







- 类似DFF、LeRF等,将Grounded DINO的2D Mask知识lifting到3D。
- 通过渲染得到的Mask,分别对前景进行编辑,对背景进行约束。
- 提出局部编辑(仅对前景编辑)和全局编辑交替进行的训练策略,使得在约束背景的情况下,使前背景和谐。
- 提出在图片驱动的编辑中,局部编辑不使用V*,来减缓多脸问题。
目录
Foreground-aware NeRF Training
Adaptive Source Driven NeRF Editing
Local-Global Iterative Editing
Method
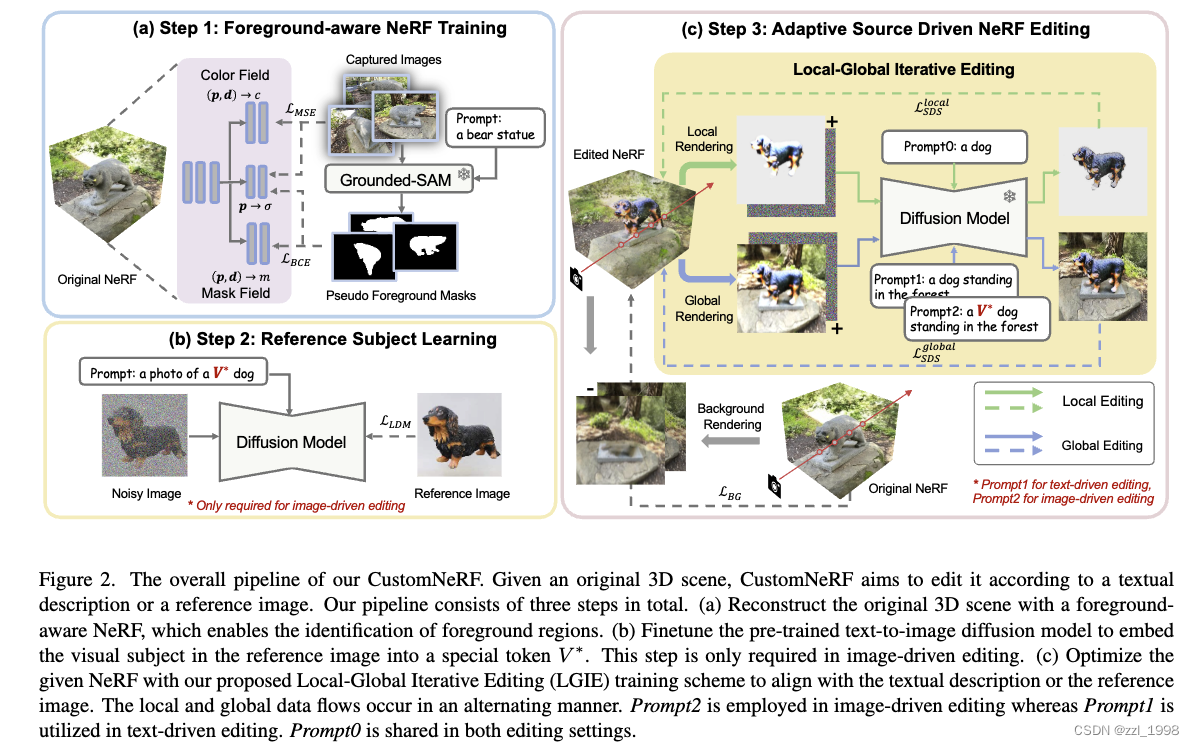
CustomNeRF包含三个步骤:
- 训练能区分前景的NeRF(foreground-aware NeRF):通过将额外mask引入训练过程中,使模型能预测编辑概率(editing probability),也即前景概率。
- subject-aware Text-to-Image (T2I):通过类似DreamBooth的算法,将参考图像编码为V*;
- 使用Local-Global Iterative Editing(LGIE)方法进行场景编辑,保存背景。
同时,本文在image-driven editing中引入了class-guided regularization,缓解Janus problem。
Foreground-aware NeRF Training
- 对空间中任意点,以预测颜色类似的方式,预测编辑概率,也即前景概率。通过Grounded SAM获取语义分割掩码,用BCE loss监督渲染掩码和GT掩码。
Reference Subject Learning
- 用类似Dreambooth的方法将参考图片编码为V*。
Adaptive Source Driven NeRF Editing
Local-Global Iterative Editing
- 包括局部编辑阶段(仅编辑前景)和全局编辑阶段。
- 在局部编辑阶段,用类似图像渲染的方式,渲染前景区域:

- 其中,前景概率与不透明度相乘用来过滤背景:
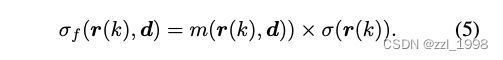
- 随后,用前景目标作为prompt,得到局部SDS损失
。
- 在全局编辑阶段,则输入完整图像,并用使用完整prompt,计算全局SDS损失
。全局编辑损失可以让前后景生成和谐。
- 为了逼遍背景区域的改变,本文将对背景区域的梯度截断。
Class-guided regularization
- 在图片引导的编辑中,使用class-guided regularization方法来缓解多脸问题。
- 具体来说,本文在局部编辑阶段,移除V*,在全局阶段则保持V*使用。
Loss functions
- 增加了背景约束项,通过渲染原NeRF的背景,约束编辑后NeRF的背景。
- 最终的损失为:
![]()
实验
- Datasets:在BlendedMVS、LLFF、IBRNet和Bear Statue等8个真实场景上进行了测试。
- Baselines:text-driven editing(Instruct-NeRF2NeRF、RePaint-NeRF);image-driven editing(Ours + Splice Loss、RePaint-NeRF)



















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









