








此篇博客是李宏毅老师的深度学习课程的笔记
网课地址:https://www.bilibili.com/video/av48285039?p=75
Auto-encoder
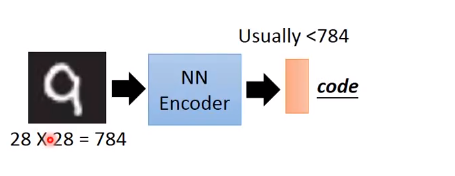
input:可能就是一张图片,图片可以变成一个向量。
encoder:可能就是一个neural network
output: 是一个比输入向量维度低的向量,也即为code,更为精简的,压缩的(compact)表示图片的方式。

- decoder的缘由:由于只用code无法learning,所以用一个decoder将code学习输出一个图片,优化目标是最小化输出图片和输出图片的差距,即将encoder和decoder一起学习,得到一个无监督学习的模型。
- 起源于PCA:

- Deep Auto-encoder:但是encoder和decoder的权重可以不一样。

应用I :文字检索
- vector space model
每一篇文档都是向量空间中的一个点

- 在低维的空间上,(就是变为code)可以更好的被检索

应用II :图像检索
- 把每张图片变成一个code,在code上面去做搜寻。
- 这件事情是无监督学习,不缺少data,可以聚类很多类???

应用III :预训练(per-train and fine-tune)
- 预训练per-train:找一种比较好的初始化参数。
- 微调fine-tune:由于预训练定了一些参数,所以再进行back-propagation时只需要微调。
- 随着training技术的进步,这招逐渐不常用;但是很适用在:有大量的unlabel data,只有少量的label data,即是用unlabel data去初始化参数,用label data微调参数。此处注意若利用encoder和decoder训练,则无监督训练,只需要最小化输入和输出即可。

De-noising auto-encoder

CNN 的 Auto-encoder

- Unpooling : 一种是记录pooling时抽取的pixel的位置。

- 解卷积 deconvolution = conv
- 不同是在于:权值相反,且需要补零的conv

More about auto-decoder
- 另外一种不用最小化输入图片和decoder的输出图片差距的方法:
如何知道encoder输出的code是好是坏? 则训练一个discriminator去判断code是否能够很好的代表输入图片.
-得到一种新的训练encoder的方法.
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









