








CNN卷积神经网络 convolution nulear network
应用场景
图像识别、根据轮廓识别的图像识别
算法逻辑
算法学得好的话,一眼就可以看出MLP就是暴力算法,时间效率低。因此希望提升效率。
剪枝方法: 先提取图像的关键信息(轮廓),再对其进行mlp模型训练
图像卷积运算: 用于提取图像的关键信息。数学原理是,对图像矩阵与滤波器矩阵进行对应相乘再求和运算,从而得到新的矩阵,这样
轮廓过滤器
数学原理讲解链接
轮廓过滤器: 根据上述数学原理证明,在这样的矩阵乘法下, 可以快速定位轮廓特征。可以寻找横向轮廓过滤器、纵向轮廓过滤器、sobel过滤器
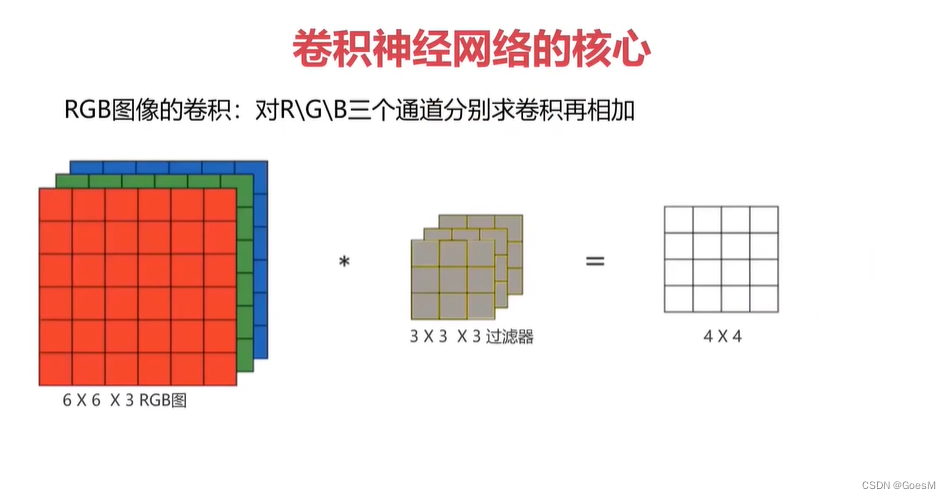
对于彩色图片,彩色图片是由三张图组成(即red,green,blue),图片是单张图的规格是xy3大小,因此需要对3个图分别进行卷积,再相加
池化
池化层实现维度缩减: 按照一定规则对图像矩阵进行处理,将其转换为更低维度的矩阵
最大池化法
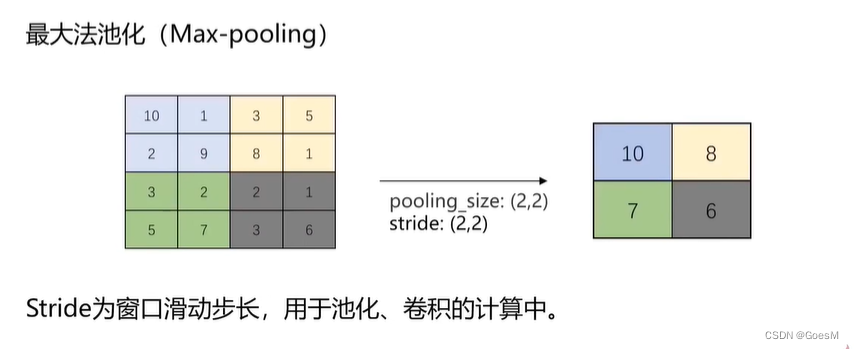
poolint_size 指 滑动窗口的大小
stride(2,2) 表示窗口的滑动步长
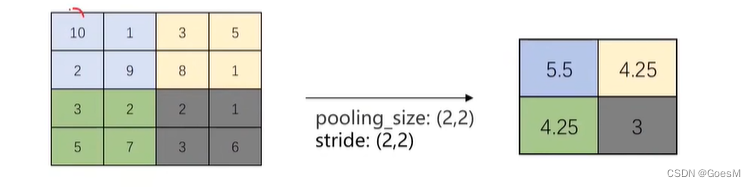
平均法池化
激活函数relu函数
f(x) = max(x,0)
作用:使得部分神经元为0,防止过拟合;有助于模型求解
算法效果
参数共享
同一个特征过滤器可以用于整张图片。
(可以用竖向特征过滤器,将整个图片中的竖向轮廓获取)
稀疏连接
生成的特征图片的每个节点只与原图中的特殊节点连接
依据:轮廓具有连续性,因此可以降低计算数据量的同时,不会对核心信息折损。
边缘信息折损
滑动窗口方法带来的问题:边缘信息只被计算少次,而中间信息会被多次计算
解决:图像填充在边缘添加新的空像素。
经典的CNN模型
LeNet-5
输入:32*32灰度图
训练参数:约60,000个
特点:1. 随着网络越深,图像高度和宽度越小,通道数增加
2. 卷积与池化先后成对使用
LeNet-5 论文
流程图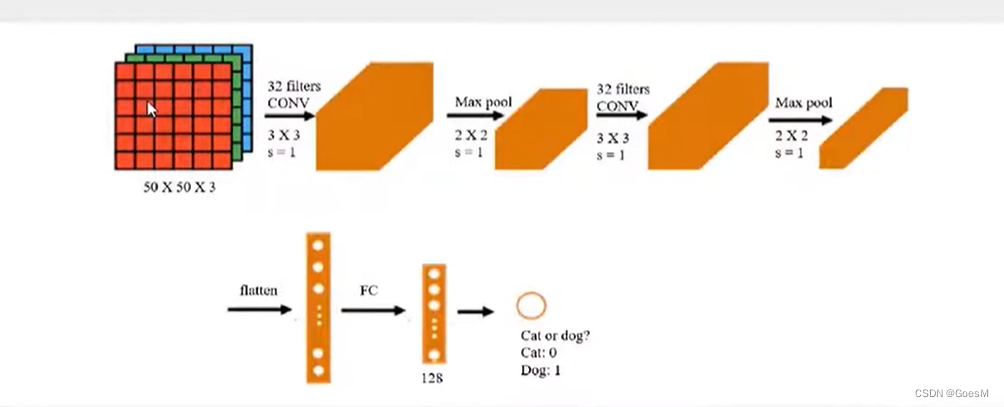
AlexNet
输入:2272273 RGB图(彩色图)
训练参数:60,000,000个
特点:1. 适用于识别较为复杂的彩色图,可识别1000种类别
2. 结构比LeNet更复杂,使用Relu作为激活函数
AlexNet 论文
VGG-16
输入:2242243 RGB图(彩色图)
训练参数:138,000,000个
特点:1. 所有卷积层的filter的宽和高都是3,步长为1
2. 所有池化层filter的宽和高都是2,步长为2
3. 相比alexnet,有更多的filter用于提取轮廓信息,具更高精准性
使用介绍
python中的VGG包,主要用于抓取图片特征;一般借助VGG算法抓取特征后,通过MLP算法进行训练和预测
算法流程
step1. 图像加载
step 2. 图像预处理
图像增强
图像预处理
数值归一化
旋转、缩放、平移
step 3. 建立模型
模型结构
卷积层
池化层
CNN实战
任务一:猫和狗识别 (基于CNN模型实现)
基于dataset\training_set数据,建立CNN模型
进行训练数据集的训练,并从网上下载任意猫和狗的图片,对其进行预测
数据加载与预处理
from keras.preprocessing.image import ImageDataGenerator
#图像预处理
train_datagen = ImageDataGenerator (rescale = 1./255)
#图像加载
training_set = train_datagen.flow_from_directory(
'./Dataset/training_set', # 从文件夹加载图像
target_size = (50,50), #图像尺寸转换为 50*50
batch_size =32, #CNN求解时,每次选取32个图片进行求解
#batchsize越小,loss函数下降越不稳定
class_mode = 'binary' #采取二分类模式
)
建立CNN模型
from keras.models import Sequential
from keras.layers import Conv2D,MaxPooling2D,Flatten,Dense
#顺序模型
model = Sequential()
#卷积层
model.add(
Conv2D(
32,(3,3), #32个 3*3 大小的 过滤器
input_shape = (50,50,3), #输入数据为50*50的RBG图
activation = 'relu',# 激活函数用relu
)
)
#池化层
model.add(
MaxPooling2D(
pool_size=(2,2),#用2*2大小的池子
strides=None, #步幅大小默认为1
)
)
# 根据情况多添加几个(卷积、池化)层组
#Flattening层
model.add(Flatten()) #作用:把m行n列,转换为m*n行1列
#隐藏层
model.add(Dense(units=128,activation='relu'))
#输出层
model.add(Dense(units=1,activation='sigmoid'))
训练与评估
#配置模型
#参数配置
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
#查看模型结构
model.summary()
#训练模型
model.fit_generator(training_set, epochs=25)
#评估模型
model.evaluate_generator(training_set)
标签编码表
training_set.class_indices
任务二:猫狗识别(基于VGG16模型,结合MLP模型实现)
基于dataset\data_vgg数据,建立CNN模型
进行训练数据集的训练,并从网上下载任意猫和狗的图片,对其进行预测
Step1. 构建特征抓取函数(VGG-16算法)
‘-VGG模型建立-’
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
#VGG 模型
model_vgg = VGG16(
weights='imagenet', #图像的特征提取结构
include_top=False # 不需要全连接层
)
‘-特征抓取函数-’ :仅保留图片的特征部分,返回值仍为图片
import numpy as np
from keras.utils import image_utils
#抓取函数
def feature_catch(img_path,model):
img = image_utils.load_img(
img_path,
target_size=(224,224)
)
img = image_utils.img_to_array(img)
x = np.expand_dims(img,axis=0) #x是 增加一个维度后的img
x = preprocess_input(x)
x_vgg = model.predict(x) #x仍为图片形式
x_vgg = x_vgg.reshape(1,7*7*512) #x被摊开为一维数组
# 7*7*512这个参数,源自于单图特征抓取实验后显示的结果
return x_vgg
# 调用即可
Step 2. 训练数据集导入 与 特征抓取
features = []
label = []
num = int(input("从训练集提取多少张图片进行训练?(1.2w以内整数)"))
#猫图特征抓取
for i in range(0,num):
img_path = './文件夹/cat.'+str(i)+'.jpg'
res = feature_catch(img_path,model_vgg)
res = res.reshape(7*7*512)
features.append(res)
label.append('cat')
#狗图特征抓取
for i in range(0,num):
img_path = './文件夹/dog.'+str(i)+'.jpg'
res = feature_catch(img_path,model_vgg)
res = res.reshape(7*7*512)
features.append(res)
label.append('dog')
print('-----------Feature-Catch finished--------------')
Step 3. 数据分离
Step 4. MLP模型建立
Step 5. MLP模型训练
Step 6. 预测与评估
step3 ~ step6 与 前文提到的MLP算法一致。
小结
即:从逻辑上来说,VGG算法的作用就是,把图像信息中重要的特征进行了抓取,每张图片的特征信息最终都被转换为一维数组的形式。
设 特征信息的像素 有n个点,
则 问题转换为:n维数据 与 标签 的分类问题
因此后续直接使用MLP求解即可。
补:单图预测的代码
from keras.utils import image_utils
from matplotlib import pyplot as plt
#图片导入
img_path = '1.jpg'
img = image_utils.load_img(
img_path,
target_size=(224,224)
)
plt.imshow(img)
plt.show()
img = image_utils.img_to_array(img)
type(img)
# 图片特征抓取
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
#格式转换
x = np.expand_dims(img,axis=0) #x是 增加一个维度后的img
x = preprocess_input(x)
print(x.shape)
#特征提取
features = model_vgg.predict(x)
print('features.shape',features.shape)
#flatten,摊开成一维数组
features = features.reshape(1,7*7*512)
#prediction
result = model.predict(features)
result=np.argmax(result,axis=1)
print(result,end=":")
if(result[0]==1):
print("This is a dog!")
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











