







nn.MultiheadAttention
该模块兼顾了 self-attention 和 cross-attention;
是构成 nn.transformer 的核心算子;
首先看其接口文档:
CLASStorch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True,
add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None, batch_first=False,
device=None, dtype=None)参数解释:
embed_dim: 样本序列token的嵌入维度;
num_heads: 并行注意力头的数量;
kdim: 注意力中key的维度;
vdim: 注意力中value的维度;
forward() 参数:
forward(query, key, value, key_padding_mask=None, need_weights=True,
attn_mask=None, average_attn_weights=True)参数解释:
query: 含有batch时,其shape为(L,N,Eq), 这里的L表示target embedding_dim, N 表示 batch size, Eq = embed_dim;
key: 含有batch时,其shape为(S,N,Ek), 这里的S表示source embedding_dim, N 表示 batch size, Ek = kdim;
value: 含有batch时,其shape为(S,N,Ev), 这里的S表示source embedding_dim, N 表示 batch size, Ev = vdim;
average_attn_weights : 返回的attention weights,默认返回各头的平均值;
通过上述参数的解释,可以看到K, V是来自同一个来源,对应于transformer中的encoder -- shape对应于 source embedding_dim;
Q 是另外一个来源,对应于transformer中的decoder -- shape对应于 target embedding_dim;
也是cross-attention使用的;
self-attention使用:
在forward()中的, query、key 和 value 是相同维度的张量,即: embed_dim = kdim = vdim;
forward()中的计算流程:
首先初始化![]() ,
,
![]()
![]()
![]()
之后使用 ![]()
![]()
![]()
![]()
最后得到返回值,也就是average_attn_weights:
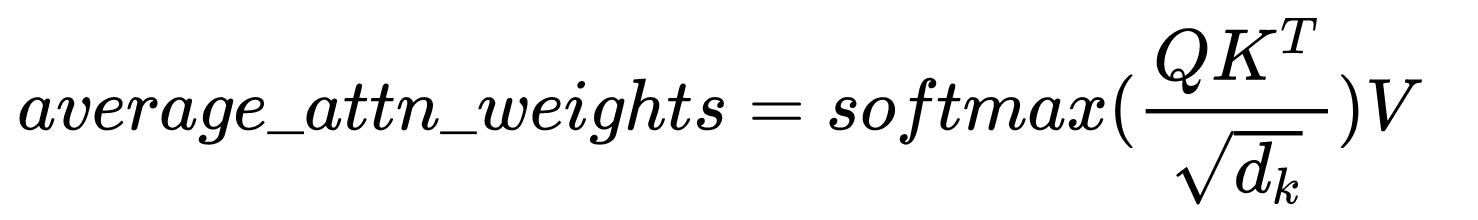
对应的维度解释:
N 即 batch size提到最前面,然后做后两维的转置;
![]()
![]()
对于V,N提前:
![]()
则最后的维度为:

通过上述计算就可以得到最终的attention weights output
参考视频:[pytorch模型拓扑结构] nn.MultiheadAttention, init/forward, 及 query,key,value 的计算细节_哔哩哔哩_bilibili

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









