







代码链接:GitHub - FraudDetection/FRAUDRE
目录
摘要——欺诈检测的目的是区分欺诈者和正常用户。在图形/网络环境中,欺诈者和普通用户都被建模为节点,这些节点之间的连接被表示为边。欺诈者通常会尝试用“正常”行为来伪装自己,例如,故意与正常用户建立许多联系。这种伪装本质上使它们的外观与正常的本质不一致,并导致图中的不一致。
在本文中,我们研究了这些图形不一致的三个方面:特征、拓扑和关系。迄今为止,基于图形的欺诈检测器在融合不同类型的不一致信息方面表现出相当有限的能力。除此之外,还有另一个失衡问题需要克服。这是因为欺诈者通常只占所有用户的很小一部分。为了实现一种有前途的能力,即双重抵抗图的不一致和不平衡,我们提出了一种基于图神经网络的新欺诈检测模型 FRAUDRE。大量实验比较了两个真实世界数据集 Amazon 和 YelpChi 上的八个最新基线,证明了 FRAUDRE 的优越性。
介绍:
为了绕过欺诈检测系统,欺诈者经常以他们认为使他们看起来“正常”的方式伪装自己 [10],[14]。但他们的外表并不符合正常人的本质。事实上恰恰相反;它们的存在会导致不一致,如果您知道要寻找什么,就可以检测到这些不一致。如图 1 所示,图形不一致可以通过三种方式表现出来:
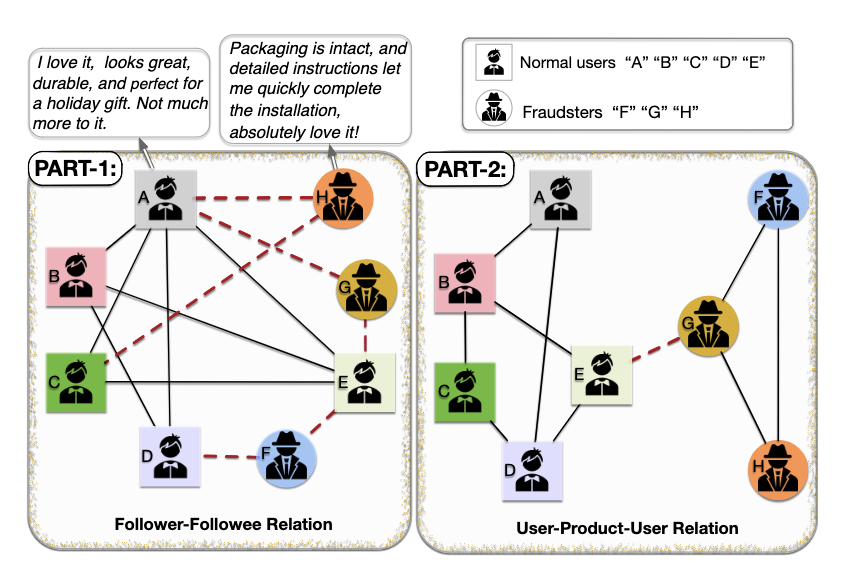
(图不一致问题的一个示例。从一个在线产品审查平台中提取出5名普通用户和3名欺诈者。如图1所示,用户及其对产品的评论分别视为节点和节点特性。通过从从关系可以建立节点之间的图形拓扑。在这种关系下,如果一个用户在在线评论平台上跟随另一个用户,那么他们之间就有一个边缘。特征不一致: 普通用户和欺诈者,有不同的标签,但有相似的特征。例如,为了掩盖怀疑,当欺诈者“ H”为一个产品发布虚假的积极评价时,他模仿普通用户“ A”的语气。因此,“ H”的标签具有不一致的特征。拓扑不一致: 与普通用户之间的密切关系不同,欺诈者与其同伙的关系很少。在这里,诈骗者“ F”、“ G”和“ H”与普通用户建立了许多联系,但彼此之间没有联系。除了跟随者-跟随者关系之外,第2部分所示,还可以基于用户-产品-用户关系构建用户之间的新拓扑,在这种关系中,已经评审过相同产品的用户被连接起来。关系不一致: 不同于欺诈者与普通用户紧密联系的跟随者-跟随者关系,在用户-产品-用户关系下,欺诈者“ F”、“ G”和“ H”只彼此形成链接,很少与普通用户联系。)
特征不一致,拓扑不一致,关系不一致。此外,欺诈检测还面临图不平衡的问题,即欺诈者与正常用户在数量上的分布高度倾斜。这主要是因为,在现实中,诈骗者的数量远远少于普通用户。以 Amazon.com 的真实世界数据集 Amazon [15] 为例,只有 9.5% 的用户是欺诈者,而其他用户是正常的。
图神经网络 (GNN) [16]-[18] 目前受到关注,因为它们在图学习任务(尤其是节点分类)方面表现出色。通过聚合邻里信息。它们在符合两个特定假设的图上表现良好:首先,同质性假设,其中相邻节点具有相似的特征并且属于同一类 [19];其次,平衡假设,要求不同类别的样本数量接近相等[20]。
图的不一致和不平衡违反了上述两个假设,并为利用 GNN 进行欺诈检测提出了四个挑战。特征不一致导致了第一个挑战,即具有相似特征的节点很可能属于不同的类。第二个挑战是由伪装欺诈者和正常用户位于相似社区的拓扑不一致问题引起的。由于 GNN 中的邻域聚合操作会将正常用户的特征与欺诈者的特征进行聚合,因此直接使用 GNN 进行欺诈检测实际上会使欺诈者更难被发现。关系不一致带来的第三个挑战是如何全面整合在不同关系下学习的节点表示/嵌入以改进欺诈检测。第四个挑战是现有 GNN 中的损失函数可能由多数类样本(即普通用户)主导。因此,该模型可能不适合少数类样本,即欺诈者。
为了应对这些挑战并改进基于图的欺诈检测,我们提出了 FRAUDRE,它对图的不一致和不平衡具有双重抵抗力。 FRAUDRE 由四个模块组成:1)一个图形不可知的嵌入模块,它通过编码他们的属性信息来代表所有用户; 2)欺诈感知图卷积模型,旨在嵌入图拓扑以表示相邻用户的差异性; 3)中间表示组合模块连接用户的所有中间嵌入以获得他们的最终表示; 4)面向不平衡的分类模块,消除了对大量正常用户的训练偏差。 FRAUDRE将以上四个模块统一成一个基于GNN的欺诈检测框架。
大多数基于 GNN 的欺诈检测器直接对节点属性应用邻域聚合操作。这样一来,在模型训练之初就大大降低了欺诈者的疑心。这就是为什么所提出的 FRADURE 利用第一个与图形无关的嵌入模块来学习正常用户和欺诈者之间的区别表示的原因。随后,第二个欺诈感知图卷积模块进一步放大了正常用户和欺诈者之间的差异。
主要贡献总结如下:
鲁棒性:FRAUDRE 在不修改原始图拓扑结构的情况下抵抗图不一致性问题;
概括性:面向不平衡的分类模块可以扩展到其他基于gnn的欺诈检测器中,并且可以充分建模少数类分布,具有理论保证。
有效性:对两个真实世界数据集(即 Amazon 和 YelpChi)的实验证明了 FRAUDRE 在检测欺诈者方面的有效性。
方法
在 FRAUDRE 框架中,四个不同的模块被统一到一个 GNN 中,三层由一个拓扑无关的嵌入层和两个图卷积层组成。 FRAUDRE 的流程如图 2 所示。第一个模块由拓扑不可知的密集层组成,学习节点的第一层表示。为了进一步嵌入不同关系下的丰富结构信息,第二个模块由两个图卷积层组成,聚合来自邻域节点和邻域差异的信息。第三个中间表示组合模块接下来连接前三个神经网络层的所有嵌入输出。最后,第四个面向不平衡的分类模块检测到欺诈者注意到类别分布不平衡。
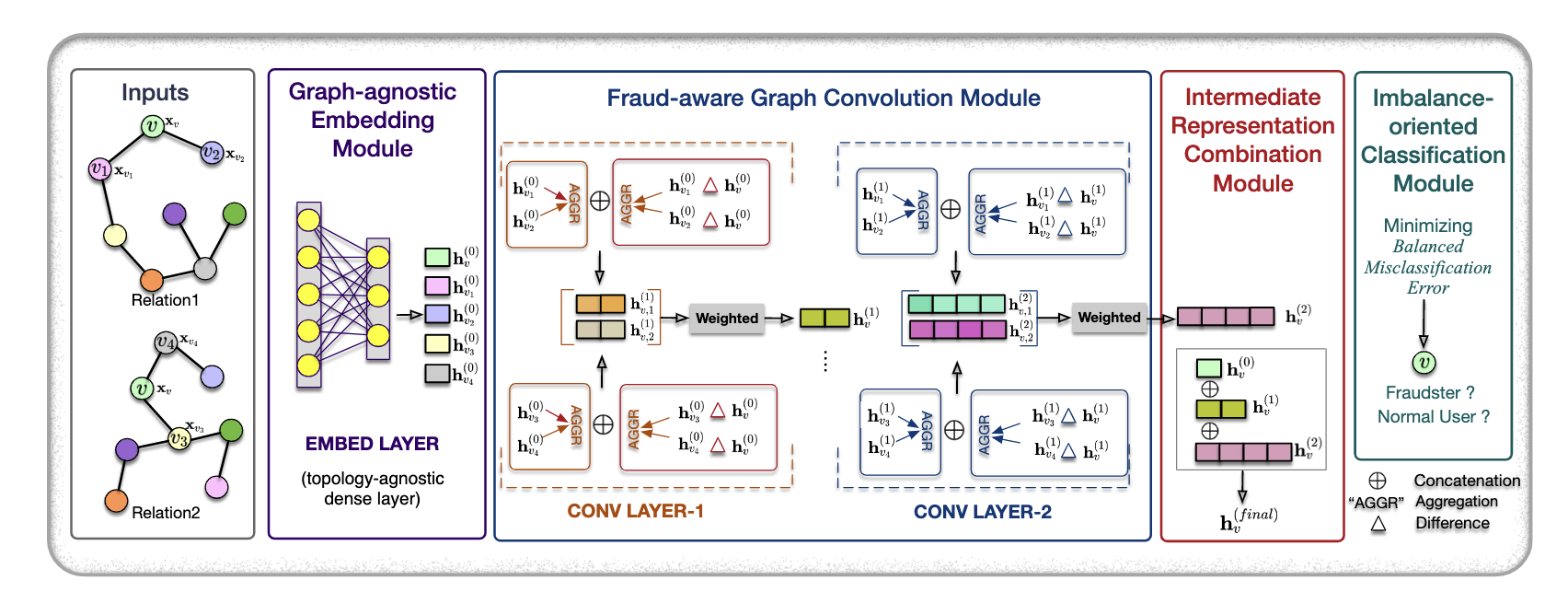
(欺诈的框架。 FRAUDRE 以具有两个关系的多关系图为输入,预测节点 v 的标签。v1 和 v2,v3 和 v4 是 v 在 Relation1 和 Relation2 建立的拓扑中的一跳邻居,分别。首先,与拓扑无关的密集层(即 EMBED LAYER)在两种关系下学习节点 v 及其单跳邻居的第一层嵌入。其次,在每个关系下,欺诈感知图卷积模块通过两个图卷积层(即 CONV LAYER-1 和 CONV LAYER-2)学习节点嵌入 h(l) v,r,其中 r ∈ {1, 2}, l ∈ {1, 2}。具体来说,在每个图卷积层的末端,h(l) v 是通过 h(l) v,1 和 h(l) v,2 的加权求和生成的。第三,连接中间表示组合模块通过EMBED LAYER、CONV LAYER-1和CONV LAYER-2输出的h(0) v 、h(1) v 和h(2) v 得到最终表示h(final) v , 分别。通过最小化平衡误分类误差,节点 v 的类别最终由面向不平衡的分类模块预测。)
A. 与图无关的嵌入模块
欺诈者的属性与图中的正常用户相似,但特征不一致。因此,有必要在模型训练开始时学习针对伪装欺诈者和正常用户的判别嵌入。我们提出了一个与拓扑无关的密集层来学习节点的第一层嵌入。与拓扑无关的密集层不依赖于任何拓扑信息,它只对节点属性进行编码。公式是:
![]()
在被这个模块表示之后,伪装欺诈者与相邻的正常用户有不同的表示。然而,相比之下,普通用户仍然与他们的大多数邻居保持着高度的相似性。值得强调的是,大多数普通用户的邻居仍然是普通用户,即使欺诈者故意通过与许多普通用户建立联系来伪装自己。欺诈者通常是众多用户中的一员。因此,该模块为通过拓扑信息进一步放大正常用户和欺诈者之间的差异提供了良好的基础。
B.欺诈感知图卷积模块
拓扑不一致意味着 GNN 中的邻域聚合操作会将大量正常用户的特征聚合到欺诈者身上,如果发生这种情况,欺诈者将无法区分。然而,可以引入基于图无关嵌入模块输出的判别嵌入的邻域差异聚合操作,以进一步强调普通用户和伪装欺诈者之间的差异。、
由于普通用户和未伪装的欺诈者仍然满足同质假设,因此需要保留传统 GNN 中的邻域聚合操作。该模块中的图卷积层可以表示为:
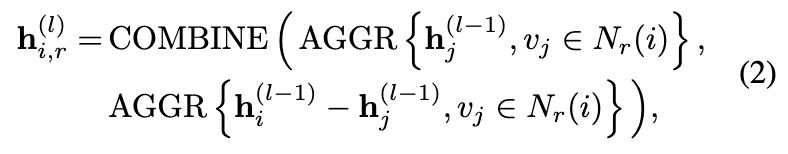
其中 h(l) i,r 是节点 vi 在第 r 个关系下学习到的第 l 层嵌入,并且 l ∈ 1, ..., L and r ∈ 1, ..., R. Nr (i ) 是关系 r 下节点 vi 的 1 跳邻域集。 “AGGR”和“COMBINE”分别代表平均聚合和级联。
由于关系一致性问题,不同关系的贡献可能会有很大差异。第 l 层节点嵌入 h(l) i 是通过加权求和学习的,
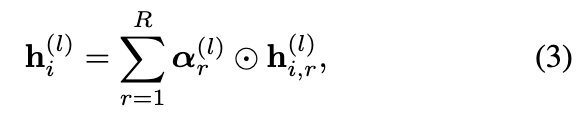
其中表示 Hadamard 乘积,α(l) r 是学习向量,表示关系 r 对不同嵌入维度的贡献。
C. 中间表示组合模块
根据对图卷积运算的研究[22],不同神经网络层输出的节点表示具有不同的平滑度。少数类样本在节点表示的未平滑分量中具有高能量。然而,大多数类样本,例如普通用户,在节点表示的平滑分量中具有高能量 [19]。因此,结合不同神经网络层输出的中间表示可以进一步改进欺诈检测。这样,可以将具有不同平滑度的信息嵌入到最终的节点表示中。公式是:
![]()
D. 面向不平衡的分类模块
不平衡的类分布导致大多数基于 GNN 的欺诈检测器倾向于过度拟合普通用户而欠拟合欺诈者。这是因为大多数基于 GNN 的欺诈检测器采用标准的交叉熵损失作为损失函数。在这里,考虑输入是 x ∈ X,标签 y ∈ Y,y 的值为 0 或 1。标准交叉熵 f SCE 的表示是
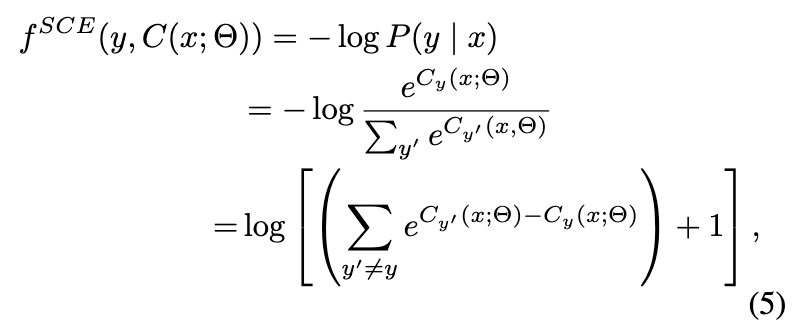
其中 Θ 是分类器 C 的模型参数。f SCE 通过最小化错误分类误差来训练 C。那是,
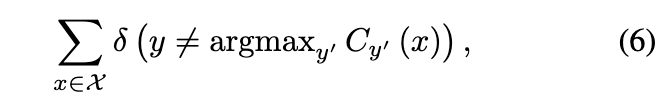
其中δ是误分类误差的计算形式。
然而,在这样的设置下,当欺诈检测器将所有样本分类为正常用户时,仍然可以实现较低的误分类错误 [15]、[36]。为了解决这个问题,另一种方法是最小化每个类中的平均错误分类错误率 [37],公式为:
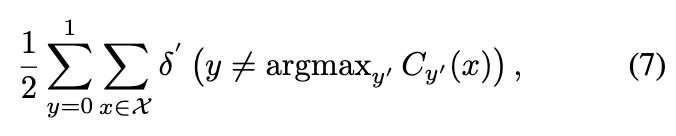
其中(7) δ′是错误率的计算形式, 被命名为平衡错误分类错误。根据[15]中的定理1,最小化平衡误分类误差等于估计输入x的标签y,假设:
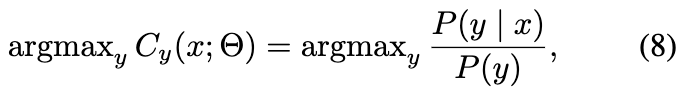
其中 P (y) 是类先验,即训练集的经验类频率。
这种情况不同于标准的交叉熵损失 fSCE 。如方程式(5)所示, fSCE 通过假设估计节点的标签:
![]()
通过重新制定方程式 (8), 我们得到,
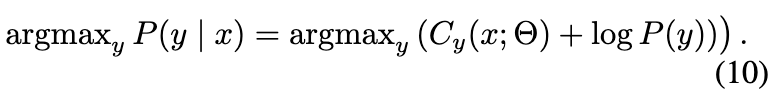
用 softmax 对 P(y|x) 建模,我们有面向不平衡分布的损失函数 f*,即
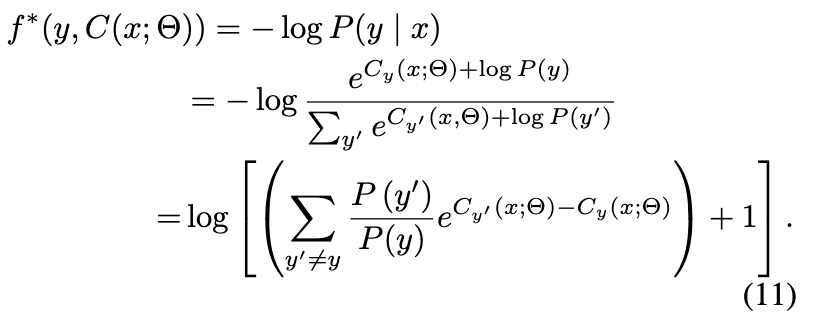
学习的权重矩阵 ![]() 用于完成
用于完成 ![]() 上的最终特征变换。基于新提出的面向不平衡分布的损失f*,FRAUDRE的损失函数定义为:
上的最终特征变换。基于新提出的面向不平衡分布的损失f*,FRAUDRE的损失函数定义为:
![]()
训练过程如算法 1 所示

效果
我们对两个真实世界的数据集进行了一组实验,以调查以下问题:
• RQ1:FRAUDRE 是否优于最新的基线算法?
• RQ2:FRAUDRE 能否为普通用户和欺诈者学习有区别的嵌入?
• RQ3:FRAUDRE 是否受益于所有四个模块?
• RQ4:FRAUDRE 是否对超参数敏感?
• RQ5:FRAUDRE 的运行效率如何?
A. 实验设置
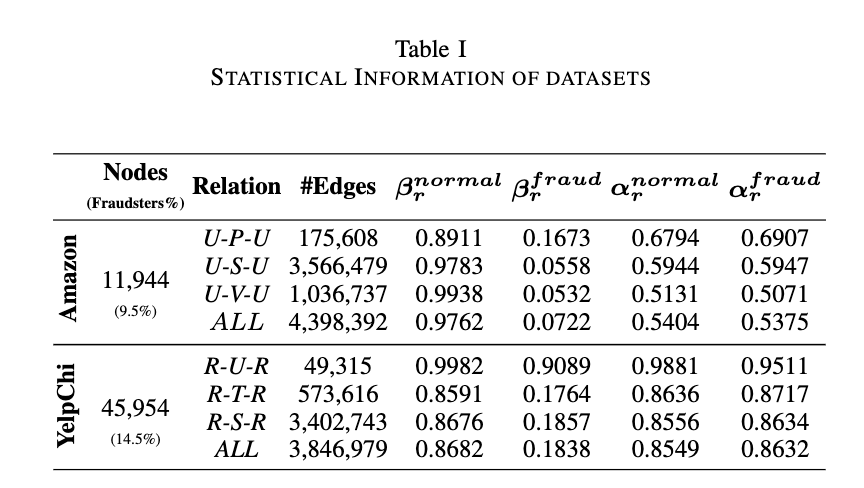
数据集:我们选择了 Amazon [38] 和 YelpChi [39] 数据集来验证 FRAUDRE 的性能。这两个数据集的统计信息如表一所示。第一个数据集亚马逊由用户及其对乐器的评论组成。用户被建模为节点,这些节点之间存在三种不同类型的关系。具体来说,在U-P-U关系下,评论过一个或多个相同产品的用户被链接起来。U-S-U 关系链接在 7 天内至少发布了一个相同评级(1-5 星)的用户。在最后一个关系 U-V-U 下,链接了评论在 TF-IDF 相似度方面排名前 5% 的用户。此外,将不同关系下的所有拓扑合并在一起,形成表 I 中的关系 ALL。将超过 80% 或低于 20% 的有用投票的用户分别标记为正常用户和欺诈者。
同样,YelpChi 数据集包括餐厅和酒店的合法评论和垃圾评论。评论被视为节点,节点之间也存在三种类型的关系。具体来说,在R-U-R关系下,同一用户提供的评论是有联系的。对于 R-S-R 关系,如果两条评论对一个项目给出相同的评分,则它们将被链接。在 R-T-R 关系下,在同一月发布的同一项目的评论之间建立链接。
2)基线
GCN [17]:这种谱 GNN 通过在谱域中扩展图卷积来表示节点。
• GAT [21]:该方法采用注意力机制并构建图形注意力神经网络以增强嵌入性能。
• GraphSAGE [18]:这是一种空间 GNN 方法,它基于节点的自我特征和聚合的邻域特征来归纳表示节点。
• GEM [5]:该检测器基于GCN 构建,专用于恶意帐户检测。
• FdGars [2]:与GEM 类似,FdGars 也是基于GCN 但旨在垃圾邮件检测。
• Player2Vec [11]:这个基于GCN 的欺诈检测器专用于异构网络。
• GraphConsis [9]:这种基于 GNN 的欺诈检测器考虑了图的不一致性,并且是通过基于固定阈值过滤节点的不同邻居来实现的。
• CARE-GNN [10]:这种方法是防伪装的。它通过自适应阈值过滤节点的邻居以增强图卷积过程。
在这些基线中,GCN、GAT、GraphSAGE和FdGars的目标图以定义1为特征(即表1中的ALL),而GEM、Play2Vec、GraphConsis、CARE-GNN和FRAUDRE运行在多关系图上。
3)实验设置和实现:在 FRAUDRE 中,我们将图不可知嵌入模块中的嵌入大小设置为 64,图卷积层数设置为 2,批量大小设置为 256(亚马逊)和 1024(YelpChi)。对于模型优化,我们采用广泛使用的 Adam [40] 优化器并将学习率设置为 Amazon 的 0.1 和 YelpChi 的 0.001。
GCN、GAT 和 GraphSAGE 是使用相应作者发布的源代码实现的。并且,我们通过用于欺诈检测的开源工具箱实施了 GEM、FdGars、Player2Vec、GraphConsis 和 CARE-GNN1。 FRAUDRE 的代码和数据集可在 GitHub2 上获得。所有实验均由 Python 3.7、1 个 NVIDIA Volta GPU 和 384G DRAM 进行。
4) 评估指标:我们采用 AUC、Macro-Recall 和 Macro-F1 作为评估指标。 AUC表示随机选择欺诈者的预测概率,其排名高于普通用户。 Macro-Recall 衡量检测器分别从真实欺诈者和正常用户总数中检测到的真实欺诈者和真实正常用户比例的未加权平均值。 F1-score 是召回率和精确率之间的权衡,Macro-F1 是正常用户和欺诈者 F1-score 的未加权平均值。
B. 图形不一致和不平衡的证据
首先,我们验证了拓扑和关系不一致的存在。采用了两个指标——![]() 和
和 ![]() ,它们表示欺诈者和正常用户与其在关系 r 下的一跳邻居的平均标签相似度。公式是:
,它们表示欺诈者和正常用户与其在关系 r 下的一跳邻居的平均标签相似度。公式是:
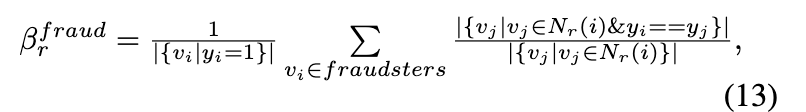

欺诈者的低平均标签相似度得分 βfraud r (→ 0) 意味着欺诈者已成功地在关系 r 下的拓扑中伪装自己,即欺诈者的大多数单跳邻居都是普通用户。另一方面,高分 βfraud r (→ 1) 意味着欺诈者在很大程度上未能伪装自己,并且与同伙关系密切。
拓扑不一致。如表1所示,两个数据集的βfraud r分数几乎都低于0.2(除了YelpChi中的r - u - r),这意味着欺诈者在这些关系上与正常用户有大量的联系。在所有关系下,正常用户的 βnormal r 得分均高于 0.85。因此,无论关系如何,普通用户之间的联系总是非常密集
关系不一致。如表一所示,欺诈者未能在 YelpChi 的 R-U-R 中伪装自己(R-U-R 下的 βfraud r 为 0.9089),但他们成功地伪装了另外两个关系 R-T-R 和 R-S-R(R-T-R 和 R-S-R 下的 βfraud r分别为 0.1764 和 0.1857)。
其次,我们分析了特征不一致。在这一步中,我们采用了两个指标,αfraud r 和 αnormal r ,来衡量相邻节点之间的平均特征相似度。我们特别调查了邻居节点,因为除了 YelpChi 中基于 R-U-R 的拓扑之外,大多数欺诈者的一跳邻居都是正常用户。两个指标被制定为:
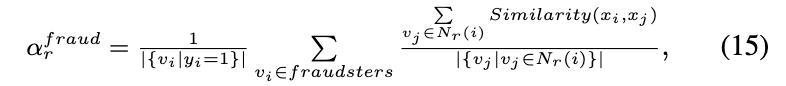
![]()
其中余弦相似度用作相似度度量。
特征不一致。如表一所示,欺诈者的属性与他们附近的正常用户相似。例如,在 R-T-R 和 R-S-R 下,αfraud r 分别为 0.8717 和 0.8634。在这两种关系中,欺诈者的大多数一跳邻居都是普通用户。值得注意的是,普通用户与相邻的普通用户保持着高度相似性。
在图失衡问题上,亚马逊和 YelpChi 分别只有 9.5% 和 14.5% 的节点是欺诈者。
C.性能比较(RQ1)
分别在表II和III中分别报道了Amazon和Yelpchi上提出的Fradure和基线的实验结果。我们将培训样本的百分比从10%变化到40%,并观察到,在大多数训练比例下,欺诈者在指标上的表现都优于所有八个基准。实验结果的进一步分析如下
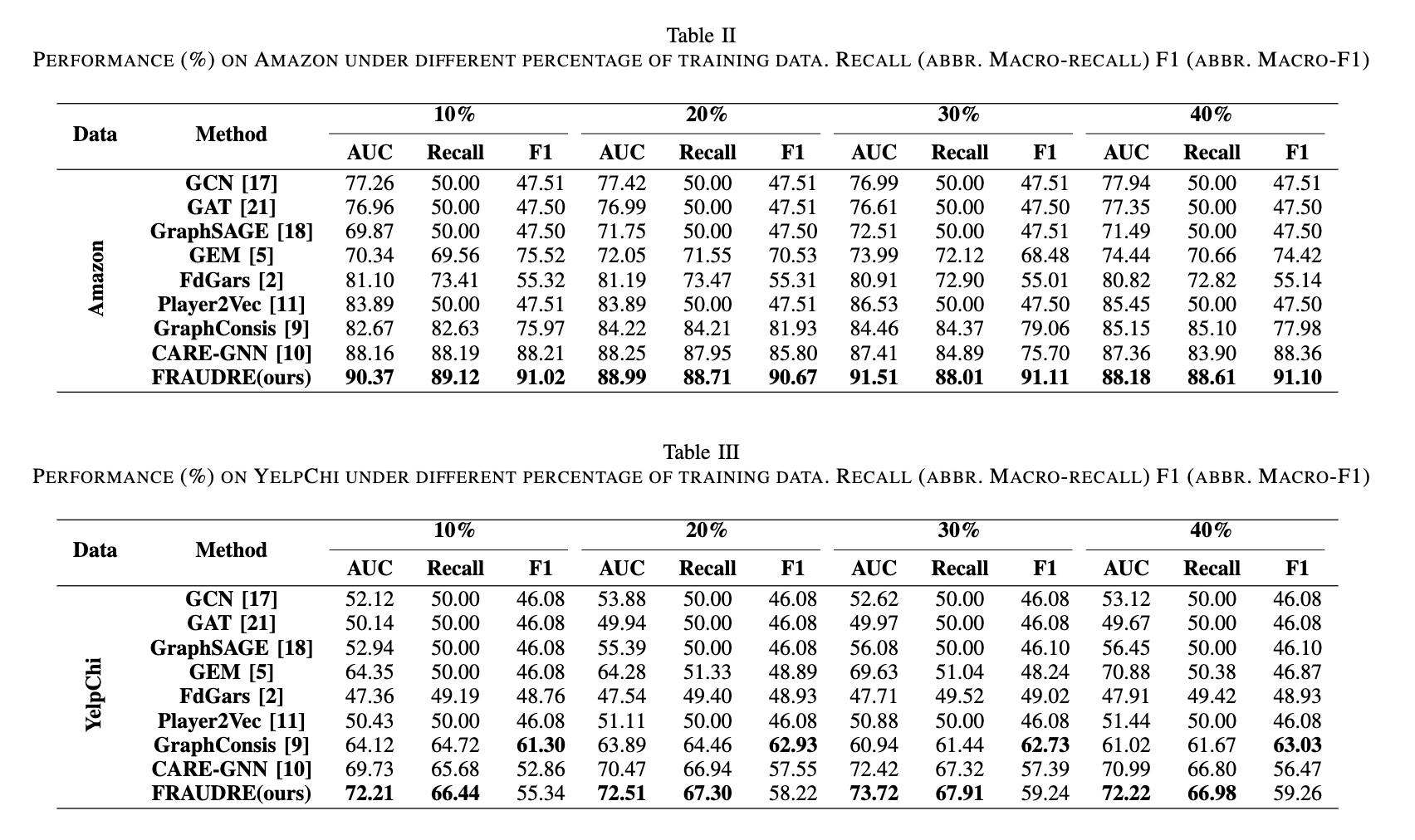
1)多关系与单一关系。回想一下,GCN、GAT、GraphSAGE 和 FdGars 在具有单一关系的图上运行(表 I 中的 ALL),而 GEM、Player2Vec、GraphConsis、CARE-GNN 和 FRAUDRE 旨在检测多关系图中的欺诈者。从表2的Amazon结果可以看出,Player2Vec和GEM的性能并不比针对单一关系图设计的算法(如fdgar)更好。原因是直接将 GNN 应用于多关系环境中的欺诈检测任务是不可行的。为此,GraphConsis 和 CARE-GNN 都取得了可喜的成果,因为它们在 GNN 聚合操作之前根据节点属性过滤了不同的邻居。 FRAUDRE 及其四个模块在单关系图和多关系图上均优于所有其他基线。
2) 检测伪装欺诈者。 GraphConsis、CARE-GNN 和 FRAUDRE 都检测到了欺诈者的伪装行为,并且都优于无法做出这种区分的算法。同样考虑伪装行为的FdGars在Amazon上表现不错,而在YelpChi上还有很大的提升空间。这是因为 FdGars 只考虑伪装的欺诈者,他们与标记的欺诈者具有相似的特征,而事实上,有许多伪装的欺诈者与标记的欺诈者具有不同的特征。 GraphConsis 和 CARE-GNN 采用更灵活的方式来检测伪装欺诈者,因此它们的性能优于 FdGars。 FRAUDRE 在 AUC 和召回率方面比 GraphConsis 取得了更好的结果,并且在所有评估指标方面都优于 CARE-GNN。
3)召回能力。由于论文侧重于欺诈检测,并且 Amazon 和 Yelpchi 两个数据集都是不平衡的,因此宏观设置下的召回率是评估所有方法性能的重要指标。如表 II 和 III 所示,GCN、GAT、GraphSAGE 和 Play2Vec 的召回率仅为 50% 左右。也就是说,这些算法将所有欺诈者归类为正常用户。使用这些算法,没有采取任何措施来减轻对多数类样本的分类偏差。此外,将正常用户的信息与欺诈者直接聚合会加剧这种偏见。 GraphConsis 和 CARE-GNN 成功地召回了两个数据集上的欺诈者。原因是这两种算法对正常用户进行了欠采样,以均衡训练集中正常用户和欺诈者的数量。此外,它们在邻域聚合操作之前为每个节点过滤不同的邻居。我们的模型在两个数据集上取得了最佳性能。 w.r.t.recall。
D. 表征相似性分析(RQ2)
为了证明 FRAUDRE 可以为正常用户和欺诈者学习有区别的嵌入,我们评估了相邻节点之间的平均表示相似度。表 IV(a) 和 IV(b) 分别显示了亚马逊和 YelpChi 上每种关系下欺诈者与其一跳邻居以及正常用户与其一跳邻居之间的平均余弦相似度。属性表示节点的属性。 M1 表示图形不可知嵌入模块的中间嵌入输出,M2 表示欺诈感知卷积模块的中间嵌入输出,P2inM2 表示欺诈感知中邻域差异聚合操作的中间嵌入输出卷积模块。
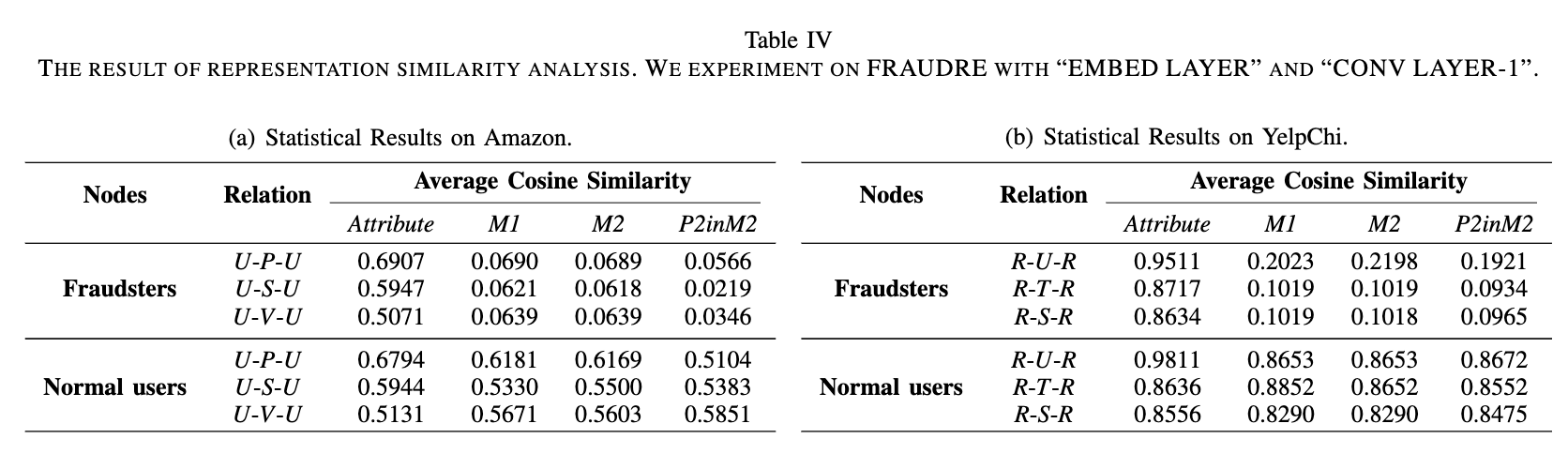
在欺诈者与普通用户建立很多连接的情况下,例如亚马逊上的 U-S-U,欺诈者与邻居之间原始属性的平均余弦相似度为 0.5947。然而,在训练 FRAUDRE 之后,欺诈者与其一跳邻居之间的 M1、M2 和 P2 在 M2 中的平均余弦相似度分别仅为 0.0621、0.0618、0.0219。然而,对于普通用户,在 U-S-U 下,他们与其一跳邻居之间原始属性的平均余弦相似度为 0.5944。此外,M1、M2 和 P2 在 M2 中正常用户与其邻居之间的平均余弦相似度保持在较高水平(约 0.55)。其他关系,亚马逊上的U-P-U和U-V-U以及YelpChi上的R-T-R和R-S-R,欺诈者也成功地伪装了自己,表现出类似的趋势。即使 YelpChi 中 R-U-R 关系下的欺诈者未能通过拓扑伪装自己,欺诈者与其邻居之间的 M1、M2 和 P2 的平均相似度仍然处于较低水平。一个可能的原因是欺诈者的行为不像正常用户那样稳定,并且欺诈者之间的差异可能很显着。
上述分析表明,与图无关的嵌入模块能够识别图中的特征不一致——它可以在模型开始时学习正常用户和欺诈者的判别嵌入.它还表明,欺诈感知卷积模块中聚合操作的差异可以放大正常用户和欺诈者之间的差异。
E. 消融分析 (RQ3)
为了证明 FRAUDRE 中各个组件的有效性,我们进行了一系列消融研究。测试的四个变体是:(i)FRAUDRE-M1:它不包括与图无关的嵌入模块,因此直接在节点属性上执行图卷积操作; (ii) FRAUDRE-M2:在欺诈感知图卷积模块中只保留了邻居聚合操作; (iii) FRAUDRE-M3:其中仅将最后一个图卷积层的嵌入输出作为最终节点嵌入; (iv) FRAUDRE-M4:它使用标准的交叉熵损失来对节点进行分类,而不是不平衡的面向分布的损失。
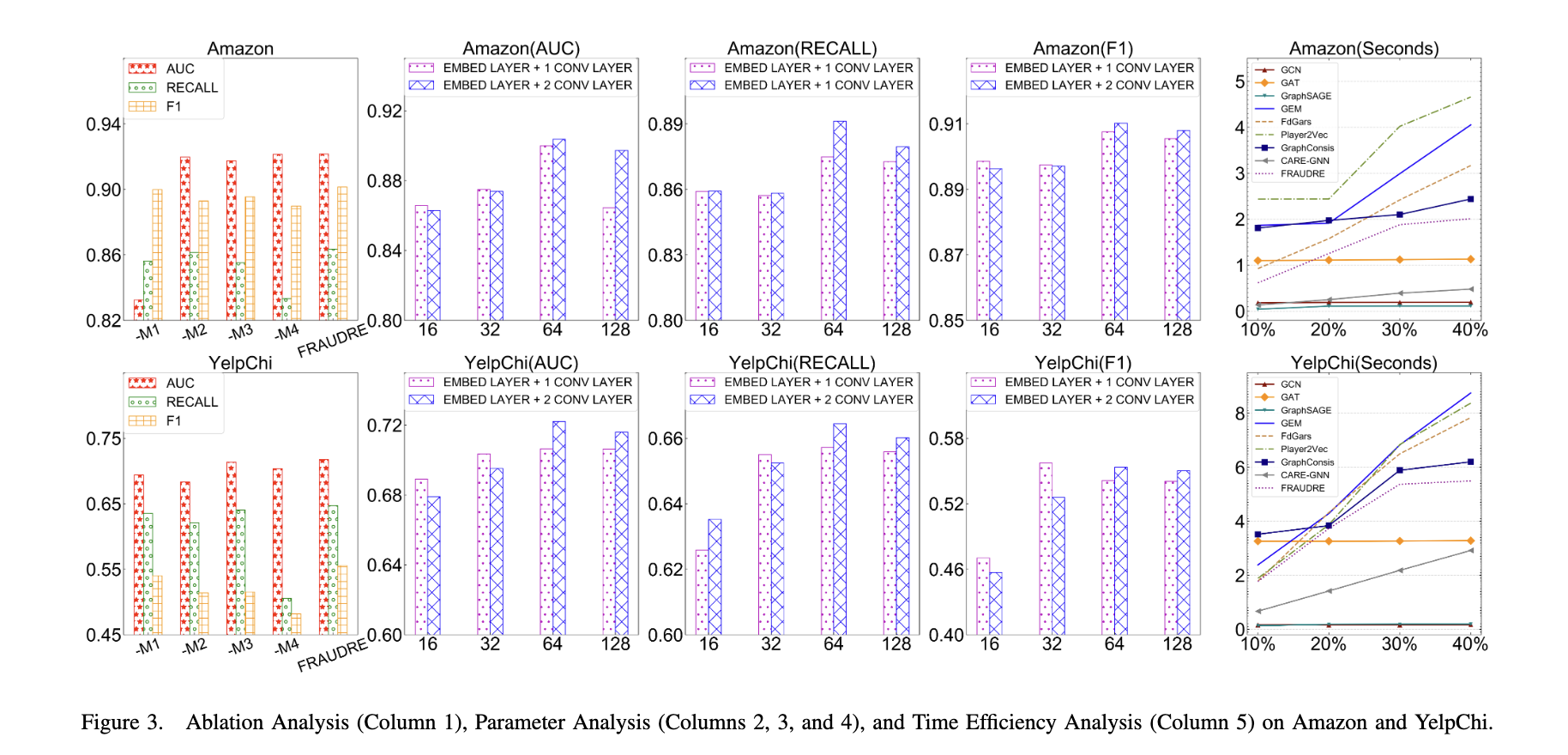
如图 3(第 1 列)所示,FRAUDRE 优于上述四种变体 w.r.t.所有评估指标。特别是,具有标准交叉熵损失的 FRAUDRE-M4 的性能大大低于其他变体 w.r.t.recall。这表明面向不平衡分类模块中的面向不平衡分布的损失函数有效地提高了分类器对少数类样本(即欺诈者)的泛化能力。
F. 参数敏感性 (RQ4)
我们还研究了 FRAUDRE 对与图卷积层数和图不可知嵌入模块中不同嵌入大小有关的参数的敏感性。Amazon和YelpChi的AUC、Macro-Recall和Macro-F1结果分别显示在图3的顶部和底部(第2、3和4列)。结果表明,我们的方法在大多数超参数组合下都能保持可接受的结果,并且具有相对稳定性。
G. 时间效率 (RQ5)
为了证明所有比较算法的运行时性能,我们记录了每个时期所有算法的平均训练时间,训练数据的比例从 10% 到 40% 不等。对于所有算法,我们将图卷积层数设置为 1,将嵌入大小设置为 64,在 Amazon 上将批量大小设置为 256,而 YelpChi 为 1024。如图 3(第 5 列)所示,FRAUDRE 与针对单关系图设计的欺诈检测算法(如 FdGars)相比,在运行速度上具有明显优势。 FRAUDRE 的运行速度也比专为多关系图设计的 GraphConsis 快。

















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









