









PaddlePaddle实现LSGAN
#导入一些必要的包
import os
import random
import paddle
import paddle.nn as nn
import paddle.optimizer as optim
import paddle.vision.datasets as dset
import paddle.vision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
dataset = paddle.vision.datasets.MNIST(mode='train',
transform=transforms.Compose([
# resize ->(32,32)
transforms.Resize((32,32)),
# 归一化到-1~1
transforms.Normalize([127.5], [127.5])
]))
dataloader = paddle.io.DataLoader(dataset, batch_size=256,
shuffle=True, num_workers=4)
#参数初始化的模块
@paddle.no_grad()
def normal_(x, mean=0., std=1.):
temp_value = paddle.normal(mean, std, shape=x.shape)
x.set_value(temp_value)
return x
@paddle.no_grad()
def uniform_(x, a=-1., b=1.):
temp_value = paddle.uniform(min=a, max=b, shape=x.shape)
x.set_value(temp_value)
return x
@paddle.no_grad()
def constant_(x, value):
temp_value = paddle.full(x.shape, value, x.dtype)
x.set_value(temp_value)
return x
def weights_init(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and classname.find('Conv') != -1:
normal_(m.weight, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
normal_(m.weight, 1.0, 0.02)
constant_(m.bias, 0)
LSGAN
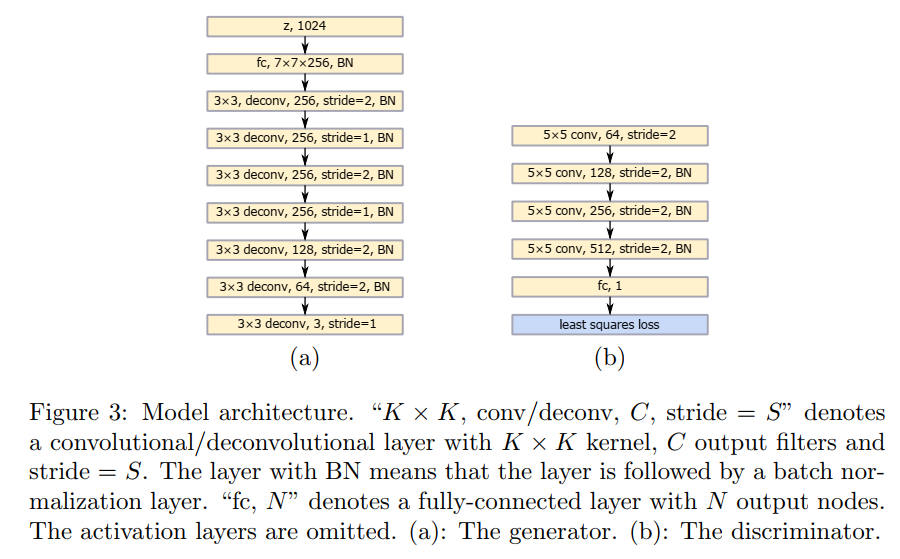
# Generator Code
class Generator(nn.Layer):
def __init__(self, ):
super(Generator, self).__init__()
self.gen = nn.Sequential(
# input is Z, [B, 100, 1, 1] -> [B, 64 * 4, 4, 4]
nn.Conv2DTranspose(100, 64 * 4, 4, 1, 0, bias_attr=False),
nn.BatchNorm2D(64 * 4),
nn.ReLU(True),
# state size. [B, 64 * 4, 4, 4] -> [B, 64 * 2, 8, 8]
nn.Conv2DTranspose(64 * 4, 64 * 2, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(64 * 2),
nn.ReLU(True),
# state size. [B, 64 * 2, 8, 8] -> [B, 64, 16, 16]
nn.Conv2DTranspose( 64 * 2, 64, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(64),
nn.ReLU(True),
# state size. [B, 64, 16, 16] -> [B, 1, 32, 32]
nn.Conv2DTranspose( 64, 1, 4, 2, 1, bias_attr=False),
nn.Tanh()
)
def forward(self, x):
return self.gen(x)
netG = Generator()
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)
# Print the model
print(netG)
Generator(
(gen): Sequential(
(0): Conv2DTranspose(100, 256, kernel_size=[4, 4], data_format=NCHW)
(1): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(2): ReLU(name=True)
(3): Conv2DTranspose(256, 128, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(4): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(5): ReLU(name=True)
(6): Conv2DTranspose(128, 64, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(7): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(8): ReLU(name=True)
(9): Conv2DTranspose(64, 1, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(10): Tanh()
)
)
class Discriminator(nn.Layer):
def __init__(self,):
super(Discriminator, self).__init__()
self.dis = nn.Sequential(
# input [B, 1, 32, 32] -> [B, 64, 16, 16]
nn.Conv2D(1, 64, 4, 2, 1, bias_attr=False),
nn.LeakyReLU(0.2),
# state size. [B, 64, 16, 16] -> [B, 128, 8, 8]
nn.Conv2D(64, 64 * 2, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(64 * 2),
nn.LeakyReLU(0.2),
# state size. [B, 128, 8, 8] -> [B, 256, 4, 4]
nn.Conv2D(64 * 2, 64 * 4, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(64 * 4),
nn.LeakyReLU(0.2),
# state size. [B, 256, 4, 4] -> [B, 1, 1, 1]
nn.Conv2D(64 * 4, 1, 4, 1, 0, bias_attr=False),
# 这里为需要改变的地方
# nn.BatchNorm2D(256),
# nn.LeakyReLU(0.2),
# # state size. [B, 256, 1, 1] -> [B, 1]
# nn.Linear(256, 1)
)
def forward(self, x):
return self.dis(x)
netD = Discriminator()
netD.apply(weights_init)
print(netD)
Discriminator(
(dis): Sequential(
(0): Conv2D(1, 64, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(1): LeakyReLU(negative_slope=0.2)
(2): Conv2D(64, 128, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(3): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(4): LeakyReLU(negative_slope=0.2)
(5): Conv2D(128, 256, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(6): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(7): LeakyReLU(negative_slope=0.2)
(8): Conv2D(256, 1, kernel_size=[4, 4], data_format=NCHW)
)
)
# Initialize BCELoss function
# 这里为需要改变的地方
loss = nn.MSELoss(reduction='mean')
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = paddle.randn([32, 100, 1, 1], dtype='float32')
# Establish convention for real and fake labels during training
real_label = 1.
fake_label = 0.
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(parameters=netD.parameters(), learning_rate=0.0002, beta1=0.5, beta2=0.999)
optimizerG = optim.Adam(parameters=netG.parameters(), learning_rate=0.0002, beta1=0.5, beta2=0.999)

losses = [[], []]
#plt.ion()
now = 0
epochs = 100
for pass_id in range(epochs):
for batch_id, (data, target) in enumerate(dataloader):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
optimizerD.clear_grad()
real_img = data
bs_size = real_img.shape[0]
label = paddle.full((bs_size, 1, 1, 1), real_label, dtype='float32') # set 1
real_out = netD(real_img)
errD_real = loss(real_out, label)
errD_real.backward()
noise = paddle.randn([bs_size, 100, 1, 1], 'float32')
fake_img = netG(noise)
label = paddle.full((bs_size, 1, 1, 1), fake_label, dtype='float32') # set 0
fake_out = netD(fake_img.detach())
errD_fake = loss(fake_out, label)
errD_fake.backward()
optimizerD.step()
optimizerD.clear_grad()
errD = 0.5 * errD_real + 0.5 * errD_fake
losses[0].append(errD.numpy()[0])
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
optimizerG.clear_grad()
noise = paddle.randn([bs_size, 100, 1, 1],'float32')
fake = netG(noise)
label = paddle.full((bs_size, 1, 1, 1), real_label, dtype=np.float32) # set 1
output = netD(fake)
errG = 0.5 * loss(output,label)
errG.backward()
optimizerG.step()
optimizerG.clear_grad()
losses[1].append(errG.numpy()[0])
############################
# visualize
###########################
if batch_id % 200 == 0:
generated_image = netG(noise).numpy() # N C H W
imgs = []
plt.figure(figsize=(10, 10))
try:
for i in range(10):
image = generated_image[i].transpose() # H W C
# image = np.where(image > 0, image, 0) # ?生成器用了tanh又截取 而不用sigmoid 不理解为什么
image = image.transpose((1, 0, 2)) # H W C -> W H C
plt.subplot(10, 10, i + 1)
plt.imshow(image[...,0], vmin=-1, vmax=1)
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplots_adjust(wspace=0.1, hspace=0.1)
msg = 'Epoch ID={0} Batch ID={1} \n\n D-Loss={2} G-Loss={3}'.format(pass_id+1, batch_id, errD.numpy()[0], errG.numpy()[0])
print(msg)
plt.suptitle(msg, fontsize=20)
plt.draw()
plt.savefig('{}/{:04d}_{:04d}.png'.format('work', pass_id, batch_id), bbox_inches='tight')
plt.pause(0.01)
except IOError:
print(IOError)
paddle.save(netG.state_dict(), "work/generator.params")
Epoch ID=1 Batch ID=0
D-Loss=1.9358999729156494 G-Loss=0.4397525489330292
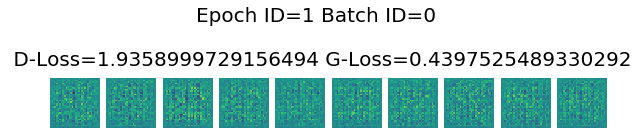
Epoch ID=1 Batch ID=200
D-Loss=0.14011457562446594 G-Loss=0.5309092402458191
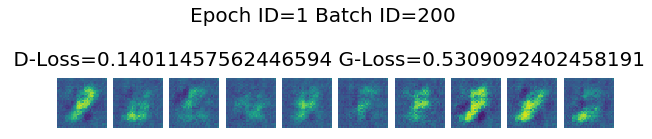
Epoch ID=100 Batch ID=200
D-Loss=0.010250557214021683 G-Loss=0.5495871305465698
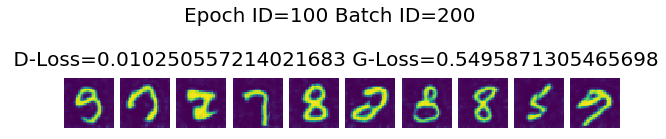
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.














 4489
4489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









