_user.to_csv('processed_geolife_bj_vali.csv')
vali_data_valid_user 
13.5.3 训练集
test_data_valid_user=test_data[test_data['user_id'].isin(valid_users)]
test_data_valid_user=test_data_valid_user.astype({
'user_id': int,
'location_id': int,
'duration': int,
'start_day': int,
'end_day': int,
'start_min': int,
'end_min': int,
'weekday': int})
test_data_valid_user.to_csv('processed_geolife_bj_test.csv')
test_data_valid_user 
14 保存pkl格式的test file
和论文辅助笔记:LLM-MOB代码解读-CSDN博客 的test_file格式对齐:每一个用户过去7天的所有record【至少record数量大于5,就是一条合理的test record】
14.1 格式转化
transformed_data = []
for index, row in test_data_valid_user.iterrows():
user_id = row['user_id']
current_location = row['location_id']
current_day = row['start_day']
current_start_min = row['start_min']
current_weekday = row['weekday']
current_duration=row['duration']
#当前时刻的信息(ground-truth)
past_data =test_data_valid_user[
(test_data_valid_user['user_id'] == user_id) &
(test_data_valid_user['start_day'] >= current_day - 7) &
(test_data_valid_user['start_day'] < current_day)
]
#过去7天该用户的record
if len(past_data) < 5:
continue
#如果过去7天该用户的record数量小于5条,则不处理
entry = {
'X': past_data['location_id'].values,
'user_X': np.full(len(past_data), user_id),
'weekday_X': past_data['weekday'].values,
'start_min_X': past_data['start_min'].values,
'dur_X': past_data['duration'].values,
'diff': current_day - past_data['start_day'].values,
'Y': current_location,
'weekday_Y': int(current_weekday),
'start_min_Y': int(current_start_min),
'dur_Y':int(current_duration)
}
#
transformed_data.append(entry)
transformed_data
len(transformed_data)
# 300814.2 文件保存
import pickle
f=open('geolife_test_data.pkl','wb')
pickle.dump(transformed_data,f)
f.close()















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











