







论文题目: Large Language Model based Multi-Agents: A Survey of Progress and Challenges
论文链接:https://arxiv.org/pdf/2402.01680.pdf

目录
2.1 Single-Agent Systems Powered LLMs
2.2 Single-Agent VS. Multi-Agent Systems
3.1 Agents-Environment Interface (:代理与环境交互和感知环境的方式)
3.4 Agents Capabilities Acquisition
4.1 LLM-MA for Problem Solving
4.2 LLM-MA for World Simulation
4.2.7 Disease Propagation Simulation
5 Implementation Tools and Resources
摘要:
背景:
由于LLM令人印象深刻的规划和推理能力,它们被用作自主代理来自动完成许多任务。
基于LLM的多代理系统在复杂问题解决和世界模拟方面取得了进步。
该论文对基于LLM的多智能体系统的基本方面以及面临的挑战进行了深入的讨论:
What domains and environments do LLM-based multi-agents simulate? (基于llm的多代理模拟哪些域和环境?)
How are these agents profiled and how do they communicate? (这些代理人是如何被描述的,他们又是如何交流的?)
What mechanisms contribute to the growth of agents’ capacities? (什么机制促进了代理人能力的增长?)
该文章总结了常用的数据集或基准,以便访问。(第五章~)
1 Introduction
单智能体已得到迅速发展:
基于llm的智能体已经被研究并迅速发展,以理解和生成类似人类的指令,促进在广泛环境下的复杂交互和决策
基于单个基于llm的代理的强大的能力,后续提出了基于llm的多代理来利用集体智能和多个代理的专门配置文件和技能。
多代理系统通过以下方式提供高级功能:
1)将LLM分成不同的代理,每个代理具有不同的能力;
2)使这些不同的代理之间的交互能够有效地模拟复杂的现实环境。
多个自主代理协作参与规划、讨论和决策,反映了人类群体在解决问题任务中的合作性质。
LLM 的能力:
LLM的交流能力,利用他们为交流生成文本和响应文本输入的能力。
LLM在各个领域的广泛知识和他们专注于特定任务的潜在潜力。
基于llm的多代理来解决各种任务:
software development;
multi-robot systems;
society simulation;
policy simulation;
game simulation;
该方向研究论文正在迅速增加:(每个叶节点上的数字表示该类别中论文的数量)
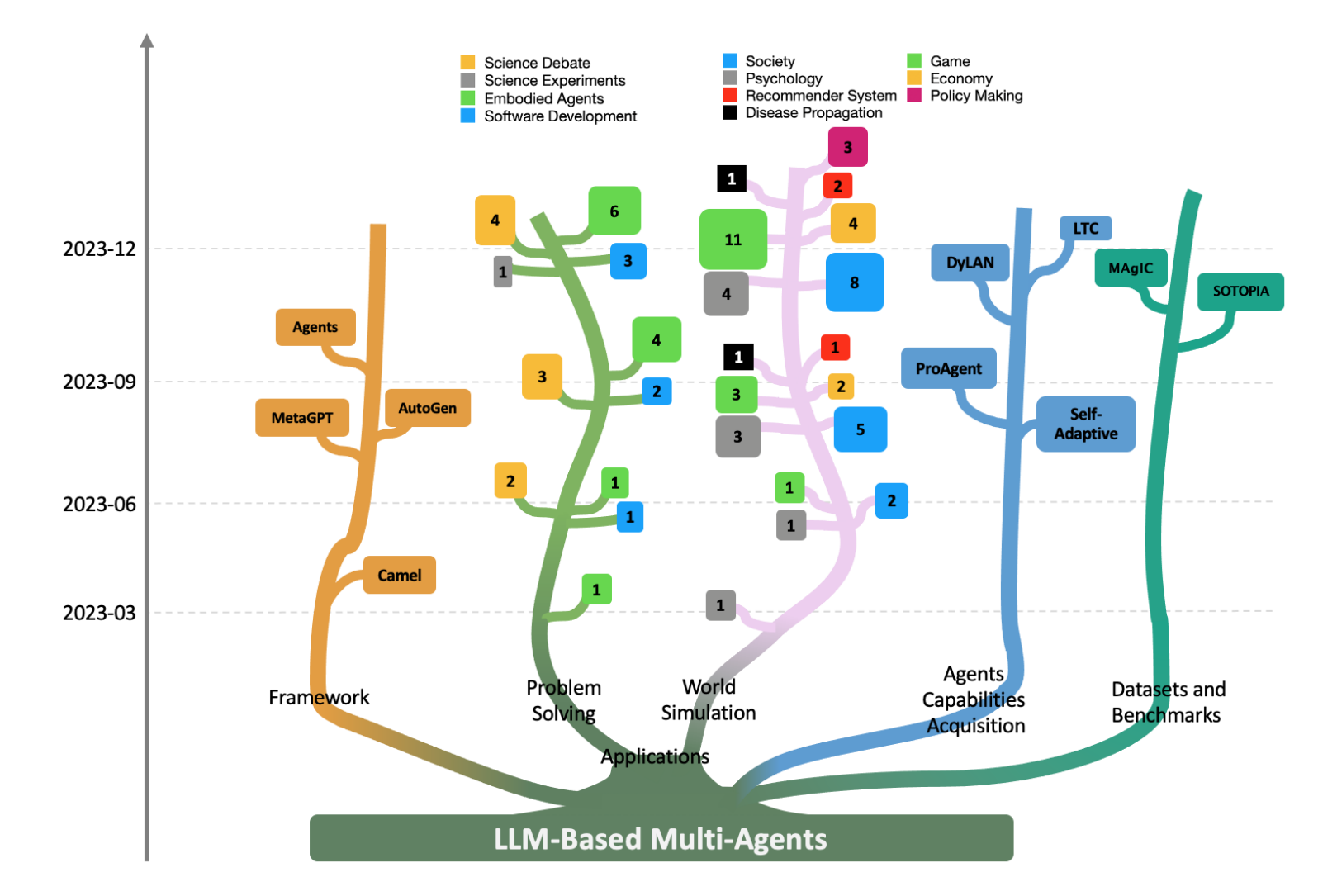
GitHub repository:(提供了一个可持续的资源来补充该调查报告,并保留了开源GitHub库)
https://github.com/taichengguo/LLM_MultiAgents_Survey_Papers
2 Background
2.1 Single-Agent Systems Powered LLMs
决策思维:
基于llm的智能体在提示(Prompt)的引导下,
将复杂任务分解为更小的子任务的能力,、思考每个部分(有时探索多条路径),
并从过去的经验中学习,以便在复杂任务上做出更好的决策。
工具使用:
基于llm的代理的工具使用能力允许它们利用外部工具和资源来完成任务,
增强它们的功能能力,并在多样化和动态的环境中更有效地运行。
记忆力:
基于llm的agent进行上下文学习的能力作为短期内存或外部向量数据库作为长期内存,以长时间保存和检索信息。
基于llm的代理能够保持上下文一致性,并增强从交互中学习的能力。
2.2 Single-Agent VS. Multi-Agent Systems
单代理:
这一体系的建设重点在于形成其内部机制以及与外部环境的相互作用。
多代理:
LLM-MA系统强调不同的主体概况、主体间的互动和集体决策过程。
更多的动态和复杂的任务可以通过多个自动代理的协作来解决,每个自动代理都配备了独特的策略和行为,并相互进行通信。
3 剖析LLM-MA系统:接口,分析、通信和能力
该章节解决的问题:
How are LLM-MA systems aligned with the collaborative task-solving environment? (LLM-MA系统如何与协作的任务解决环境对齐?)
LLM-MA系统的复杂性,其中多个自主代理参与类似于解决问题场景中的人类群体动态的协作活动。
这些LLM-MA系统如何与其运营环境和旨在实现的集体目标保持一致。
LLM-MA系统架构
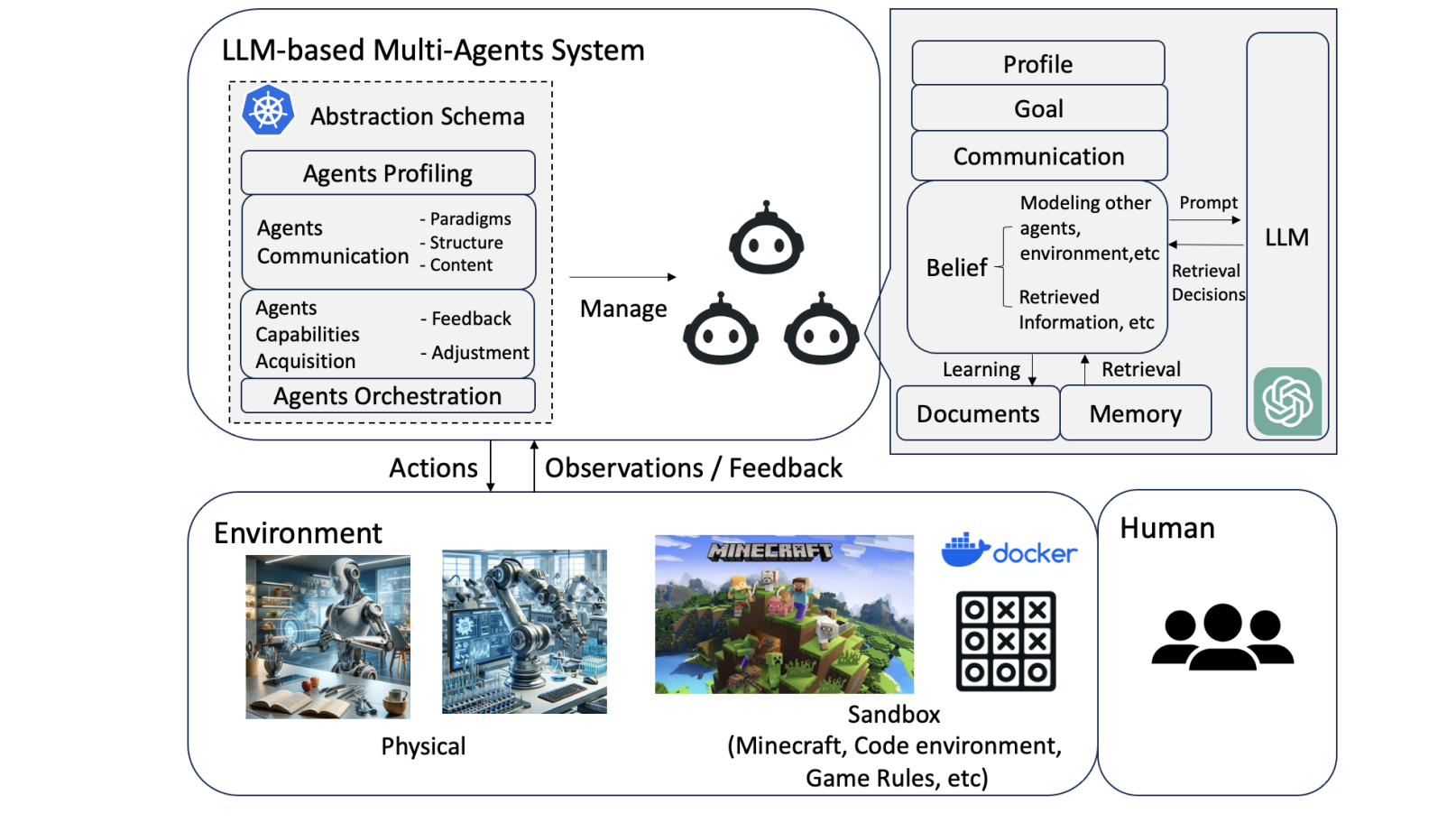
系统的一般架构:
the agents-environment interface;(代理-环境接口)
agent profiling;(代理个人资料)
agent communication;(代理通信)
agent capability acquisition.(代理能力获取)
3.1 Agents-Environment Interface (:代理与环境交互和感知环境的方式)
操作环境定义了LLM-MA系统部署和交互的特定上下文或设置。例如:
Werewolf Game simulation:(狼人杀游戏)
沙盒环境设定了游戏框架,包括从白天到晚上的过渡、讨论时间、投票机制和奖励规则。
werewolves and the Seer: 执行特定的动作,如杀死或检查角色
在这些行动之后,代理会收到来自环境的反馈,告知他们游戏的当前状态。
这些信息引导代理随着时间的推移调整他们的策略,对不断变化的游戏玩法和与其他代理的互动做出反应。
LLM-MA系统中的当前接口分类:
Sandbox
沙盒是指人类构建的模拟或虚拟环境,在这个环境中,代理可以更自由地交互,并试验各种行动和策略。
这种接口在软件开发中被广泛使用,代码解释器作为模拟环境。
Physcial
物理环境是一个真实世界的环境,其中代理与物理实体交互,并遵守现实世界的物理和约束;
在物理空间中,代理通常需要采取能够产生直接物理结果的行动。
例如,在扫地、制作三明治、包装杂货和整理橱柜等任务中,机器人代理需要迭代地执行动作,观察物理环境,并不断改进其动作。
None
指不存在特定的外部环境,agent不与任何环境发生交互的场景。
利用多个代理对一个问题进行辩论以达成共识。
这些应用程序主要关注代理之间的通信,而不依赖于外部环境。
3.2 Agents Profiling
在LLM-MA系统中,代理由他们的特征、行为和技能来定义,这些特征、行为和技能是为满足特定目标而量身定制的。
在不同的系统中,代理承担不同的角色,每个角色都有包含特征、能力、行为和约束的综合描述。
例如:
在辩论平台中,代理可以被指定为支持者、反对者或法官,每个代理都有独特的功能和策略来有效地履行其角色。
最近LLM-MA工作中的agent profile:
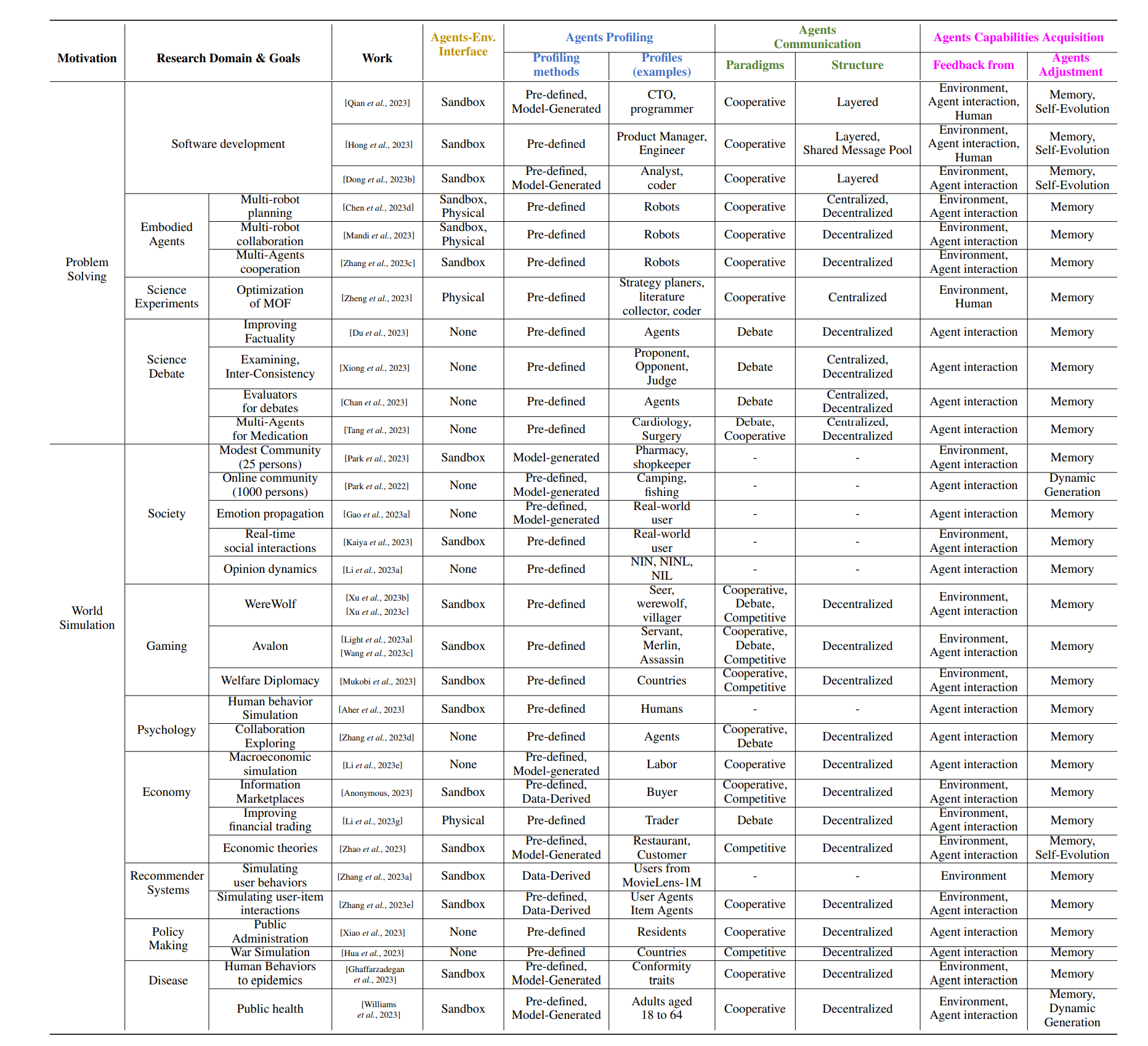
Agent Profiling Methods 分类:
Pre-defined
代理配置文件由系统设计人员显式定义
Model-Generated
按模型创建代理概要,例如,大型语言模型。
Data-Derived
基于预先存在的数据集构建代理配置文件。
3.3 Agents Communication
从三个角度看Agent通信:
Communication Paradigms:agent之间交互的方式和方法:
Cooperative
协作代理为了一个或多个共同的目标而共同工作,通常通过交换信息来增强集体解决方案。
Debate
当主体参与辩论互动,提出并捍卫自己的观点或解决方案,并批评他人的观点或解决方案时,就会采用辩论范式。
Competitive
竞争性代理为实现自己的目标而努力,这可能与其他代理的目标相冲突。
通信结构:多智能体系统内通信网络的组织和体系结构:
Layered:
分层通信是分层结构的,每一层的代理具有不同的角色,主要在其层内或与相邻层进行交互。
Decentralized:
分散通信在点对点网络上运行,其中代理直接相互通信,这是世界模拟应用中常用的结构。
Centralized:
集中式通信涉及一个或一组协调系统通信的中心代理,其他代理主要通过这个中心节点进行交互。
Message Pool:
通信结构维护一个共享消息池,其中代理根据其配置文件发布消息并订阅相关消息,从而提高了通信效率
通信代理之间交换的内容:
在LLM-MA系统中交流内容通常采用文本的形式。
3.4 Agents Capabilities Acquisition
使代理能够动态学习和进化
智能体需要学习哪些类型的反馈来增强其能力(Feedback), 以及智能体调整自身以有效解决复杂问题的策略(adjust strategies).
Feedback:
反馈包括代理收到的关于其行为结果的关键信息,帮助代理了解其行为的潜在影响并适应复杂和动态的问题。
Feedback from Environment:
如软件开发(代理从代码解释器获得反馈),以及嵌入的多代理系统(机器人从现实世界或模拟环境获得反馈)
Feedback from Agents Interactions:
反馈来自其他代理的判断或代理的通信。
problem-solving场景中很常见,代理学会批判性地评估并通过沟通完善结论
Human Feedback:
直接来自人类,对于使多智能体系统与人类的价值观和偏好保持一致至关重要
None:
没有反馈给代理这种情况经常发生在专注于分析模拟结果的世界模拟工作中,而不是智能体的规划能力。
比如传播模拟,重点是结果分析,因此,反馈不是系统的组成部分。
Agents Adjustment to Complex Problems:(智能体的自我调节)
Memory:
大多数LLMMA系统利用一个记忆模块来调整代理的行为。
记忆之前的互动和反馈。
执行动作时可以检索相关的、有价值的记忆,特别是那些包含过去类似目标的成功操作的记忆;
Self-Evolution:
不仅仅依靠历史记录来决定后续的行动;
代理可以动态地自我进化,通过修改自己,如改变他们的初始目标和规划策略,并根据反馈或通信日志训练自己。
Dynamic Generation:
在某些情况下,系统可以在运行过程中动态生成新的代理。
4 Applications
Problem Solving and World Simulation
以下是方法的应用距离:设计问题解决的研究方法和世界模仿的研究方法。
4.1 LLM-MA for Problem Solving
解决问题的主要动机是利用具有专门知识的代理的集体能力。
合作有效地解决复杂的问题,如软件开发,具体化代理,科学实验和科学辩论。
4.1.1 Software Development
软件开发是一项复杂的工作,需要各种角色(如产品经理、程序员和测试人员)的协作,LLM-MA系统通常被设置为模拟这些不同的角色,并协作解决复杂的挑战
代理之间的通信结构通常是分层的;
案例:
[Li et al., 2023b]首先提出了一个简单的角色扮演代理框架,利用两个角色的相互作用,实现基于一句话用户指令的自主编程。它提供了洞察交际主体的“认知”过程。
[Dong et al. 2023b]使llm作为软件开发子任务的独特“专家”,自主协作生成代码。
[Qian et al,2023]提出了一个软件开发的端到端框架,利用多个代理进行软件开发,而不纳入先进的人类团队合作经验。
[Hong等人,2023]首先结合了人工工作流洞察力,以实现更可控和更有效的性能。它将标准操作程序编码为提示,以增强结构化协调。
[Huang等人,2023a]通过解决平衡代码段生成与有效测试用例生成、执行和优化的问题,更深入地研究了基于多智能体的编程。
4.1.2 Embodied Agents
大多数嵌入代理应用程序本质上利用多个机器人一起工作来执行复杂的现实世界规划和操作任务,例如具有异构机器人功能的仓库管理。
LLMMA可以用于对具有不同能力的机器人进行建模,并相互协作以解决现实世界的物理任务。
案例:
[Dasgupta等人,2023]首先探索了将LLM作为嵌入式代理的行动计划器的潜力。
[Mandi等人,2023]介绍了RoCo,这是一种多机器人协作的新方法,它使用llm进行高层通信和低级路径规划。每个机械臂都配备一个LLM,配合运动学逆解和碰撞检测。实验结果证明了RoCo在协作任务中的适应性和有效性。
[Zhang等人,2023c]提出了CoELA,一个合作的具体语言代理,在LLM-MA环境中管理讨论和任务规划。这种具有挑战性的环境具有分散控制,复杂的局部观测,昂贵的通信和多目标长视野任务的特点。
[Chen等人,2023]研究了涉及大量机器人的场景中的通信挑战,因为由于长上下文,为每个机器人分配LLM将是昂贵且不切实际的。该研究比较了四种通信框架,集中式、分散式和两种混合模型,以评估它们在协调复杂的多智能体任务中的有效性。
[Yu等,2023]提出了用于多机器人协同视觉目标导航的CoNavGPT算法,将LLM作为全局规划器集成在一起,为每个机器人分配前沿目标。
[Chen et al., 2023b]提出了一种基于llm的共识寻求框架,该框架可作为多机器人聚合任务的协作规划器。
4.1.3 Science Experiments
就像多个agent作为不同的专家合作解决软件开发和具身agent问题一样,多个agent也可以组成一个科学团队进行科学实验。
与software development 和 embodied agents不同之处:
由于科学实验的高昂费用和LLM代理的幻觉,人类监督具有关键作用。
人类专家是这些智能体的中心,负责处理智能体的信息并给予反馈。
案例:
[Zheng et al., 2023]利用多个基于llm的代理,每个代理专注于科学实验的特定任务,包括策略规划、文献检索、编码、机器人操作和实验室软件设计。
所有这些试剂与人类相互作用,协同工作,以优化复杂材料的合成过程。
4.1.4 Science Debate
LLM-MA可以设置为科学辩论场景,其中智能体相互辩论以增强大规模多任务语言理解(MMLU)、数学问题、StrategyQA等任务中的集体推理能力;
其主要思想是,每个代理首先对一个问题提出自己的分析,然后进行联合辩论过程。经过多轮辩论,代理们最终达成了一个单一的、一致的答案。
案例:
[Du等人,2023]在一组六个不同的推理和事实准确性任务上利用多智能体辩论过程,并证明LLM-MA辩论可以提高事实性。
[Xiong等人,2023]专注于常识性推理任务,并制定了一个三阶段的辩论,以与现实世界的场景保持一致,包括公平辩论、错配辩论和圆桌辩论。
[Tang et al., 2023]还利用多个基于llm的代理作为不同领域的专家,对医疗报告进行协作讨论,以达成医疗诊断共识。
4.2 LLM-MA for World Simulation
角色扮演能力使其能够进行世界模仿:
4.2.1 Societal Simulation
在社会模拟中,LLM-MA模型用于模拟社会行为,旨在探索潜在的社会动态和传播,检验社会科学理论,并以现实的社会现象填充(populate)虚拟空间和社区。
案例:
[Park等人2023]在一个让人想起模拟人生的交互式沙盒环境中引入生成代理,允许最终用户通过自然语言与25个代理组成的适度社区进行互动。
[Park et al., 2022]发展了Social Simulacra,它构建了一个由1000个角色组成的模拟社区。这个系统体现了设计师对社区的愿景——它的目标、规则和成员角色,产生诸如发帖、回复、甚至反社会行为的行为。
[Gao等人,2023a]通过构建分别包含8,563和17,945个代理的庞大网络,进一步扩展了这一概念,旨在模拟以性别歧视和核能为主题的社会网络。这种演变表明,在最近的研究中,模拟环境的复杂性和规模越来越大。
最近的研究如[Chen et al., 2023b, Kaiya等,2023;Li et al., 2023a;Li et al., 2023f;Ziems等人,2023]强调了多智能体系统中不断发展的复杂性,LLM对社会网络的影响,以及它们与社会科学研究的整合。
4.2.2 Gaming
这项技术能够开发出可控的、可扩展的、动态的环境,这些环境非常接近于模拟人类的互动,使其成为测试一系列博弈论假设的理想选择。
LLM-MA模拟的大多数游戏在很大程度上依赖于自然语言交流,在不同的游戏设置中提供一个沙盒环境来探索或测试博弈论假设,包括推理、合作、说服、欺骗、领导等
案例:
[Akata et al., 2023]利用行为博弈论来研究LLM在互动社会环境中的行为,特别是他们在反复的囚徒游戏中的表现性别的困境和斗争。
[Xu et al.2023b]提出了一个使用ChatArena库的框架[Wu等人,2023b],用于让LLM参与像狼人杀这样的交流游戏,使用对过去交流的检索和反思来改进,以及思维链机制[Wei等人,2022]。
[Light等人,2023b]探索了LLM代理在玩抗阿瓦隆中的潜力,引入了AVALONBENCH,这是一个全面的游戏环境和基准,可以进一步开发先进的LLM和多代理框架。
[Wang等人,2023c]还关注了LLM代理在处理阿瓦隆博弈中的错误信息方面的能力,提出了递归沉思(ReCon)框架,以提高法学硕士辨别和抵制欺骗性信息的能力。
[Xu et al.]2023c]引入了一个将llm与强化学习(RL)相结合的框架,为狼人游戏开发战略语言代理。
[Mukobi等人2023]设计了“福利外交”,这是零和棋盘游戏《外交》的通用和变体,玩家必须在军事征服和国内福利之间取得平衡。它还提供了一个开源基准,旨在帮助提高多智能体人工智能系统的协作能力。
Li et al., 2023c]在一个多智能体合作文本游戏中,测试了智能体的心智理论(ToM),推理他人隐藏的心理状态的能力,这是人类社会互动、合作和交流的基础。
[Fan et al., 2023]全面评估了LLM作为理性参与者的能力,并确定了基于LLM的智能体的弱点,即使在明确的游戏过程中,代理人在采取行动时可能仍然会忽略或修改精炼的信念。
4.2.3 Psychology
与社交模拟不同,心理学的一种方法是直接将心理学实验应用于这些代理人。该方法侧重于通过统计方法观察和分析它们的各种行为。
使用方法:
每个代理独立操作,不与其他代理交互,本质上代表不同的个体。
另一种与社会模拟更接近,其中多个代理相互作用和通信。在这种情况下,心理学理论被应用于理解和分析紧急行为模式。
案例:
[Ma et al., 2023]探讨了使用基于LLM的对话代理为心理健康提供支持的心理影响和结果。它强调了从心理学角度仔细评估在心理健康应用中使用基于LLM的代理的必要性。
[Kovac et al., 2023]介绍了一种名为SocialAI school的工具,用于创建模拟社交互动的互动环境。它借鉴发展心理学来理解主体如何获得、展示和发展社会技能,如共同注意、沟通和文化学习。
[Zhang等人,2023]探讨了具有不同特征和思维模式的LLM代理如何模仿类似人类的社会行为,如从众和多数决定原则。将心理学整合到对智能体协作的理解中,为检查和增强基于llm的多智能体系统背后的机制提供了一个新的视角。
4.2.4 Economy
在这些模拟中,为代理人提供了禀赋和信息,并设置了预定义的偏好,允许在经济和金融环境中探索他们的行为。
研究案例:
[Li等人,2023e]使用LLM进行宏观经济模拟,其特点是提示工程驱动的代理可以模拟类似人类的决策,从而与基于规则或其他方式相比,增强了经济模拟的真实感。
[Anonymous, 2023]探讨了信息市场中买方的检查悖论,揭示了代理在购买前临时获取信息可以提高决策和回答质量。
[Li等,2023g]提出了金融交易的LLM-MA框架,强调了分层记忆系统、辩论机制和个性化交易特征,从而加强了决策的鲁棒性。
[Zhao等,2023]采用基于llm的方法代理人用餐馆和客户代理人模拟一个虚拟城镇,产生与社会学和经济学理论一致的见解。
4.2.5 Recommender Systems
LLM在推荐系统中的应用与心理学中的应用类似,因为这两个领域的研究都涉及到对外在和内在人类因素的考虑,如认知过程和人格。
使用方法:
将项目直接引入多个具有不同特征的基于llm的智能体,并对不同智能体的偏好进行统计;
另一种方法:将用户和商品都视为代理,将用户-商品通信视为交互,模拟偏好传播;
案例:
[Zhang等,2023a]介绍了一种基于LLM-MA的仿真平台。使用MovieLens-1M数据集初始化1000个生成代理,以模拟推荐环境中的复杂用户交互。LLM-MA可以有效地模拟真实的用户偏好和行为,提供对过滤气泡效应等现象的见解,并帮助揭示推荐任务中的因果关系。其中,代理用来模拟用户,它们之间不进行通信。
[Zhang等人,2023e]将用户和物品都视为代理,对它们进行集体优化,以反映和适应现实世界的交互差异。这项工作强调模拟用户-项目交互,并在代理之间传播偏好,捕捉协同过滤的本质。
4.2.6 Policy Making
类似于游戏和经济场景中的模拟,政策制定需要对现实的、动态的复杂问题有较强的决策能力。
这些模拟为政策的制定及其潜在影响提供了有价值的见解,帮助决策者理解和预测其决策的后果。
案例:
[Xiao等,2023]以模拟乡镇水污染危机为中心。它模拟了一个位于岛屿上的城镇,包括不同代理人、乡镇负责人和顾问的人口结构。深入分析虚拟政府实体如何应对这样的公共管理挑战,以及在这场危机中信息如何在社会网络中传递。
[Hua等人,2023]引入WarAgent来模拟关键的历史冲突,并为冲突解决和理解提供见解,在预防未来的国际冲突方面具有潜在的应用。
4.2.7 Disease Propagation Simulation
利用LLM-MA的社会模拟能力也可以用来模拟疾病传播。
案例:
[Williams et al., 2023]深入研究了LLM-MA模拟疾病传播。该研究通过各种模拟展示了这些基于LLM的代理如何准确地模拟人类对疾病爆发的反应,包括在病例数量增加时的自我隔离和隔离等行为。这些病原体的集体行为反映了大流行中常见的多重波的复杂模式,最终稳定为流行病状态。令人印象深刻的是,他们的行动有助于流行病曲线的衰减。
[Ghaffarzadegan et al., 2023]也讨论了流行病传播模拟,并将模拟分解为两部分:代表病毒信息或传播的Mechanistic Model和代表agent面对病毒时的决策过程的Decision-Making Model。
5 Implementation Tools and Resources
5.1 Multi-Agents Framework
三个开源的多代理框架: 它们都是利用语言模型来解决复杂任务的框架,重点是多代理协作,但它们的方法和应用程序有所不同。
MetaGPT[Metagpt: Meta programming for multi-agent collaborative framework; code:github]
MetaGPT旨在将人类工作流程嵌入到语言模型代理的操作中,从而减少在复杂任务中经常出现的幻觉问题。它通过将标准操作程序编码到系统中并使用装配线方法将特定角色分配给不同的代理来实现这一点。
CAMEL[Camel: Communicative agents for” mind” exploration of large scale language model society.; code: github]
CAMEL,即沟通代理框架,旨在促进代理之间的自主合作。它使用一种称为初始提示的新技术来引导会话代理完成与人类目标一致的任务.该框架还可以作为生成和研究会话数据的工具,帮助研究人员了解交流代理的行为和交互方式。
Autogen[AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation; code: github]
AutoGen是一个通用框架,允许使用语言模型创建应用程序。它的独特之处在于其高水平的自定义,使开发人员能够使用自然语言和代码对代理进行编程,以定义这些代理如何交互。
这种多功能性使其能够在不同的领域使用,从编码和数学等技术领域到娱乐等以消费者为中心的领域。
5.2 Datasets and Benchmarks
不同的研究应用程序使用不同的数据集和基准。
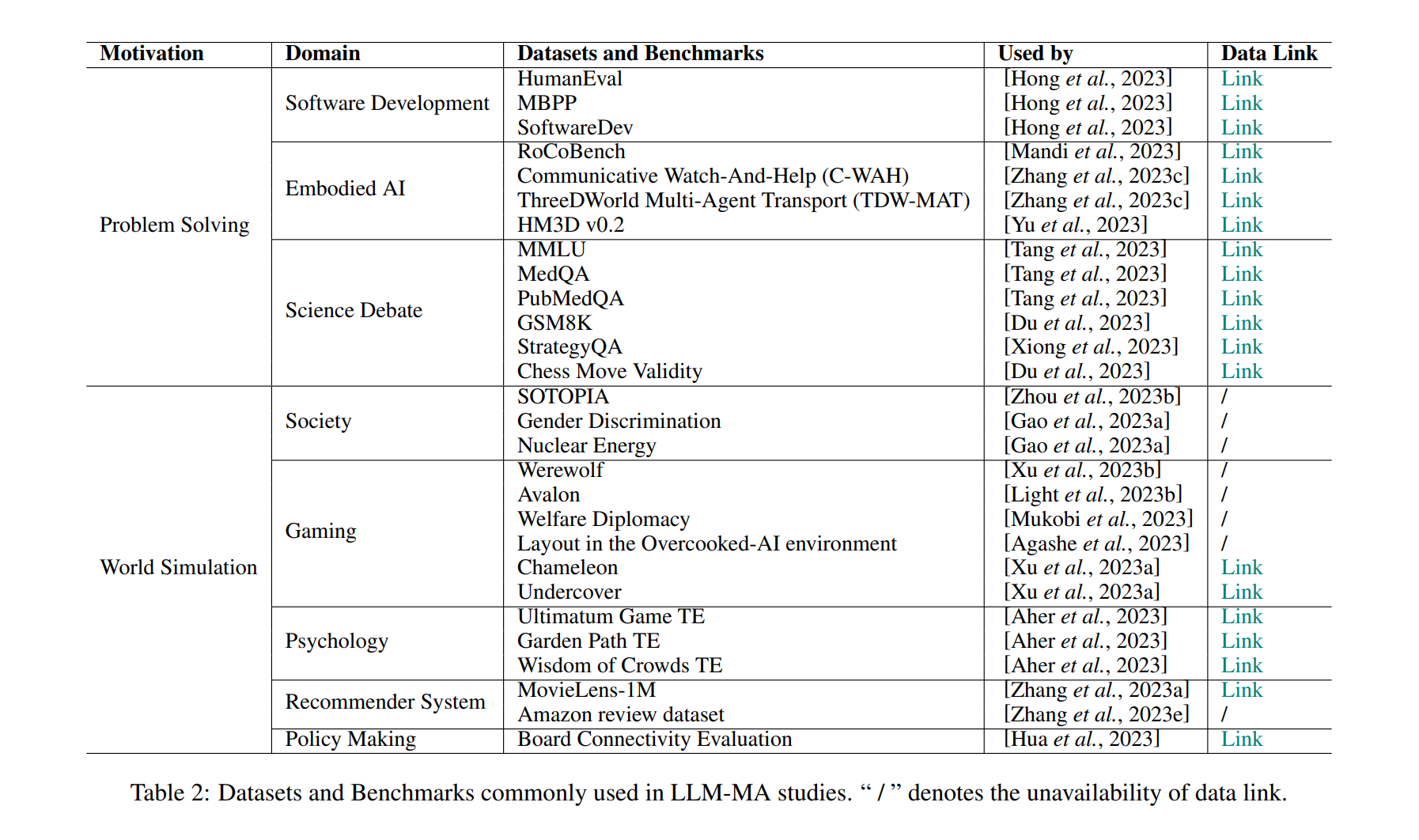
问题解决场景
在问题解决场景中,大多数数据集和基准被用来评估多智能体合作或辩论的规划和推理能力。
世界模拟场景
在世界模拟场景、数据集和基准用于评估模拟世界与现实世界之间的一致性或分析不同代理的行为。然而,在某些研究应用中,如科学团队的实验操作和经济建模,仍然需要全面的基准

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









