










DCGAN-MNIST——使用TensorFlow 2 / Keras实现深度卷积DCGAN来生成时尚MNIST的灰度图像
这篇博客将介绍如何使用TensorFlow 2 / Keras中实现深度卷积GAN(DCGAN)来生成类似时尚MNIST的灰度图像。将介绍DCGAN架构指南,如何训练稳定的DCGAN。在TensorFlow 2/Keras中使用灰度时尚MNIST图像完成DCGAN代码实现。使用了Keras Model子类化来定制train_step,然后调用Keras Model.fit()进行训练。
下一篇博客将实现用时尚彩色图像训练的DCGAN来展示GAN训练的挑战。
- DCGAN 架构指南
- 定制 train_step() 与Keras model.fit()
- TensorFlow 2 / Keras实现DCGAN
每个GAN至少有一个发生器和一个鉴别器。当生成器和鉴别器相互竞争时,生成器在从鉴别器获得反馈时,能够更好地生成接近训练数据分布的图像。
1. 效果图
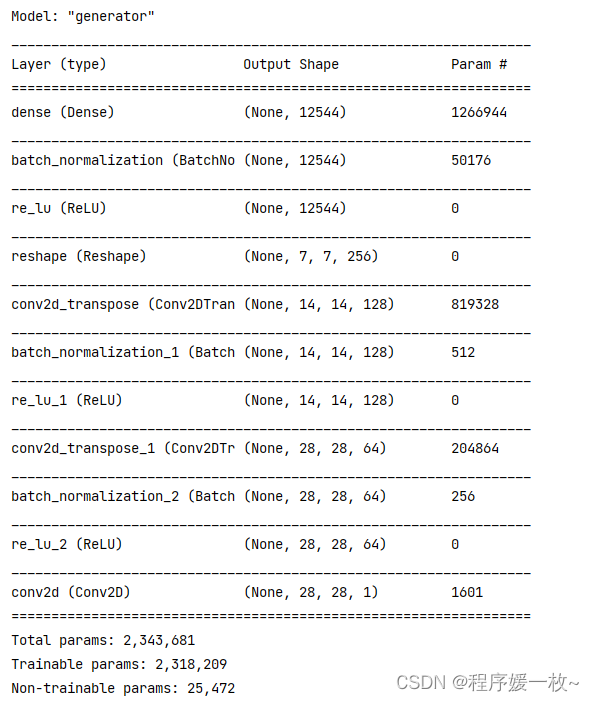
生成器结构:
鉴别器结构:

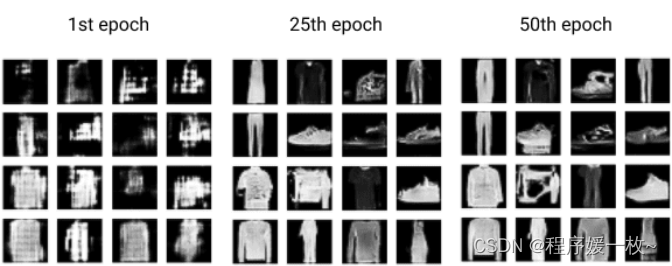
训练1 VS 25 VS 50效果图如下:
(28, 28, 1)
2023-05-25 20:44:36.432534: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/50
1/1 [] - 3s 3s/step - d_loss: 0.7167 - g_loss: 1.2281
Epoch 2/50
1/1 [] - 0s 160ms/step - d_loss: 0.7766 - g_loss: 0.9896
Epoch 3/50
1/1 [] - 0s 154ms/step - d_loss: 0.8732 - g_loss: 0.6658
Epoch 4/50
1/1 [] - 0s 166ms/step - d_loss: 0.6789 - g_loss: 0.7311
Epoch 5/50
1/1 [] - 0s 154ms/step - d_loss: 0.4631 - g_loss: 1.0747
Epoch 6/50
1/1 [] - 0s 165ms/step - d_loss: 0.4101 - g_loss: 1.0436
Epoch 7/50
1/1 [] - 0s 223ms/step - d_loss: 0.3703 - g_loss: 1.1298
Epoch 8/50
1/1 [] - 0s 197ms/step - d_loss: 0.5815 - g_loss: 1.1503
Epoch 9/50
1/1 [] - 0s 166ms/step - d_loss: 0.4747 - g_loss: 1.7595
Epoch 10/50
1/1 [] - 0s 156ms/step - d_loss: 0.3227 - g_loss: 2.4748
Epoch 11/50
1/1 [] - 0s 173ms/step - d_loss: 0.2040 - g_loss: 3.1504
Epoch 12/50
1/1 [] - 0s 166ms/step - d_loss: 0.2089 - g_loss: 2.6114
Epoch 13/50
1/1 [] - 0s 155ms/step - d_loss: 0.3123 - g_loss: 1.8193
Epoch 14/50
1/1 [] - 0s 150ms/step - d_loss: 0.2877 - g_loss: 2.4994
Epoch 15/50
1/1 [] - 0s 150ms/step - d_loss: 0.1433 - g_loss: 2.4561
Epoch 16/50
1/1 [] - 0s 149ms/step - d_loss: 0.1219 - g_loss: 1.9404
Epoch 17/50
1/1 [] - 0s 156ms/step - d_loss: 0.1367 - g_loss: 1.8200
Epoch 18/50
1/1 [] - 0s 152ms/step - d_loss: 0.1019 - g_loss: 2.0167
Epoch 19/50
1/1 [] - 0s 188ms/step - d_loss: 0.0696 - g_loss: 1.5635
Epoch 20/50
1/1 [] - 0s 173ms/step - d_loss: 0.0684 - g_loss: 1.4290
Epoch 21/50
1/1 [] - 0s 196ms/step - d_loss: 0.0742 - g_loss: 1.5191
Epoch 22/50
1/1 [] - 0s 192ms/step - d_loss: 0.0975 - g_loss: 1.5210
Epoch 23/50
1/1 [] - 0s 190ms/step - d_loss: 0.0831 - g_loss: 0.6667
Epoch 24/50
1/1 [] - 0s 173ms/step - d_loss: 0.1027 - g_loss: 0.6803
Epoch 25/50
1/1 [] - 0s 173ms/step - d_loss: 0.0767 - g_loss: 1.1220
Epoch 26/50
1/1 [] - 0s 181ms/step - d_loss: 0.0440 - g_loss: 1.4847
Epoch 27/50
1/1 [] - 0s 174ms/step - d_loss: 0.0304 - g_loss: 1.4330
Epoch 28/50
1/1 [] - 0s 182ms/step - d_loss: 0.0268 - g_loss: 1.2883
Epoch 29/50
1/1 [] - 0s 188ms/step - d_loss: 0.0293 - g_loss: 1.3937
Epoch 30/50
1/1 [] - 0s 173ms/step - d_loss: 0.0136 - g_loss: 1.0047
Epoch 31/50
1/1 [] - 0s 209ms/step - d_loss: 0.0154 - g_loss: 0.8617
Epoch 32/50
1/1 [] - 0s 199ms/step - d_loss: 0.0114 - g_loss: 0.5661
Epoch 33/50
1/1 [] - 0s 219ms/step - d_loss: 0.0093 - g_loss: 0.6212
Epoch 34/50
1/1 [] - 0s 193ms/step - d_loss: 0.0084 - g_loss: 0.5213
Epoch 35/50
1/1 [] - 0s 210ms/step - d_loss: 0.0073 - g_loss: 0.4086
Epoch 36/50
1/1 [] - 0s 195ms/step - d_loss: 0.0059 - g_loss: 0.3696
Epoch 37/50
1/1 [] - 0s 193ms/step - d_loss: 0.0088 - g_loss: 0.3803
Epoch 38/50
1/1 [] - 0s 177ms/step - d_loss: 0.0084 - g_loss: 0.2576
Epoch 39/50
1/1 [] - 0s 185ms/step - d_loss: 0.0072 - g_loss: 0.3387
Epoch 40/50
1/1 [] - 0s 182ms/step - d_loss: 0.0056 - g_loss: 0.3223
Epoch 41/50
1/1 [] - 0s 228ms/step - d_loss: 0.0046 - g_loss: 0.2862
Epoch 42/50
1/1 [] - 0s 226ms/step - d_loss: 0.0059 - g_loss: 0.2288
Epoch 43/50
1/1 [] - 0s 197ms/step - d_loss: 0.0049 - g_loss: 0.2531
Epoch 44/50
1/1 [] - 0s 200ms/step - d_loss: 0.0056 - g_loss: 0.1869
Epoch 45/50
1/1 [] - 0s 193ms/step - d_loss: 0.0038 - g_loss: 0.2534
Epoch 46/50
1/1 [] - 0s 192ms/step - d_loss: 0.0050 - g_loss: 0.1715
Epoch 47/50
1/1 [] - 0s 198ms/step - d_loss: 0.0044 - g_loss: 0.1654
Epoch 48/50
1/1 [] - 0s 181ms/step - d_loss: 0.0056 - g_loss: 0.1122
Epoch 49/50
1/1 [] - 0s 211ms/step - d_loss: 0.0035 - g_loss: 0.1579
Epoch 50/50
1/1 [] - 0s 188ms/step - d_loss: 0.0043 - g_loss: 0.1457
2. 原理
2.1 结构指南
DCGAN论文介绍了一种GAN架构,其中鉴别器和生成器(discriminator and generator)由卷积神经网络(CNNs)定义。它提供了几个体系结构指南来提高训练稳定性:为了简洁起见,将生成器称为G,鉴别器称为D。

- GD都替换卷积为条纹卷积和分数阶跨步卷积
- 条纹卷积(Strided convolutions):步长为2的卷积层,用于D中的下采样。
- 分数阶跨步卷积(Fractional-strided convolutions):Conv2Transpose层的跨步为2,用于G中的上采样。
- GD都使用归一化
- 批量规一化
本文建议在G和D中使用批量归一化(batchnorm)来帮助稳定GAN训练。Batchnorm将输入层标准化为具有零均值和单位方差。它通常添加在隐藏层之后和激活层之前。随着我们在GAN系列中的进展,您将学习到更好的GAN规范化技术。
- 移除深度架构中的全量连接隐藏层
- 除使用Tanh的输出层,都生成使用ReLU激活器
- 激活器
DCGAN生成器和鉴别器中有四种常用的激活函数:sigmoid、tanh、ReLU和leakyReLU。 - sigmoid:将数字压缩为0(假)和1(真)。由于DCGAN鉴别器进行二元分类,在D的最后一层使用sigmoid。
- tanh(Hyperbolic Tangent 双曲正切):也是s形的,类似于s形;事实上,它是一个缩放的s形,但以0为中心,并将输入值压缩为[-1,1]。根据论文的建议在G的最后一层使用tanh。这就是为什么需要将训练图像预处理到[-1,1]的范围内。
- ReLU(Rectified Linear Activation 整流线性激活):当输入值为负值时,返回0;否则,它将返回输入值。建议对G中的所有层进行ReLU激活,除了使用tanh的输出层。
- LeakyReLU:与ReLU类似,只是当输入值为负值时,它使用常数alpha来给它一个非常小的斜率。正如论文所建议的那样,将斜率(alpha)设置为0.2。在D中对除最后一层之外的所有层使用LeakyReLU激活。
2.2 模型结构及训练过程
同时训练两个网络:一个生成器和一个鉴别器。为了创建DCGAN模型,首先需要使用Keras Sequential API定义生成器和鉴别器的模型体系结构。然后使用Keras模型子类化来创建DCGAN。
-
数据
第一步是为训练做好数据准备。将使用时尚MNIST数据来训练DCGAN。 -
数据加载
Fashion MNIST数据集具有训练/测试分割。使用训练数据或加载两个训练/测试数据集用于训练目的。对于具有Fashion MNIST的DCGAN,仅使用训练数据集进行训练就足够了
使用train_images.shape查看Fashion MNIST训练数据形状,并注意到(60000,28,28)的形状,这意味着有60000个28x28大小的训练灰度图像。 -
可视化
将训练数据可视化,以了解图像的外观。看看Fashion MNIST灰度28x28x1图片是什么样子 -
数据预处理
加载的数据是(60000,28,28)的形状是灰度级的。因此需要将通道的第4个维度添加为1,并根据TensorFlow中训练的需要将数据类型(从NumPy数组)转换为float32。
将输入图像归一化到[-1,1]的范围,因为生成器的最终层激活使用了前面提到的tanh。
防止电脑内存占到100% 死机,只选择100张照片作为训练数据集 -
生成器模型
生成器的工作是生成看似合理的图像。它的目的是试图欺骗鉴别器,使其认为生成的图像是真实的。
生成器将随机噪声作为输入,并输出与训练图像相似的图像。由于我们在这里生成的是28x28灰度图像,因此模型架构需要确保得到的形状使得生成器输出应该是28x28x1
使用Reshape层将1D随机噪声(潜在矢量)转换为3D
在Fashion MNIST的情况下,用Keras Conv2DTranspose层(论文中提到的分数阶跨步卷积)上采样几次,达到输出图像大小,即28x28x1形状的灰度图像。
有几层构成了G的构建块:
密集(完全连接)层:仅用于重塑和平坦噪声矢量
Conv2DTranspose:上采样
BatchNormalization:稳定训练;在conv层之后和激活功能之前。
除了使用tanh的输出之外,所有层都使用G中的ReLU激活。 -
鉴别器模型
鉴别器是一个简单的二元分类器,可以告诉图像是真还是假。它的目的是试图对图像进行正确的分类。鉴别器和常规分类器之间有一些区别:
使用LeakyReLU作为DCGAN论文中的激活函数。
鉴别器有两组输入图像:标记为1的训练数据集或真实图像,以及标记为0的生成器创建的伪图像。
注意:鉴别器网络通常比生成器更小或更简单,因为鉴别器的工作比生成器容易得多。如果鉴别器太强,那么发生器就不会有很好的改善。
创建方法以构建鉴别器,输入为真实的图像和生成器生成的图像,及图像的宽/高/深,LeakyReLU的值
Fashion MNIST的图像大小为28x28x1,这些图像作为argos传递到宽度、高度和深度的函数中。alpha表示LeakyReLU用于定义泄漏的斜率。 -
损失函数:修改后的极大极小损失
在创建DCGAN模型之前,先讨论一下损失函数。计算损失是DCGAN(或任何GAN)训练的核心。对于DCGAN将实现修改的极大极小损失,它使用二进制交叉熵(BCE)损失函数。随着在GAN系列中的进展将了解不同GAN变体中的其他损失函数。
需要计算两个损失:一个用于鉴别器损失,另一个用于生成器损失。
鉴别器损失: 由于有两组图像被输入鉴别器(真实图像和伪图像),将计算每组图像的损失,并将它们组合作为鉴别器损失。
生成器损失: 对于生成器损失可以训练G来最大化log D(G(z)),而不是训练G来最小化log(1−D(G))。这就是修正后的极小极大损失。 -
DCGAN模型:覆盖train_step
已经定义了生成器和鉴别器架构,并了解了损失函数是如何工作的。准备好将D和G放在一起,通过子类化keras.model并重写train_step()来训练鉴别器和生成器,从而创建DCGAN模型。
以下是关于如何编写低级别代码以自定义model.fit()的文档。这种方法的优点是仍然可以使用GradientTape进行自定义训练循环,同时仍然可以受益于fit()的方便功能(例如,回调和内置分发支持等)。
因此对keras.Model进行子类化,以创建DCGAN类–类DCGAN(keras.MModel)
用真实图像(标记为1)和伪图像(标记为0)来训练鉴别器
在真实图像上计算鉴别器损失
在伪图像上计算鉴别器损失
总的鉴别器损失
计算鉴别器梯度gradients
更新鉴别器权重
不更新鉴别器权重的情况下训练生成器
计算生成器梯度
更新生成器权重 -
训练期间的监控和可视化:覆盖Keras callback()来监控鉴别器/生成器损失
例如,对于图像分类,损失可以帮助了解模型的性能。对于GAN,D损失和G损失表明每个模型是如何单独执行的,可能是也可能不是GAN模型总体执行情况的准确衡量标准。我
们将在“GAN培训挑战”的下一篇文章中对此进行进一步讨论
对于GAN评估,对训练过程中生成的图像进行视觉检查是很重要的,未来将学习其他评估方法。
训练50个循环,GPU下每个循环只耗时25s
训练过程中,可以可视的检查图像以确定生成器的图像质量
分别查看 第1次,25次,50次训练后生成的Fashion-MNIST图像,可以看到生成器变的越来越好。
使用generator.summary()查看定义的生成器模型架构,以确保每一层都是想要的形状
3. 源码
# 同时训练两个网络:一个生成器和一个鉴别器。为了创建DCGAN模型,首先需要使用Keras Sequential API定义生成器和鉴别器的模型体系结构。然后使用Keras模型子类化来创建DCGAN。
#
# 启用Colab GPU,要在Colab中启用GPU运行时,请转到编辑→ 笔记本设置或运行时→ 更改运行时类型,然后从硬件加速器下拉菜单中选择“GPU”。
# 导入包,使用TensorFlow 2/Keras编写代码,并使用matplotlib进行可视化。
# USAGE
# python dcgan_minist.py
import tensorflow as tf
from matplotlib import pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
# 数据
# 第一步是为训练做好数据准备。将使用时尚MNIST数据来训练DCGAN。
# 数据加载
# Fashion MNIST数据集具有训练/测试分割。使用训练数据或加载两个训练/测试数据集用于训练目的。对于具有Fashion MNIST的DCGAN,仅使用训练数据集进行训练就足够了
(train_images, train_labels), (_, _) = tf.keras.datasets.fashion_mnist.load_data()
# 使用train_images.shape查看Fashion MNIST训练数据形状,并注意到(60000,28,28)的形状,这意味着有60000个28x28大小的训练灰度图像。
# 可视化
# 将训练数据可视化,以了解图像的外观。看看Fashion MNIST灰度28x28x1图片是什么样子
plt.figure()
plt.imshow(train_images[0], cmap='gray')
plt.show()
# 数据预处理
# 加载的数据是(60000,28,28)的形状是灰度级的。因此需要将通道的第4个维度添加为1,并根据TensorFlow中训练的需要将数据类型(从NumPy数组)转换为float32。
# 将输入图像归一化到[-1,1]的范围,因为生成器的最终层激活使用了前面提到的tanh。
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5
print(train_images[0].shape)
# train_images = tf.convert_to_tensor(train_images)
# 防止电脑内存占到100% 死机,只选择100张照片作为训练数据集
train_images = tf.convert_to_tensor(train_images[:20])
# 随机噪声的潜在维数
LATENT_DIM = 100
# 生成器模型
# 生成器的工作是生成看似合理的图像。它的目的是试图欺骗鉴别器,使其认为生成的图像是真实的。
# 生成器将随机噪声作为输入,并输出与训练图像相似的图像。由于我们在这里生成的是28x28灰度图像,因此模型架构需要确保得到的形状使得生成器输出应该是28x28x1
# 使用Reshape层将1D随机噪声(潜在矢量)转换为3D
# 在Fashion MNIST的情况下,用Keras Conv2DTranspose层(论文中提到的分数阶跨步卷积)上采样几次,达到输出图像大小,即28x28x1形状的灰度图像。
# 有几层构成了G的构建块:
# 密集(完全连接)层:仅用于重塑和平坦噪声矢量
# Conv2DTranspose:上采样
# BatchNormalization:稳定训练;在conv层之后和激活功能之前。
# 除了使用tanh的输出之外,所有层都使用G中的ReLU激活。
def build_generator():
# Con2DTranspose层的权重初始化
WEIGHT_INIT = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
# 图像的颜色通道, 1 for gray scale and 3 for color images
CHANNELS = 1
# 使用Keras Sequential API创建模型
model = Sequential(name='generator')
# 定义一个密集层 为重塑为3D做准备,并确保在模型架构的第一层中定义输入形状。添加BatchNormalization和ReLU层
model.add(layers.Dense(7 * 7 * 256, input_dim=LATENT_DIM))
model.add(layers.BatchNormalization())
model.add(layers.ReLU())
# reshape 1D 为 3D
model.add(layers.Reshape((7, 7, 256)))
# 2次使用2步阶的Conv2DTranspose 以获取7x7 to 14x14 to 28x28 在每个Conv2DTranspose层后提娜佳ReLU激活层
# upsample to 14x14: apply a transposed CONV => BN => RELU
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(2, 2), padding="same", kernel_initializer=WEIGHT_INIT))
model.add(layers.BatchNormalization())
model.add((layers.ReLU()))
# upsample to 28x28: apply a transposed CONV => BN => RELU
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding="same", kernel_initializer=WEIGHT_INIT))
model.add(layers.BatchNormalization())
model.add((layers.ReLU()))
# 最后使用tanh为激活函数的Conv2D层
# 注意:CHANNELS之前被定义为1,这将生成28x28x1的图像,与原始的灰度训练图像相匹配。
model.add(layers.Conv2D(CHANNELS, (5, 5), padding="same", activation="tanh"))
return model
# 鉴别器模型
# 鉴别器是一个简单的二元分类器,可以告诉图像是真还是假。它的目的是试图对图像进行正确的分类。鉴别器和常规分类器之间有一些区别:
# 使用LeakyReLU作为DCGAN论文中的激活函数。
# 鉴别器有两组输入图像:标记为1的训练数据集或真实图像,以及标记为0的生成器创建的伪图像。
# 注意:鉴别器网络通常比生成器更小或更简单,因为鉴别器的工作比生成器容易得多。如果鉴别器太强,那么发生器就不会有很好的改善。
# 创建方法以构建鉴别器,输入为真实的图像和生成器生成的图像,及图像的宽/高/深,LeakyReLU的值
# Fashion MNIST的图像大小为28x28x1,这些图像作为argos传递到宽度、高度和深度的函数中。alpha表示LeakyReLU用于定义泄漏的斜率。
def build_discriminator(width, height, depth, alpha=0.2):
# 使用Keras Sequential API创建模型
model = Sequential(name='discriminator')
input_shape = (height, width, depth)
# We use Conv2D, BatchNormalization, and LeakyReLU twice to downsample.
# 使用Conv2D, BatchNormalization, and LeakyReLU 2次以进行下采样
# first set of CONV => BN => leaky ReLU layers
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding="same", input_shape=input_shape))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU(alpha=alpha))
# second set of CONV => BN => leacy ReLU layers
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding="same"))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU(alpha=alpha))
# Flatten and apply dropout 展平以及应用dropout
model.add(layers.Flatten())
model.add(layers.Dropout(0.3))
# 最后一层使用 sigmoid激活函数一输出二进制分类(binary classification)的结果
model.add(layers.Dense(1, activation="sigmoid"))
return model
# 损失函数:修改后的极大极小损失
# 在创建DCGAN模型之前,先讨论一下损失函数。计算损失是DCGAN(或任何GAN)训练的核心。对于DCGAN将实现修改的极大极小损失,它使用二进制交叉熵(BCE)损失函数。随着在GAN系列中的进展将了解不同GAN变体中的其他损失函数。
# 需要计算两个损失:一个用于鉴别器损失,另一个用于生成器损失。
# 鉴别器损失
# 由于有两组图像被输入鉴别器(真实图像和伪图像),将计算每组图像的损失,并将它们组合作为鉴别器损失。
# total_D_loss = loss_from_real_images + loss_from_fake_images
# 生成器损失
# 对于生成器损失可以训练G来最大化log D(G(z)),而不是训练G来最小化log(1−D(G))。这就是修正后的极小极大损失。
class DCGAN(keras.Model):
def __init__(self, discriminator, generator, latent_dim):
super(DCGAN, self).__init__()
self.discriminator = discriminator
self.generator = generator
self.latent_dim = latent_dim
def compile(self, d_optimizer, g_optimizer, loss_fn):
super(DCGAN, self).compile()
self.d_optimizer = d_optimizer
self.g_optimizer = g_optimizer
self.loss_fn = loss_fn
self.d_loss_metric = keras.metrics.Mean(name="d_loss")
self.g_loss_metric = keras.metrics.Mean(name="g_loss")
@property
def metrics(self):
return [self.d_loss_metric, self.g_loss_metric]
# DCGAN模型:覆盖train_step
# 已经定义了生成器和鉴别器架构,并了解了损失函数是如何工作的。准备好将D和G放在一起,通过子类化keras.model并重写train_step()来训练鉴别器和生成器,从而创建DCGAN模型。
# 以下是关于如何编写低级别代码以自定义model.fit()的文档。这种方法的优点是仍然可以使用GradientTape进行自定义训练循环,同时仍然可以受益于fit()的方便功能(例如,回调和内置分发支持等)。
# 因此对keras.Model进行子类化,以创建DCGAN类–类DCGAN(keras.MModel)
def train_step(self, real_images):
batch_size = tf.shape(real_images)[0]
noise = tf.random.normal(shape=(batch_size, self.latent_dim))
# 用真实图像(标记为1)和伪图像(标记为0)来训练鉴别器
with tf.GradientTape() as tape:
# 在真实图像上计算鉴别器损失
pred_real = self.discriminator(real_images, training=True)
d_loss_real = self.loss_fn(tf.ones((batch_size, 1)), pred_real)
# 在伪图像上计算鉴别器损失
fake_images = self.generator(noise)
pred_fake = self.discriminator(fake_images, training=True)
d_loss_fake = self.loss_fn(tf.zeros((batch_size, 1)), pred_fake)
# 总的鉴别器损失
d_loss = (d_loss_real + d_loss_fake) / 2
# 计算鉴别器梯度gradients
grads = tape.gradient(d_loss, self.discriminator.trainable_variables)
# 更新鉴别器权重
self.d_optimizer.apply_gradients(zip(grads, self.discriminator.trainable_variables))
# We train the generator while not updating the weights of the discriminator.
# 不更新鉴别器权重的情况下训练生成器
misleading_labels = tf.ones((batch_size, 1))
with tf.GradientTape() as tape:
fake_images = self.generator(noise, training=True)
pred_fake = self.discriminator(fake_images, training=True)
g_loss = self.loss_fn(misleading_labels, pred_fake)
# 计算生成器梯度
grads = tape.gradient(g_loss, self.generator.trainable_variables)
# 更新生成器权重
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_variables))
self.d_loss_metric.update_state(d_loss)
self.g_loss_metric.update_state(g_loss)
return {
"d_loss": self.d_loss_metric.result(),
"g_loss": self.g_loss_metric.result(),
}
# 训练期间的监控和可视化:覆盖Keras callback()来监控鉴别器/生成器损失
# 例如,对于图像分类,损失可以帮助了解模型的性能。对于GAN,D损失和G损失表明每个模型是如何单独执行的,可能是也可能不是GAN模型总体执行情况的准确衡量标准。我
# 们将在“GAN培训挑战”的下一篇文章中对此进行进一步讨论
# 对于GAN评估,对训练过程中生成的图像进行视觉检查是很重要的,未来将学习其他评估方法。
# 训练50个循环,GPU下每个循环只耗时25s
# 训练过程中,可以可视的检查图像以确定生成器的图像质量
# 分别查看 第1次,25次,50次训练后生成的Fashion-MNIST图像,可以看到生成器变的越来越好。
class GANMonitor(keras.callbacks.Callback):
def __init__(self, num_img=3, latent_dim=128):
self.num_img = num_img
self.latent_dim = latent_dim
def on_epoch_end(self, epoch, logs=None):
random_latent_vectors = tf.random.normal(shape=(self.num_img, self.latent_dim))
generated_images = self.model.generator(random_latent_vectors)
generated_images *= 255
generated_images.numpy()
for i in range(self.num_img):
img = keras.preprocessing.image.array_to_img(generated_images[i])
img.save("images/generated_img_%03d_%d.png" % (epoch, i))
generator = build_generator()
# 使用generator.summary()查看定义的生成器模型架构,以确保每一层都是想要的形状
print(generator.summary())
discriminator = build_discriminator(width=28, height=28, depth=1, alpha=0.2)
print(discriminator.summary())
# 编译和训练模型
dcgan = DCGAN(discriminator=discriminator, generator=generator, latent_dim=LATENT_DIM)
LR = 0.0002 # learning rate
# 如DCGAN论文所建议的,使用Adam优化器,生成器和鉴别器的学习率均为0.0002。对D和G都使用二进制交叉熵损失函数。
dcgan.compile(
d_optimizer=keras.optimizers.Adam(learning_rate=LR, beta_1=0.5),
g_optimizer=keras.optimizers.Adam(learning_rate=LR, beta_1=0.5),
loss_fn=keras.losses.BinaryCrossentropy(),
)
# 简单的调用model.fit 训练DCGAN模型
NUM_EPOCHS = 50 # number of epochs
dcgan.fit(train_images, epochs=NUM_EPOCHS,
callbacks=[GANMonitor(num_img=16, latent_dim=LATENT_DIM)])
















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











