







本文主要为pg059的学习笔记
待补充,预计完成时间为8月13号前
AXI-Interconnect 学习总结
一、概述
AXI互连IP只能在Vivado Design Suite中的Vivado™ IP Integrator Block Design中添加。(现在也可以通过AXI-Interconnect RTL生成)Interconnect IP代表一个层次化的设计块,其中包含多个LogiCORE™ IP实例(基础架构 IP),在系统设计会话期间进行配置和连接。每个基础架构 IP也可以直接添加到Block Design(在AXI Interconnect之外),或直接从Vivado IP Catalog中选择并配置用于HDL设计。
AXI Interconnect IP允许将任意组合的AXI主设备和从设备连接到它,这些设备在数据宽度、时钟域和AXI子协议(AXI4、AXI3或AXI4-Lite)方面可能互不相同。当任何连接的主设备或从设备的接口特性与互连内部的交叉开关不同时,将自动推断并连接适当的基础架构 IP在互连内执行必要的转换。
AXI Infrastructure Cores
根据AXI Interconnect的配置和在IP Integrator Block Design中的连接情况,可以在每个AXI Interconnect实例中包含以下IP IP:
AXI交叉开关(AXI Crossbar):将一个或多个类似的AXI内存映射主设备连接到一个或多个类似的内存映射从设备。
AXI数据宽度转换器(AXI Data Width Converter):将一个AXI内存映射主设备连接到一个数据宽度更宽或更窄的AXI内存映射从设备。
AXI时钟转换器(AXI Clock Converter):将一个AXI内存映射主设备连接到一个在不同时钟域中工作的AXI内存映射从设备。
AXI协议转换器(AXI Protocol Converter):将一个AXI4、AXI3或AXI4-Lite主设备连接到使用不同AXI内存映射协议的AXI从设备。
AXI数据FIFO(AXI Data FIFO):通过一组FIFO缓冲区将一个AXI内存映射主设备连接到一个AXI内存映射从设备。
AXI寄存器切片(AXI Register Slice):通过一组流水线寄存器将一个AXI内存映射主设备连接到一个AXI内存映射从设备,通常用于打破关键时序路径。
Feature Summary
AXI Crossbar
- 每个AXI互连实例都包含一个AXI交叉开关实例(前提是配置了多个SI或多个MI)。
- AXI交叉开关 IP的从设备接口(SI)可以配置为包含1-16个SI插槽,用于接收来自最多16个连接的主设备的事务。主设备接口(MI)可以配置为包含1-16个MI插槽,用于向最多16个连接的从设备发出事务。
- 可选的互连架构
- 1)交叉开关模式(性能优化)
- 共享地址、多数据(SAMD)交叉开关架构。
- 并行交叉开关路径用于写数据和读数据通道。当多个写数据源或读数据源要发送数据到不同的目的地时,数据传输可以独立且并发进行,前提是满足AXI排序规则。(预计需要端口buf缓存实现)
- 根据配置的连接性映射进行稀疏交叉开关数据路径配置,从而降低资源利用率。
- 一个共享写地址仲裁器,加上一个共享读地址仲裁器。在事务平均至少有三个数据beat时,仲裁延迟通常不会影响数据吞吐量。(读写的仲裁分别实现,“至少有三个数据beat”,这应该是仲裁导致的延迟,需要具体的分析了)
- 仅当AXI交叉开关配置为AXI4或AXI3协议时,才可使用交叉开关模式。
- 2)、共享访问模式(面积优化)
- 共享写数据、共享读数据和单共享地址通道。
- 一次只发出一个未完成的事务。
- 最小化资源利用率。
- 1)交叉开关模式(性能优化)
- 支持多个未完成事务(交叉开关模式)
- 支持具有多个重新排序深度(ID线程)的连接主设备。
- 支持具有可变ID宽度的最多32位宽度的ID信号,每个连接的主设备。
- 支持写响应重新排序、读数据重新排序和读数据交错。
- 可配置的每个连接主设备的写和读事务接受限制。
- 可配置的每个连接从设备的写和读事务发出限制。
- 可选的单线程模式(每个连接的主设备)通过允许一次只有一个线程ID的一个或多个未完成的事务,从而减少线程控制逻辑。
- “每个ID一个从设备”方法用于循环依赖(死锁)避免 对于由连接的主设备发出的每个ID线程,互连允许一次只有一个从设备用于写入事务和一个从设备用于读取事务的未完成事务。
- 固定优先级和循环优先级仲裁
- 16个可配置的静态优先级级别。
- 当没有更高优先级的主设备请求时,使用循环优先级仲裁在所有已配置最低优先级设置(优先级0)的连接主设备之间进行。
- 任何达到其接受限制的SI插槽,或者将MI插槽的发出限制耗尽的SI插槽,或者以可能导致死锁的方式尝试访问MI插槽的SI插槽,在仲裁过程中暂时被取消资格,以便其他SI插槽可以获得仲裁权限。
- 对每个连接的从设备作为一个整体支持TrustZone安全性
- 如果配置为安全从设备,则仅允许安全AXI访问。
- 任何非安全访问都将被阻止,并且AXI互连 IP会向连接的主设备返回DECERR响应。
- 生成用于具有多个地址解码范围的从设备的REGION输出。
AXI Data Width Converter
- SI数据宽度:32、64、128、256、512或1024位
- MI数据宽度:32、64、128、256、512或1024位(必须与SI数据宽度不同)
- 在扩展数据宽度时,数据根据地址通道控制信号(CACHE可修改位被设置)允许时进行打包(合并)。
- 在缩小数据宽度时,如果超过最大突发长度,则突发事务将分割为多个事务。
- 在扩展数据宽度时,该IP可以选择以资源高效的方式执行FIFO缓冲和时钟频率转换(同步或异步)。
AXI Clock Converter
- 同步整数比率(N:1和1:N)转换,其中2<=N<=16。
- 异步时钟转换(与同步转换相比,使用更多存储并产生更多延迟)。
AXI Protocol Converter
- AXI4或AXI3到AXI4-Lite协议转换
- 存储在SI上接收的AWID和ARID值,并在响应传输期间恢复为BID/RID。
- 将突发传输转换为一系列AXI4-Lite单拍传输。
- 写入和读取事务被多路复用到AXI4-Lite从设备,仅传播一个地址,通常避免了与分开的AXI写入和读取地址信号相关的逻辑资源的重复。
- AXI4到AXI3协议转换:
- 将连接的AXI4主设备的超过16个拍数的突发传输拆分为多个不超过16个拍数的传输。 (AXI3 BURST LEN <= 16)
- 拆分的传输是单线程的,以强制按顺序合并响应传输。
- 所有其他转换将未使用的信号连接到固定值,并不涉及任何逻辑。
AXI Register Slice
- 对于5个AXI通道中的每一个都可以单独配置。 (估计是在发送方向上加)
- 通过在频率和延迟之间进行折衷,有助于实现时序闭合。(手动?)
- 每个寄存器片段有一个延迟周期,在所有AXI握手条件下不会丢失数据吞吐量(发送方向上添加,压根对握手机制没有任何影响)。
AXI Data FIFO
- 对写入和读取数据路径都可以单独配置。
- 基于32个深度的LUT-RAM(查找表RAM)。
- 基于512个深度的块RAM(块RAM)。
- 可选的分组FIFO操作,以避免在突发传输中出现满/空停顿。(非空,非满都有延时,增加FIFO深度可以避免空满标识影响到传输的连续性,从而降低带宽)
Applications
Interconnect是通用的,并且通常在使用AXI内存映射传输的所有系统中部署。
AXI Interconnect Core Limitations
这些限制适用于AXI Interconnect IP:
- AXI Interconnect IP不支持已停用的AXI3特性:
- 原子锁定事务。此功能由AXI4协议撤销。锁定事务会更改为非锁定事务,并由MI传播。
- 写入交错。此功能由AXI4协议撤销。AXI3主设备必须配置得像连接到写入交错深度为1的从设备一样。 (当AXI3配置写入交错时,需要配置写入交错的深度,如果支持写交错,预计需要使用BUF来实现,深度即使用的buf数,为1即不支持写交错)
- AXI4服务质量(QoS)信号不会影响AXI Crossbar中的仲裁优先级。QoS信号会从SI传播到MI(QoS只影响到Host,不会影响到CrossBar)。
- AXI Interconnect IP不支持低功耗模式,也不会传播AXI C通道信号。
- AXI Interconnect IP不会在任何AXI通道传输的目的地无限期停滞时超时。所有连接的AXI从设备必须对所有接收到的事务进行响应,符合AXI协议的要求。
- AXI Interconnect(AXI Crossbar IP)不提供地址重新映射。
- AXI Interconnect子 IP不包括转换或桥接到非AXI协议,比如APB。
- AXI Interconnect IP没有时钟使能(ACLKEN)输入。因此,在Xilinx系统中不支持在内存映射的AXI接口之间使用ACLKEN。
注意:ACLKEN信号支持Xilinx AXI4-Stream接口。
二、规格
图2-1显示了顶层AXI Interconnect IP的框图。在AXI Interconnect内部,Crossbar IP在Slave Interfaces(SI)和Master Interfaces(MI)之间路由流量。连接SI或MI到Crossbar的每条路径上,可以选择性地使用一系列AXI基础设施 IP(耦合器)执行各种转换和缓冲功能。耦合器包括:Register Slice、Data FIFO、Clock Converter、Data Width Converter和Protocol Converter。
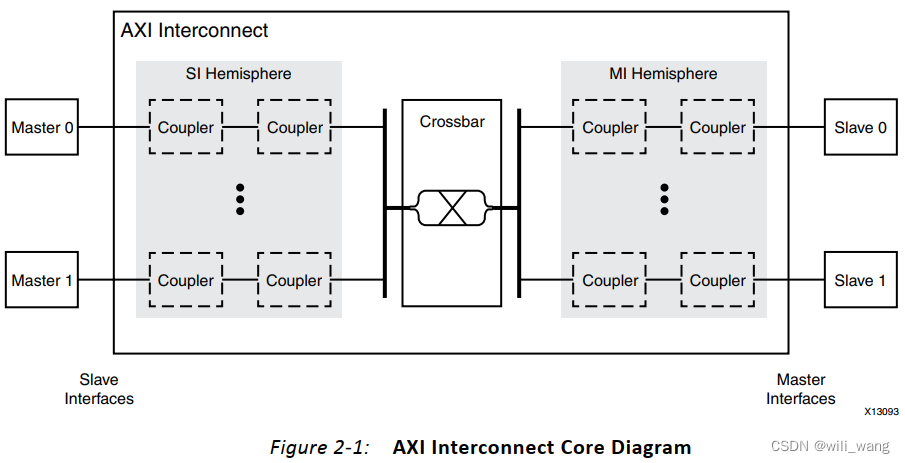
AXI Interconnect IP可配置为具有最多16个Slave Interfaces(SI)和最多16个Master Interfaces(MI)。每个SI连接到一个AXI主设备,接受写入和读取事务请求。每个MI连接到一个AXI从设备,并向从设备发出事务。在中心是Crossbar IP,它在SI和MI之间的所有AXI通道上路由流量。在连接SI和Crossbar之间的每条路径,或在Crossbar和MI之间的每条路径上,可以有一个或多个基础设施 IP,执行各种转换和存储功能。
Crossbar有效地将AXI Interconnect IP分成SI相关的功能单元(SI半球)和MI相关的单元(MI半球)。
Use Models
AXI Interconnect核心将一个或多个AXI内存映射主设备连接到一个或多个内存映射从设备。每个连接的主设备可以是发起AXI事务的核心(端点主设备)或级联的上游AXI Interconnect的主接口。每个连接的从设备可以是AXI事务的最终目标(端点从设备)或级联的下游AXI Interconnect的从接口。连接的主设备或从设备也可以是任何AXI基础设施转换/存储核心,尽管这些功能通常在AXI Interconnect内部执行,以避免在顶层设计中混乱。
每个AXI Interconnect可以配置为执行以下一般连接模式之一:
- N对1互联
- 1对N互联
- N对M互联(Crossbar模式)
- N对M互联(共享访问模式)
Interconnect还可以配置为将一个主设备连接到一个从设备,在这种情况下,IPI将自动实例化和配置沿路径所需的任何耦合器。
N‐to‐1 Interconnect
当多个主设备仲裁以访问单个从设备(例如内存控制器)时,请将AXI Interconnect核心用于N对1配置。 在这种配置中,还可以执行任何可选的转换功能,例如数据宽度和时钟频率转换,如图2-2所示。

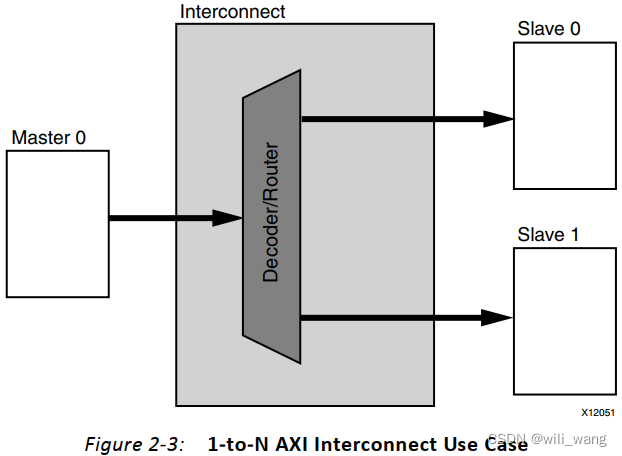
1‐to‐N Interconnect
当单个主设备(通常是处理器)访问多个内存映射从设备(外设)时,请使用1对N配置的AXI Interconnect核心。在这种情况下,不执行仲裁(在地址和写数据路径中),如图2-3所示。
N‐to‐M Interconnect (Crossbar Mode)
AXI Interconnect核心在交叉栏模式下的N对M用例采用共享地址多个数据(SAMD)拓扑结构,包括稀疏数据crossbar连接,带有单个共享的写和读地址仲裁,如图2-4和图2-5所示。


在AXI Interconnect核心中,共享写地址和读地址仲裁以及稀疏交叉栏写数据路径和读数据路径是两种不同的连接模式。
- 共享写地址和读地址仲裁: 在共享仲裁模式下,所有SI槽之间的写入地址通道和读取地址通道都连接到中央地址仲裁器。这个仲裁器负责从所有请求的主设备中选择一个,然后将其地址信息传输到目标MI槽,以启用到目标从设备的写入或读取数据传输。这种模式下一次只允许一个未完成的事务,读取事务请求优先于写入。共享仲裁模式可以最小化交叉栏模块所使用的资源。
- 稀疏交叉 写数据路径和读数据路径: 在稀疏交叉栏模式下,每个SI槽通过并行的写数据路径和读数据路径连接到所有可访问的MI槽。这些路径根据配置的稀疏连接映射,允许多个源以并行和独立的方式向不同的目标发送数据,只要满足AXI排序规则。这种模式下,不需要中央地址仲裁器,从而减少了数据路径的多路复用逻辑和地址解码逻辑,从而减少FPGA资源利用率和加快时序路径。
总体来说,共享写地址和读地址仲裁是一种传统的模式,一次只允许一个未完成的事务,并通过中央仲裁器选择下一个请求。而稀疏交叉栏写数据路径和读数据路径允许多个源并行地发送数据,没有中央仲裁器,从而提高了系统吞吐量和时序性能。选择使用哪种模式取决于具体的设计要求和性能目标。
并行的写入和读取数据路径将每个SI槽与其可以访问的所有MI槽连接起来,根据配置的稀疏连接映射。当多个源有数据发送到不同的目标时,只要满足AXI排序规则,数据传输可以独立并发地进行。通过禁用未使用的路径,可以减少数据路径多路复用逻辑和地址解码逻辑,从而减少FPGA资源利用率并加快时序路径。
所有SI槽之间的写入地址通道都连接到中央地址仲裁器,该仲裁器一次只授予一个SI槽访问权限。读取地址通道也是如此。每次仲裁周期的赢家将其地址信息传输到目标MI槽,并在适当的命令队列中推送一个条目,以使各种数据路径将数据路由到正确的目标,同时执行AXI排序规则。
交叉栏模式仅在AXI Crossbar配置为AXI4或AXI3协议时可用。
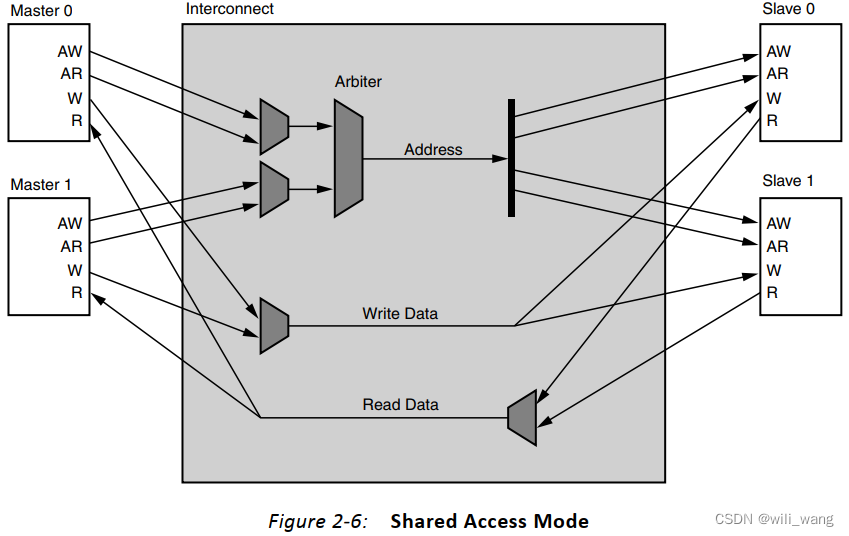
N‐to‐M Interconnect (Shared Access Mode)
当处于共享访问模式时,AXI互连核心的N到M用例提供一次只有一个未完成的事务(单次发出),如图2-6所示。对于每个连接的主设备,读取事务请求始终优先于写入。然后,仲裁器从请求的主设备中选择一个,并启用向目标从设备的写入或读取数据传输。在数据传输(包括写入响应)完成后,进行下一个请求的仲裁。共享访问模式最小化了实现互连交叉栏模块所使用的资源。
共享访问模式在AXI交叉栏配置为任何AXI协议时都可用,但在配置为AXI4-Lite时始终使用该模式。
Standards
AXI接口符合来自ARM(Advanced RISC Machine)的高级微控制器总线体系结构(AMBA®)AXI版本4规范,包括AXI4-Lite控制寄存器接口子集。详见ARM AMBA AXI Protocol v2.0。
Latency
根据功能分模块描述了各个模块的延迟。
AXI Crossbar
图2-7显示了交叉开关模块的基本延迟模型。

在图2-7中,基准延迟如下:
-
- T_AW = T_AR = ACLK的2个周期,用于AW/ARVALID的正向传播,前提是没有待处理的条件会阻止授予仲裁(例如更高优先级的请求)。每个仲裁还会导致2个气泡周期,从而在同一SI插槽的连续仲裁之间产生3个周期(最小值)。
- T_WC = ACLK的1个周期。
- T_W = ACLK的1个周期,没有气泡周期(支持连续的连续数据传输)。
- T_R = ACLK的1或2个周期,没有气泡周期(支持连续的连续数据传输)。第二个延迟周期发生在空闲周期后进行重新仲裁(当请求的MI插槽与上次授予的MI插槽不同时)。当相同的MI插槽连续传播数据,或者多个MI插槽连续交错数据时,通过R通道仲裁器的延迟为1个周期。
- T_B(B通道延迟,未显示)= ACLK的1或2个周期。(与T_R相同)
AXI Register Slice
- 完全注册的寄存器切片(每个适用的通道):1个延迟周期,没有气泡周期(最佳情况下可达100%的通道带宽)。
- 轻量级的寄存器切片(每个适用的通道):1个延迟周期,一个气泡周期(最佳情况下可达50%的通道带宽),适用于AW、AR和B通道传输,以及涉及AXI4-Lite端点的所有传输。
AXI Data FIFO
- W和R通道:3个延迟周期,没有气泡周期。
- AW、AR和B通道:如果启用了数据包模式,则为1个延迟周期;否则没有延迟。
AXI Clock Converter
延迟不固定。
AXI Data Width Converter
- AW和AR通道:1个延迟周期。
- W通道向上转换:1个延迟周期(在每个完成打包的周期),SI端(窄)接口没有气泡周期。
- R通道向上转换:1个延迟周期。
- B通道:没有延迟。
- R通道向下转换:没有延迟(在每个完成打包的周期),MI端(窄)接口没有气泡周期。
- W通道向下转换:没有延迟。
AXI Protocol Converter
- AXI4或AXI3到AXI4-Lite的转换:所有通道都没有延迟。
- AXI4到AXI3的转换:
- AW和AR通道:1个延迟周期。
- W、R和B通道:没有延迟。
- 其他转换:没有延迟。
Resource Utilization
本节中的表格显示了AXI互联核心中各个模块的预估FPGA资源利用情况。这些值是使用Vivado™ Design Suite生成的。它们是根据后综合报告得出的,可能在映射(MAP)和布局布线(PAR)期间发生变化。
列出了每个模块的一些典型配置。可以通过累积所有组成模块的利用率来估算给定AXI互联实例的总面积。
AXI Crossbar Resource Utilization: SAMD, AXI4 Protocol
Common Configuration
- 连接模式:SAMD(最大性能策略)
- 协议:AXI4或AXI3
- 数据宽度:64(数据宽度降级因子在表中显示。)
- 读/写连接性:所有MI完全连接(只读和只写降级因子在表中显示。)
- 线程ID宽度:2(所有SI)
- 地址宽度:全局=32;每个MI=16(1个地址范围)
- 读/写接收:4
- 读/写发出:8
- 仲裁优先级:0(轮询)
- 单线程:禁用
- 用户宽度:0
- 目标设备:xc7vx485t
Table Cell Key
AXI Crossbar Resource Utilization: SASD, AXI4 Protocol
AXI Crossbar Resource Utilization: SASD, AXI4‐Lite Protocol
AXI Clock Converter Resource Utilization
AXI Data FIFO Resource Utilization
AXI Data Width Converter Resource Utilization: AXI4 Upsizer
AXI Data Width Converter Resource Utilization: AXI4 Downsizer
AXI Data Width Converter Resource Utilization: AXI4 Downsizer
AXI Data Width Converter Resource Utilization: AXI4‐Lite
AXI Protocol Converter Resource Utilization
AXI Register Slice Resource Utilization
Port Descriptions
Register Space
本文档中描述的任何IP都不包含任何内存映射的控制或状态寄存器。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









