







 本文介绍了二分类任务中混淆矩阵的概念及TP、TF、FP、FN的具体含义,并基于混淆矩阵详细解释了f1值、精确度、召回率、准确率及MCC等评估指标的计算方法与应用价值。
本文介绍了二分类任务中混淆矩阵的概念及TP、TF、FP、FN的具体含义,并基于混淆矩阵详细解释了f1值、精确度、召回率、准确率及MCC等评估指标的计算方法与应用价值。
1 介绍 TP, TF, FP, FN
TP, TF, FP, FN 是针对二分类任务预测结果得到的值,这四个值构成了混淆矩阵;
如下图的混淆矩阵:
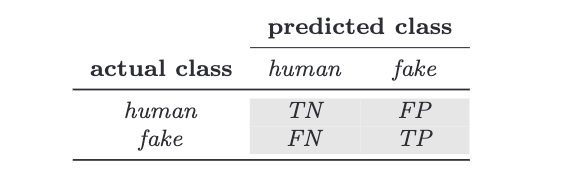
左侧表示真实的标签,human标记为0; fake标记为1;
右侧部分predicted class表示预测的标签;
因此: TN表示(True -- 预测正确, Negitive, 预测为0)预测标签为0(human),预测正确;
FN表示(False -- 预测错误,Negitive, 预测为0)预测标签为0(human),预测错误;
FP表示 (False -- 预测错误, Positive, 预测为1)预测标签为1(fake),预测错误;
TP表示(True -- 预测正确, Positive, 预测为1)预测标签为1(fake),预测正确;
2 介绍f1, precision, recall, acc, MCC
f1, precision, recall, acc, MCC是由上述混淆矩阵的四个值计算得到的;
计算公式:
acc预测的真实结果,总体数据中,有多少数据被预测正确了;
recall 预测为bot且预测正确的数量占全部预测为bot数量的比例;
Precision 预测为bot且预测正确的数量占实际为bot数量的比例;
MCC = ![]()
f1 和 Mcc为综合评价指标;
上述五个指标优劣分析:
准确度(acc)衡量有多少样本在两个类中被正确识别,但它不表示一个类能否被另一个类更好地识别;
高精确度(Precision)表明许多被识别为1(bot)的样本被正确识别,但它没有提供有关尚未识别的1(bot)样本的任何信息;
该信息由召回指标(recall)提供,表示在整个1(bot)样本集中有多少样本被正确识别:低召回意味着许多1(bot)样本未被识别;
F1 和 MCC 试图在以一个单一的值中传达预测的质量,并结合其他指标。
MCC 被认为是 F1 的无偏版本,因为它使用了混淆矩阵的所有四个元素。 MCC 值接近 1 表示预测非常准确;接近 0 的值意味着预测并不比随机猜测好,接近 -1 的值意味着预测与真实类别严重不一致。

















 4139
4139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









