






读前必看:借鉴业内各位大神的无私分享(由衷感谢),RAG架构相关技术应用点以及相关主要paper及关键技术点推荐【还在不断勘误中,欢迎讨论指正】…
RAG解决的是什么问题?“幻觉”问题,理解不足,文本超长等问题?对于LLM有过丰富的训练、微调经历的,LLM能力在业务场景(特别是高P)显得很无力,生成结果不可控、格式不可控、难以进行二次矫正。
所以,RAG的目的是通过检索+精筛的逻辑,将复杂问题简单化、长文本精简化、噪声剔除,让LLM更容易去理解去生成。但请注意,当前阶段来看,RAG也不能解决,仅仅知识缓解,但长远来看,硬件能力提升、高质量数据统一、算法的完备,会促使LLM取代RAG。
RAG更像一个权衡当前LLM技术之后,在应用中产生的中间产物!!
Retrieval-Augmented Generation: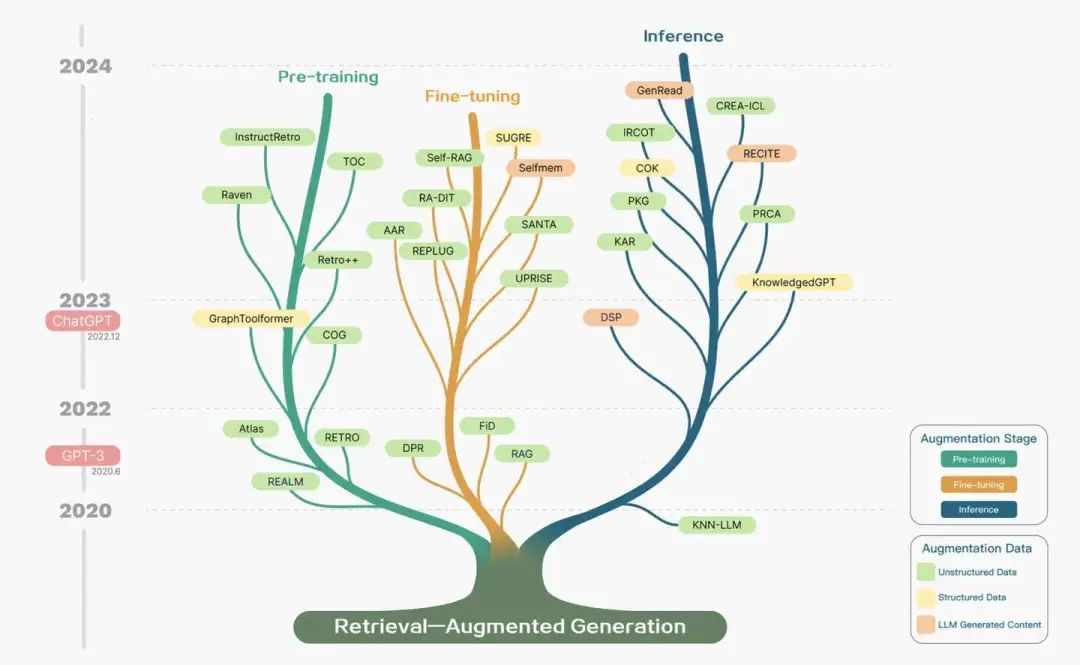
开源RAG/Agent总结
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

RAG/Agent原理架构
Ref: https://python.langchain.com/docs/modules/data_connection/document_loaders.html
LangChain经典架构图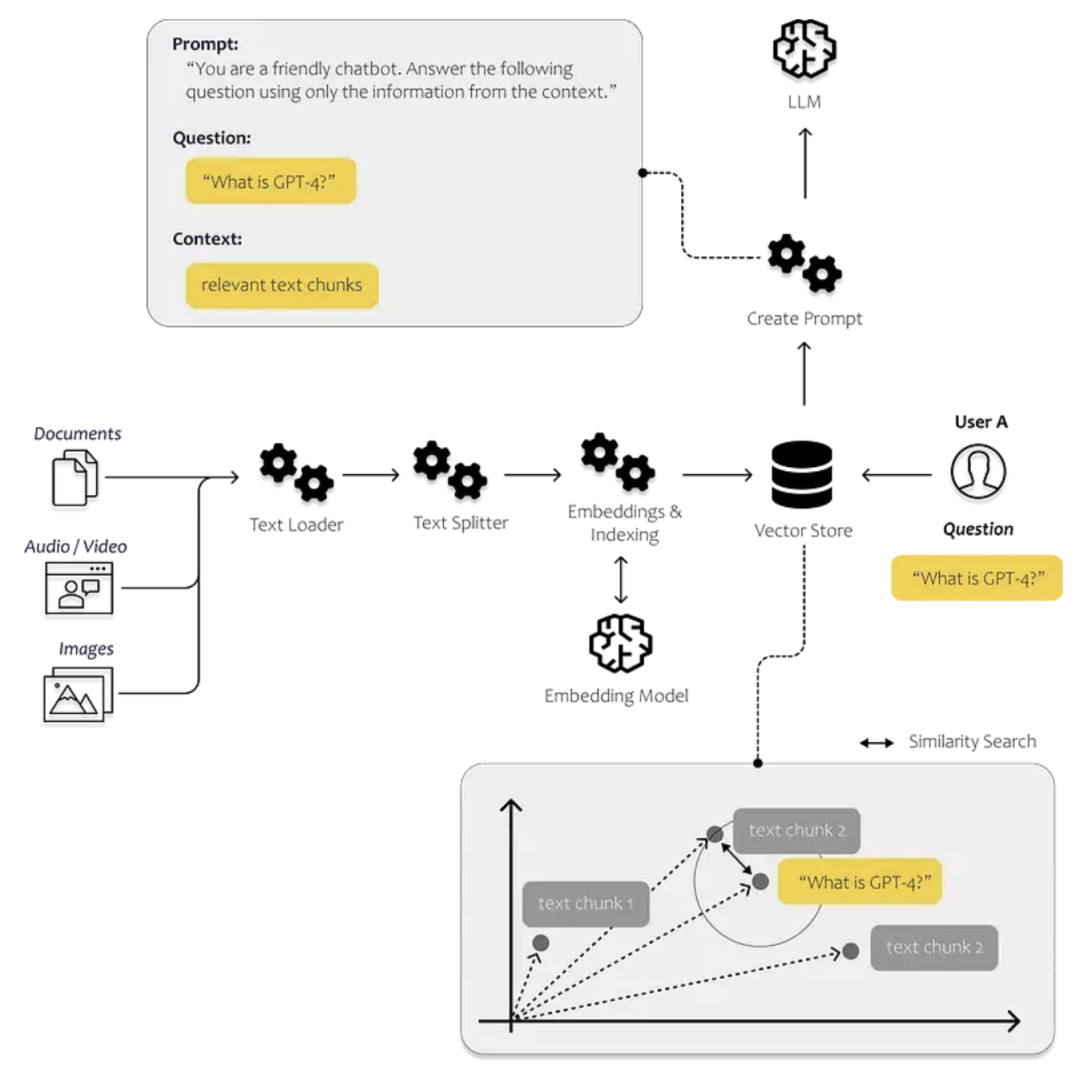
langchain框架中使用chunk_size(字符长度),voerlap(字符前后重叠长度)两个参数控制文档切分。Langchain最重要的模块:
-
模型(Models):各种模型类型的接口
-
提示(Prompts):提示管理、提示优化、提示序列化
-
索引(Indexes):文档加载器、文本拆分器、矢量存储 — 实现更快、更高效地访问数据
-
链(Chains):链超越了单个 LLM 调用,允许我们设置调用序列
通用RAG架构图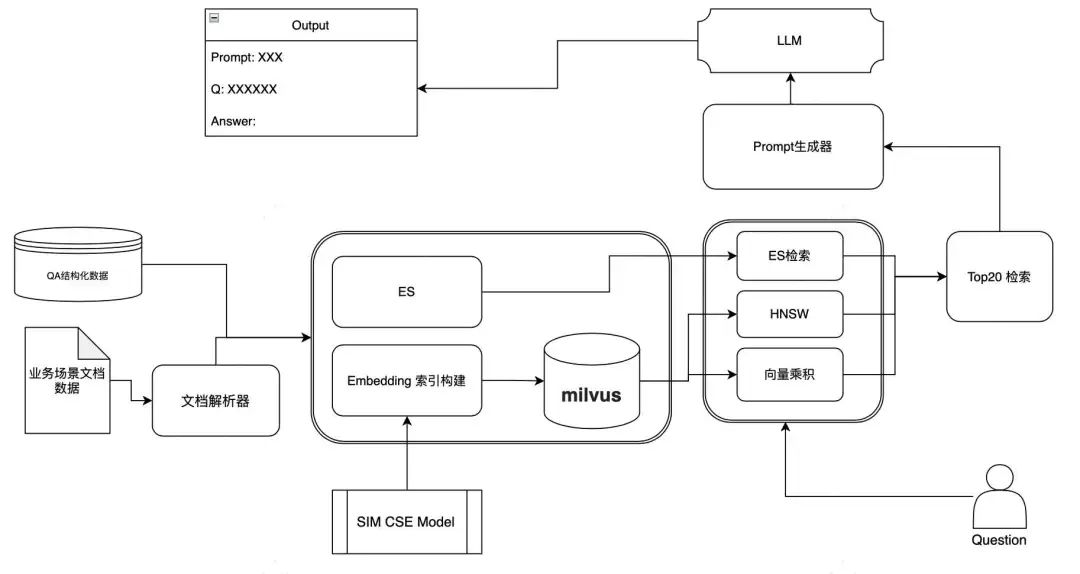
RAG系统由两个关键阶段组成:
-
检索:利用编码模型基于问题检索相关文档,如BM25、DPR、ColBERT和类似方法生成阶段;
-
生成:使用检索到的上下文作为条件,系统生成文本;
传统检索依赖类似于Lucene的倒排索引,而向量检索则依赖Faiss,HNSW,SCaNN这些向量检索库。
不同的RAG系统架构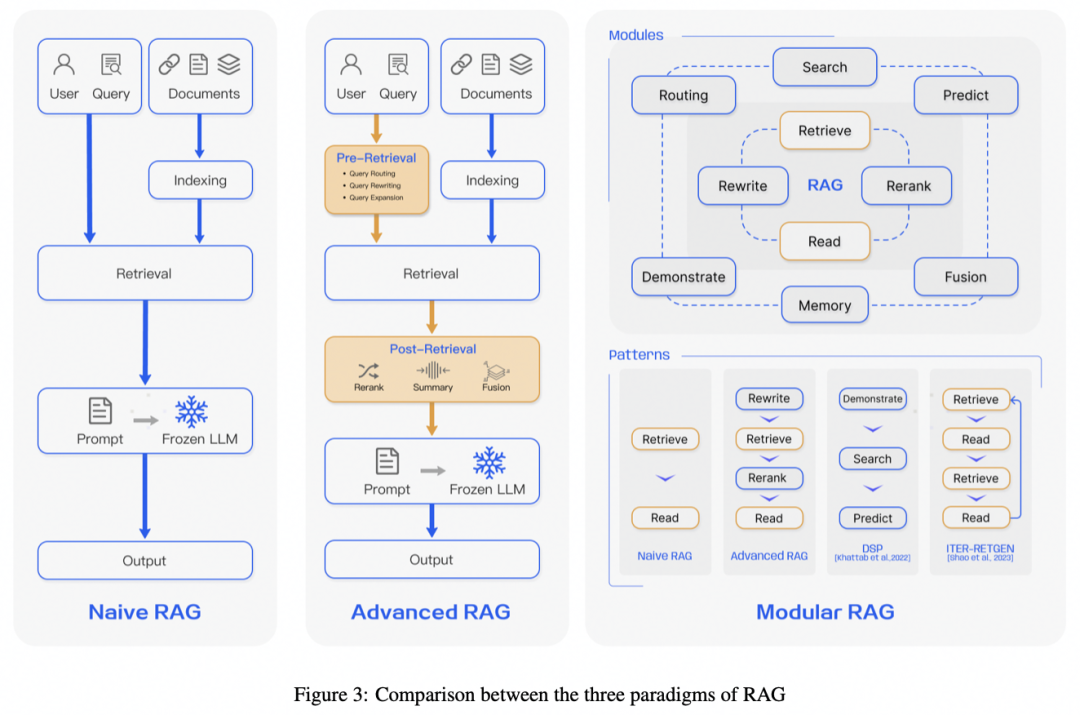
Naive RAG
Indexing
-
数据索引:清理和提取原始数据,统一文本格式;
-
Chunking:将加载的文本分成更小的块;
-
嵌入和创建索引:将文本编码为向量化;
Retrieve
- 计算问题嵌入和文档块在语料库中的嵌入之间的相似性。基于相似性水平,选择前K个文档块作为当前问题的增强上下文信息。
Generation
- 给定的问题和相关文档将合并到一个新的提示,利用LLM生成answer;
Advanced RAG
Advanced RAG在Naive基础上做了两点改进: 索引优化:通过滑动窗口、细粒度分割和元数据等方法优化了索引; 生成优化:结合了 pre-Retrieval 和 post-Retrieval 的方法。
Pre-Retrieval
-
数据优化:提高文本质量,如语义一致性,事实的准确性,上下文的丰富性和时间敏感性,以保证RAG系统的性能,策略如:规则过滤、补全、LLM重写或者扩充等;
-
指标结构优化:调整块的大小、更改索引路径和合并图结构信息来实现;
-
添加元数据信息:引入元数据,提高块检索效率;
-
路线优化:解决文档之间的一致性问题和差异。对齐概念包括引入假设问题,创建适合每个文档回答的问题,并用文档嵌入(或替换)这些问题;
-
混合检索:基于关键字的搜索、语义搜索和矢量搜索。
Embedding 优化
-
Fine-tuning Embedding:微调的目的是增强检索内容和查询之间的相关性。
-
Dynamic Embedding:动态嵌入根据单词出现的上下文进行调整,不同于为每个单词使用单个向量的静态嵌入,理想情况下,嵌入应该包含尽可能多的上下文,以确保“healthy”的结果。
Post-Retrieval
-
ReRank:重新排序以将最相关的信息重新定位到提示的边缘是一个简单的想法。
-
Prompt Compression:重点在于压缩不相关的上下文,突出关键段落,并减少整体上下文长度。
Agent技术四大核心
角色定义模块。Agent在此阶段需要和人类一样,对任务执行中的背景资料和具体要求保持关注,这一环节实质上是构建角色定位的数据集合。
尽管大模型在文本生成方面表现出色,但在处理多模态数据(如图像、视频等)时仍存在不足。未来的Agent需要处理多模态输入,而不仅仅是文本,这就要求Agent具备更强大的多模态理解和生成能力。
角色模板决定大语言模型回答的质量,因此角色模板需要反复打磨,以设计一个高质量的角色模板,对问题的解决效果可以达到事半功倍。
记忆模块。其功能是信息的存储与检索,分为短期记忆和长期记忆两种形式。短期记忆基本上等同于模型处理的即时上下文,长期记忆则通常来源于外部存储如向量数据库。
在记忆方面,Agent经常需要处理长序列输入和输出,如何优化上下文长度和结构以提高模型的性能和效率是一个重要挑战。而在Agent与大模型交互时,怎样保持任务的上下文连贯性也是一个问题。
规划模块。它仿照人类处理问题时将复杂问题拆分为多个小问题并逐一击破的策略,将复杂任务细化为更易于管理和解决的小任务或小目标。
在规划方面,当前的Agent系统严重依赖于大模型对复杂任务的拆解和工具选择的能力。大模型要能够理解任务、进行任务拆解,并正确调用工具来执行任务。这不仅仅是语言能力的问题,可能还需要针对性地提升模型在任务拆解方面的能力。
执行模块。它关乎AI Agent与其所处环境的直接互动。这可能涉及到使用应用程序接口、激活其他功能模块或实施具体操作,具体执行方式将依据任务的具体需求而定。简单来说,AI Agent要学会使用工具。
Agent主要解决特定场景的问题,如智能机器人、问答式交互、文档智能分类等,缺乏普适性的应用。而且大多数Agent仍处于“玩具”阶段,在工业、商业等实用化的复杂决策场景中的表现仍然不足。在复杂工具使用场景中,仅仅依靠prompt难以达到足够高的成功率,即使是GPT-4,在工具使用方面的正确率也只有60.8%。
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
RAG技术详解
RAG即 Retrieval Augmented Generation 的简称,是现阶段增强使用 LLM 的常见方式之一,其一般步骤为:
-
文档划分(Document Split)
-
向量嵌入(Embedding)
-
文档获取(Retrieve)
-
Prompt 工程(Prompt Engineering)
-
大模型问答(LLM)
文档划分(切片)
一般的切片原则上,需要保证切片后的文本的语义完整性,在长度许可的范围内,可以根据标点符号、段落结构信息进行切片,注意其中的表格信息等,可能会存在额外的处理方式
Embedding
向量模型可以将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。如使用 Openai 的 text-embedding-ada-002 向量化。
BGE向量模型
BGE是智源推出的Bert类通用类(中英文领域)语义向量模型,于2023年2月推出,Retrieval、Clustering、Pair Classification、Reranking、STS、Summarization、Classification等多个任务。
BGE简介
BGE是一个类BERT的模型,其性能也得益于RetroMAE的预训练方式,是一个三阶段的训练过程。
-
MTP数据集链接:https://data.baai.ac.cn/details/BAAI-MTP
-
BGE 模型链接:https://huggingface.co/BAAI
-
BGE 代码仓库:https://github.com/FlagOpen/FlagEmbedding
-
https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=1977141018&lang=zh_CN&scene=21#wechat_redirect
模型架构:RetroMAE的模型架构为非对称的encoder-decoder结构,encoder部分是由bert组成(12层transformer的encoder),而它的decoder部分仅有由一层transformer的decoder构成。
S1:Pre-Training
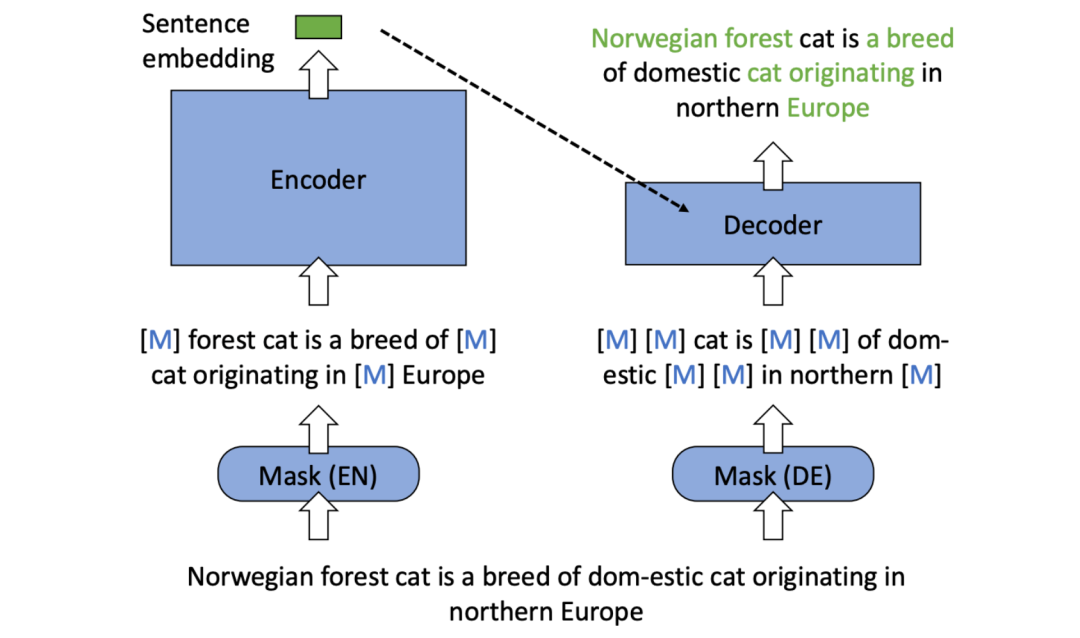
简单来说:使用纯文本的语料,目的是得到更强大的表征能力,采用RetroMAE的训练策略:先对text X进行随机Mask,然后进行encoding,再额外训练一个light-weight decoder(单层transformer,enhanced-decoder)进行重构。过程中,由于解码器过于简单,强迫Encoder学习到良好的embedding,在表征模型中提升效果显著。
enhanced-decoder: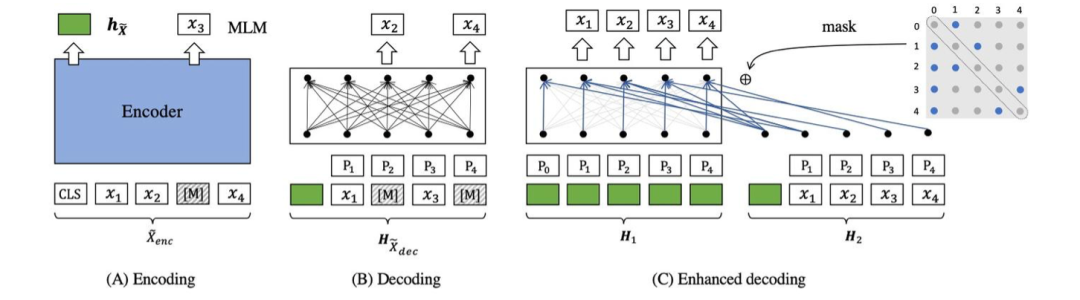
在encoder阶段,对被掩码的部分进行重构,也就是MLM(Masked Language Modeling),在decoder阶段对整个句子进行重构,整体Loss函数为:
S2:fintuning(unlabled data)
核心技术是对比学习:
-
采用in-batch negative sample方法;
-
使用大batch_size(论文使用的size为19200);(只要batch够大,在batch内就足以找到hard negative sample)
该阶段使用unlabled data进行训练,更准确的说采用的其实是伪标签,整理数据获得伪标签主要有2个步骤:
-
收集大量pair数据,如title-passage;
-
用text2vec-chinese计算文本的相似度,再卡阈值(paper中采用0.43作为阈值),过滤掉置信度比较低的pair;最后形成了100 million pairs这样庞大的数据集。
目标函数式对比学习方式(BCE):
其中p,q为文本对,是负样本;对比学习中,batch size越大,意味着在一个batch里面见到的负样本也就越多,这样模型学习得也就越准确,在BGE中,batch size为19200。
S3:特定任务上finetinue
BGE采用了指令微调的方式,指令微调允许模型在不同的任务需求上进行微调。微调数据集格式为[query,正样本集合,负样本集合]。微调在Embeding模型与Reranker模型采用同类型数据集,并将语义相关性任务视为二分类任务,采用BCE作为损失函数。
Fine-Tuning方法:
-
instruction-based fine-tuning:核心思路是将衡量sim(x1,x2),转化为衡量sim(instruction+x1,instruction+x2),这个instruction就是一段text prompt,用以说明domain、task等内容。例如在retrieval任务中,query侧加入的instruction为为这个句子生成表示以用于检索相关文章
-
hard negative sampling:在训练过程中,采取ANN-style sampling strategy
召回策略
RAG的召回架构主要分两步:召回和重排序,一般在召回阶段会使用ES进行关键词倒排召回结合向量相似检索的方式联合召回,然后对Top-K进行Reranker重排序。
常见的召回算法:
• BM25(又称 Keyword Search): BM25 的储存采用 ElasticSearch,即直接使用 ES 内置的 BM25 算法;
• Embedding Search: 使用 Embedding 模型将 query 和 corpus 进行文本嵌入,使用向量相似度进行文本匹配,可解决 BM25 算法的相似关键词召回效果差的问题,该过程一般会使用向量数据库(Vector Database);
• Ensemble Search: 融合 BM25 算法和 Embedding Search 的结果,使用 RFF 算法进行重排序,一般会比单独的召回算法效果好;
• Rerank: 上述的召回算法一般属于粗召回阶段,更看重性能;Rerank 是对粗召回阶段的结果,再与 query 进行文本匹配,属于 Rerank(又称为重排、精排)阶段,更看重效果;
Embedding Search
首先需要对 queries 和 corpus 进行文本嵌入,这里的 Embedding 模型使用 Openai 的 text-embedding-ada-002,向量维度为 1536,并将结果存入 numpy 数据结构中,保存为 npy 文件,方便后续加载和重复使用。
为了避免使用过重的向量数据集,本实验采用内存向量数据集: faiss。使用 faiss 加载向量,index 类型选用 IndexFlatIP,并进行向量相似度搜索。
Ensemble Search
Ensemble Search 融合 BM25 算法和 Embedding Search 算法,针对两种算法召回的 top_k 个文档,使用 RRF 算法进行重新排序,再获取 top_k 个文档。RRF 算法是经典且优秀的集成排序算法
RRF 算法:RRF本质上是将多路召回的结果按照排名映射到同一个值域空间,拉齐评分标准,作用类似机器学习里softmax函数。
score = 0.0
for q in queries:
if d in result(q):
score += 1.0 / ( k + rank( result(q), d ) )
return score
# where
# k is a ranking constant
# q is a query in the set of queries
# d is a document in the result set of q
# result(q) is the result set of q
# rank( result(q), d ) is d's rank within the result(q) starting from 1
Ensemble Search + Rerank
Ensemble Search 的基础上再进行效果优化,可考虑加入 Rerank 算法。常见的 Rerank 模型有 Cohere(API 调用),BGE-Rerank(开源模型)等。
node_postprocessors = [create_reranker_model(model_name=reranker, top_n=top_n)] if use_reranker else []
retriever = SimpleFusionRetriever(vector_index=index, top_k=top_k)
query_engine = RetrieverQueryEngine.from_args(
retriever=retriever,
text_qa_template=text_qa_template,
refine_template=refine_template,
node_postprocessors=node_postprocessors,
response_mode=response_mode, # https://docs.llamaindex.ai/en/stable/api_reference/response_synthesizers/
verbose=True,
streaming=True,
)
Reranker 模块可以直接是一个基于加权得分算法的统计方法,也可以是用深度学习模型训练得到端到端(提示和检索内容到得分)的模型。
-
统计方法:将多路召回的相识度按照一定的权重计算得分,这种方式的很明确,延迟影响也很小。
-
Cross-encoder Reranker: 深度学习模型神经网络可以很好的分析输入之间语义的相关性,并以得分的形式直接输出,这种方式一定程度上是直接基于语义理解得出的最相关性,具有“柔性”的优点,而且不受多路召回中内容原始相对位置的影响。 Reranker 性能评估
Reranker 的性能通常通过命中率和平均倒数排名这两个指标进行评估。
-
命中率(Hit Rate):检索到的文档中找到正确答案的查询所占的比例。
-
平均倒数排名(Mean Reciprocal Rank, MRR):所有查询中正确答案排名的倒数的平均值。如果第一个相关文档就是搜索结果的第一位,那么倒数就是 1;如果是第二位,倒数就是 1/2,以此类推。
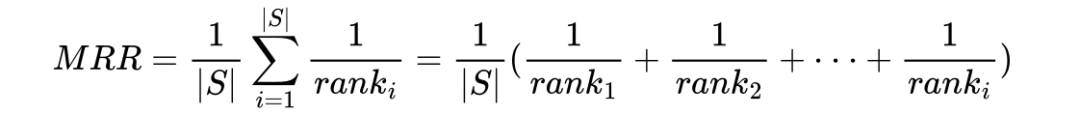 在LlamaIndex官方 Retrieve Evaluation 中,提供了对 Retrieve 算法的评估示例,具体细节可参考如下:https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
在LlamaIndex官方 Retrieve Evaluation 中,提供了对 Retrieve 算法的评估示例,具体细节可参考如下:https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
Reranker模型
reranker使用问题和文档作为输入,直接输出相似度而不是embedding。重排序器是基于交叉熵损失进行优化的,因此相关性得分不受特定范围的限制。数据格式和Embedding 一样,query,pos,neg,Hard Negative
常用Reanker模型:
-
CohereAI
-
bge-reranker-base
-
bge-reranker-large
参考:
- https://mp.weixin.qq.com/s?__biz=MzU1NjEwMTY0Mw==&mid=2247598215&idx=1&sn=cda9535559635cdef9707c70ab95ec5f&chksm=fa9f14c0a2ae7910342a2447fb8db9844832ae330b8a8162d738507385de2ea75f1938cb901a&scene=27
开源向量库选择
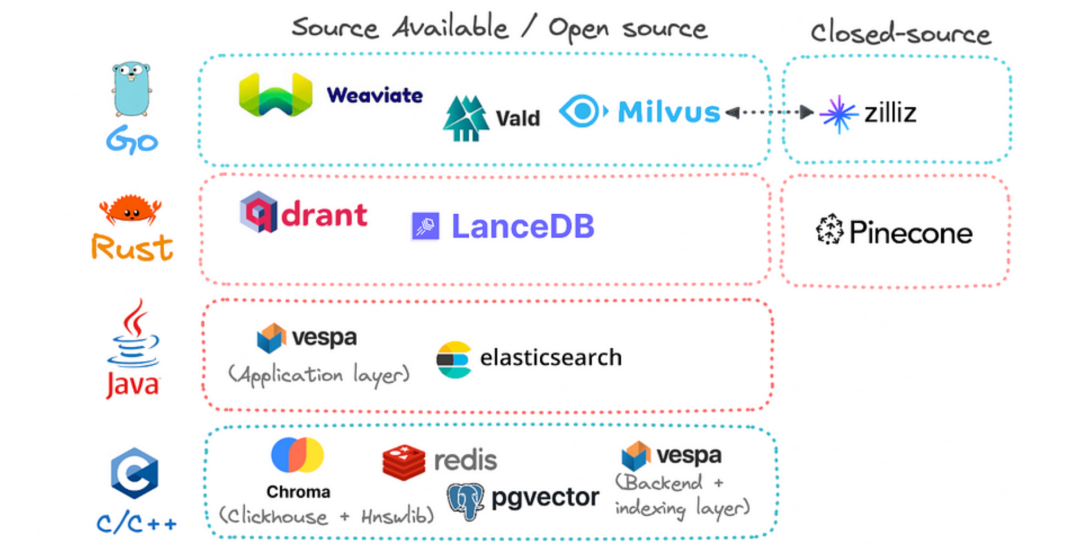
向量数据库的一个常见处理流程:
开源向量数据库
文本存入向量数据库的方式: 分词(Tokenization)-> 词形还原(Lemmatization)和词干提取(Stemming) -> 去除特殊字符和标点符号 -> 归一化(Normalization,大小写转换、数字标准化等)
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
向量化方法:
-
预训练的词嵌入模型(Word Embedding Models):如Word2Vec和GloVe,这些模型通过在大规模语料库上训练,生成每个词的稠密向量表示。这些向量能够捕捉词汇之间的语义关系,但由于它们是静态的,无法反映词汇在不同上下文中的意义变化。
-
上下文嵌入模型(Contextual Embedding Models):如BERT、GPT-3等,这些模型基于Transformer架构,能够根据上下文动态生成词汇的向量表示。相比于静态词嵌入模型,上下文嵌入模型更能准确捕捉文本的复杂语义关系。
-
句子嵌入模型(Sentence Embedding Models):如Sentence-BERT(SBERT),专门用于生成句子或段落级别的向量表示,适用于段落或文章的相似度计算和语义检索。
向量库使用:
-
https://blog.csdn.net/wjm1991/article/details/139665630
-
https://blog.csdn.net/qq_29929123/article/details/140884401
向量数据库检索优化
-
索引优化: (1)选择适当的索引结构:根据数据集的规模和特性选择合适的索引结构,例如HNSW;(2)调整索引参数:通过实验确定最优的层数和连接数,以达到理想的检索性能;(3)评估和调整:持续监控检索性能,并根据需求进行参数调整。
-
缓存机制: (1)确定缓存策略:决定哪些查询结果需要缓存,以及缓存的失效策略。(2)实现缓存机制:选择合适的缓存技术和框架来实现缓存功能。(3)维护缓存:持续监控缓存命中率和性能,适时调整缓存策略。
Ref:
-
https://blog.csdn.net/xxue345678/article/details/143358117
-
https://blog.51cto.com/u_16163510/12046932(向量库优化加速)
LLM生成
选择合适的LLM进行针对性的微调等等以适配下游任务,环节“幻觉”的策略
LlamaIndex构建RAG
LlamaIndex 是一个将大语言模型(Large Language Models,LLMs,后简称大模型)和外部数据连接在一起的工具。大模型依靠上下文学习(Context Learning)来推理知识,针对一个输入(或者是prompt),根据其输出结果。
LLamaIndex的任务是通过查询、检索的方式挖掘外部数据的信息,并将其传递给大模型,因此其主要由3部分组成:
-
1)数据连接:
-
2)索引构建: 要查询外部数据,就必须先构建可以查询的索引,llamaIndex将数据存储在Node中,并基于Node构建索引。索引类型包括向量索引、列表索引、树形索引等;
-
3)查询接口: 有了索引,就必须提供查询索引的接口。通过这些接口用户可以与不同的大模型进行对话,也能自定义需要的Prompt组合方式。查询接口会完成 检索+对话 的功能,即先基于索引进行检索,再将检索结果和之前的输入Prompt进行(自定义)组合形成新的扩充Prompt,对话大模型并拿到结果进行解析。
索引概念:
-
1)Node(节点):即一段文本(Chunk of Text),LlamaIndex读取文档(documents)对象,并将其解析/划分(parse/chunk)成 Node 节点对象,构建起索引。
-
2)Response Synthesis(回复合成):LlamaIndex 进行检索节点并响应回复合成,不同的模式有不同的响应模式(比如向量查询、树形查询就不同),合成不同的扩充Prompt。
索引方式:
-
1)List Index:Node顺序存储,可用关键字过滤Node
-
2)Vector Store Index:每个Node一个向量,查询的时候取top-k相似
-
3)Tree Index:树形Node,从树根向叶子查询,可单边查询,或者双边查询合并。
-
4)Keyword Table Index:每个Node有很多个Keywords链接,通过查Keyword能查询对应Node。
不同的索引方式决定了Query选择Node方式的不同。
回复合成方式包括:
-
1)创建并提纯(Create and Refine),即线性依次迭代;
-
2)树形总结(Tree Summarize):自底向上,两两合并,最终合并成一个回复。
class VectorStoreQueryMode(str, Enum):
"""Vector store query mode."""
DEFAULT = "default"# 使用余弦相似度来计算查询向量和索引向量之间的相似度。
SPARSE = "sparse"# 稀疏向量查询通常使用特定的模型(如TF-IDF、BM25、SPLADE等)生成稀疏向量
HYBRID = "hybrid"# 结合了文本和向量搜索的优势,能够在保证搜索速度的同时提高搜索的准确性。
TEXT_SEARCH = "text_search"
SEMANTIC_HYBRID = "semantic_hybrid"# 在HYBRID的基础上增加了语义分析,能够更好地理解查询的意图,提供更相关的搜索结果。
# fit learners
SVM = "svm"
LOGISTIC_REGRESSION = "logistic_regression"
LINEAR_REGRESSION = "linear_regression"
# maximum marginal relevance
MMR = "mmr"# (最大边际相关性搜索)是一种在向量存储中使用的查询模式,用于在检索过程中平衡相关性和多样性。
Retriever的配置方式:
- SimpleBM25Retriever:
SimpleHybridRetriever:
SimpleFusionRetriever:支持调用LLM对query进行改写,多次查询
融合逻辑:
-
最小-最大归一化:将每个检索器的得分归一化到一个共同的尺度上,通常在0到1之间。这是通过减去最小得分并除以得分范围(最大值 - 最小值)来完成的。
-
加权求和:归一化后,得分使用加权求和的方式组合成一个最终得分。
-
RECIPROCAL_RANK:应用倒数排名融合技术。
-
RELATIVE_SCORE:应用相对评分融合技术。
-
DIST_BASED_SCORE:应用基于距离的评分融合技术。
-
SIMPLE:简单地根据原始评分重新排序结果。
LlamaIndex 常用使用模版:
-
1)读取文档 (手动添加or通过Loader自动添加);
-
2)将文档解析为Nodes;
-
3)构建索引(从文档或从Nodes,如果从文档,则对应函数内部会完成第2步的Node解析)
-
4)[可选,进阶] 在其他索引上构建索引,即多级索引结构
-
5)查询索引并对话大模型
工具&代码
-
agent评测: ALFWorld、HotPotQA和HumanEval等,用于衡量AI Agent在决策制定、问题解答和编程等不同方面的表现。跨领域的综合测试:AgentBench等
-
文档处理: https://zhuanlan.zhihu.com/p/677254659
-
PyLMKit: https://zhuanlan.zhihu.com/p/670053040
推荐阅读:
-
https://blog.csdn.net/weixin_52185313/article/details/139890450
-
https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/135985279
前沿技术阅读材料(持续更新)
𓀀 [Paper]:Retrieval-augmented generation for large language models: A survey
Abstract: RAG综述
𓀀 [Paper]: RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
Abstract: 提出了一种新颖的指令微调框架RankRAG,该框架对单一LLM进行指令微调,以实现RAG中上下文排名和答案生成的双重目的。RankRAG 通过两阶段指令微调过程增强 LLM 的检索增强生成能力。第一阶段涉及在各种指令遵循数据集上进行监督微调。第二阶段统一了排序和生成任务,整合了上下文丰富的问答、检索增强型问答、上下文排序和检索增强型排序数据。
当前的RAG流程存在局限性:
1). 检索器的能力有限: Embedding模型的有限能力和对查询与文档的独立处理限制了对问题q和文档d之间文本相关性的估计,降低了其在新任务或新领域中的有效性。
2). 选择前k个上下文的权衡: 长上下文LLM可以将许多检索到的上下文作为生成答案的输入,但在实际应用中,随着k的增加,性能很快会达到饱和。对于长文档问答任务,最优的上下文块数k大约为10。而言,较小的k通常无法捕捉所有相关信息,从而降低了召回率,考虑到检索器的表达能力有限。相比之下,较大的k可以提高召回率,但代价是引入无关内容,这会妨碍LLM生成准确答案的能力。
Link: https://blog.csdn.net/yjw123456/article/details/142104671
𓀀 [Paper]: Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
Abstract: CoA(Chain-of-Action) 为一种新型的推理-检索机制:
1). 首先,使用上下文学习来提示LLM生成动作链,动作链包括子问题(Sub)、缺失标志(MF)和LLM生成的猜测答案(A)。
2). 然后,对动作链进行执行及监察操作,涉及检索相关信息、验证LLM生成的答案是否需要通过检索进行修正、检查是否需要用检索到的信息填补缺失的内容
3). 最后,由LLM对动作链进行精炼提取操作,生成最终答案。
𓀀 [Paper]: diaggpt: SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
Abstract: 提出一种新的self-RAG框架:在生成过程中引入一些特殊的token,来判断模型在回答query中要不要检索内容,判断检索内容是否相关,以及检索内容的支撑回答的程度怎样等问题,进而也就解决如下提及的问题: 1)如何保证检索内容是有效,或有用的? 2)如何验证检索的内容对输出的结果是支持的? 3)如何验证输出的结果是来自检索还是模型的生成?
self-RAG分三步:
-
第一步按需检索,当LLM生成时需要检索内容支撑时,就触发[Retrieve]token,表示接下来要用检索内容;
-
第二步利用prompt+检索内容进行并行生成,并在生成过程显示出对检索内容的相关度判断的token([Relevant],[Supported],[Irrelevent],[Partailly]);
-
第三步,对上步生成的内容进行评价筛选,选择一个最佳片段作为输出;重复上面的步骤,直至回答完;
核心就是生成模型M的训练,而M模型的不同之处在于,在生成文本序列的同时,还会辅助生成多种标签信息,以达到更细粒度的检索控制能力。
Link: https://zhuanlan.zhihu.com/p/674093669
𓀀 [Tool]: 业内大模型知识库rag框架
https://www.zhihu.com/question/652674711/answer/3579440529
𓀀 [Paper]: diaggpt: 基于大模型的多轮对话话题管理
Abstract: 基于大型语言模型(LLM)的Chatbot,旨在解决复杂诊断场景中任务导向对话的问题。
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
𓀀 [Paper]: Google.FRESHLLMS: Refreshing Large Language Models with Search Engine Aug
Abstract: 检索增强回答时变知识,新的Prompt格式
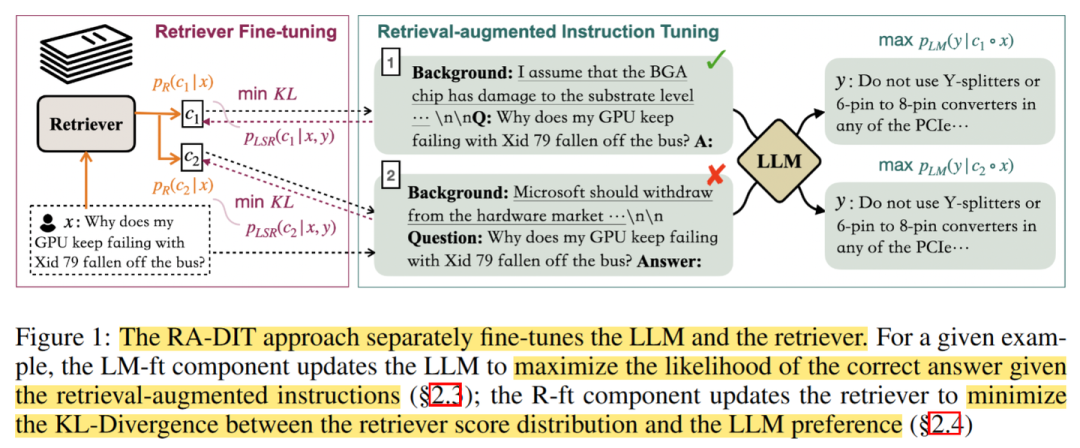
𓀀 [Paper]: Meta.RADIT: Retrieval-Augmented Dual Instruction Tuning
Abstract: LLM和检索器同时进行检索增强微调
𓀀 [Paper]: MS.Large Search Model: Redefining Search Stack in the Era of LLMs
Abstract: 端到端框架: 检索 重排 回答
𓀀 [Paper]: Merging Generated and Retrieved Knowledge for Open-Domain QA
Abstract: 检索与大模型知识融合
𓀀 [Paper]: Retrieve Anything To Augment Large Language Models
提出了LLM-Embedder,通过训练Embedding,来提升LLM在问答,tool检索,few shot,memory上的性能。
大模型的局限性:Knowledge boundary,Memory boundary,Capability boundary。解决上述问题的一种方法是Retrievers:Knowledge Retriever(提供额外的知识), Memory Retriever(检索上下文), Tool Retriever(选择工具),Example Retriever(in context learning)。
LLM-embedder改进的点: 1.Reward from LLM.利用LLM得到rewards。
2.Stabilized distillation: 同时利用reward-based labels(LLM打分)和ranked base labels()来提升蒸馏的效果。
3.Instruction based fine-tuning:为了减小不同数据源带来的影响,使用了指令微调的方法(在query前面加入了特定的instruction文本,方便区分不同的任务)。
4.Homogeneous in-batch negative sampling:使用了cross device batch negatives,另外异构数据会导致一个batch里面有不同的任务的数据,因此构造的mini-batch需要保证是来自同一个任务(论文说使用了regularization strategy来构造训练集保证in batch negatives的数据来自同一个任务)。
𓀀 [Paper]: Retrieval meets Long Context Large Language Models
Abstract: 长文本检索增强
𓀀 [Paper]: Self-Knowledge Guided Retrieval Augmentation for Large Language Models
Abstract: 知识融合: 整合内部知识和外部知识
𓀀 [Paper]: Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Abstract: 缓解RAG的噪声问题:第一种是额外设计了一个NLI模型对检索的信息做噪声识别,只把NLI判定筛选后的信息送给LLM做参考;第2种是在RAG的微调阶段,同时加入正向相关的检索结果以及不相关的噪声信息做sft微调,增强LLM识别噪声的能力。
𓀀 [Paper]: Exploring the Integration Strategies of Retriever and Large Language Models
Abstract: 知识融合方法
𓀀 [Paper]: Investigating the Factual Knowledge Boundary of Large Language Model with Retrieval
Abstract: LLM对事实知识边界的感知是不准确的,他们往往表现出过度自信的倾向。LLM不能充分利用它们所拥有的知识优势,而检索增强可以为LLM提供有益的知识补充。无论是先验判断还是后验判断,检索增强可用于增强LLM感知其事实认知边界的能力。当提供高质量的支持文件时,LLM表现出更好的性能和信心,并倾向于依靠提供的支持文件来产生响应。依赖程度和LLMs的信任取决于支持文件和问题之间的相关性。
𓀀 [Paper]: Active Retrieval Augmented Generation
Abstract: *改进检索生成范式: 核心思想就是主动判断需不需要进行检索,需要时再检索
检索增强的语言模型: 将用户的输入和检索到的相关文档一起送入语言模型来生成回答:
方法一: FLARE with Retrieval Instructions,通过prompt的方式让LLM来决定什么时候需要进行检索,比如当LLM生成“[Search(query)]”这样一个文本片段的时候就会执行检索操作。
方法二: Direct FLARE,通过instructions的方式可能不够可靠,直接法的主要思想是每次先往后生成一个临时的句子,然后看看这个句子里每个token的概率怎么样,概率如果都很高就认为模型比较有信心,不需要检索了。当需要检索的时候,就把概率低的token去掉,基于LLM生成一个相关的提问作为query用来检索
Link: https://zhuanlan.zhihu.com/p/654736924
𓀀 [Paper]: ALCE: Enabling Large Language Models to Generate Text with Citations
Abstract: 人工评估或商用搜索引擎,难以复现和比较不同模型,提出Automatic LLM Citation Evalutation 自动化评估模型检索生成能力。
ALCE评估模型,三方面评估:
1). 流畅度——MAUVE (Pillutla et al., 2021)
2). 正确性——根据数据集特点,定制了三种评估方式,主要使用了召回率,正确率
3). 引用质量——根据数据集特点,定制了三种评估方式,主要使用了召回率,正确率
检索生成方式:
1). vanilla:提供模型可能包含答案的文章,写提示词告诉他要正确地引用 2). summ/snippet: 不提供完整的文章而是概要版或某一段,为了减少信息损失,还结合了INTERACT,模型可以选择是否去看一个浓缩版对应的完整的文章 3). inlinesearch: 不提供检索结果,允许模型调用搜索 4). closebook:不提供外部文章,让模型闭卷给出答案。
𓀀 [Paper]: MSRA.Query2doc: Query Expansion with Large Language Models
Abstract: 文章思想:就是在开始检索之前,先用query让模型生成一次答案,然后把query和答案合并送给模型。
(1).字面检索: 因为模型的生成多半会很长,所以在相似度计算的过程中,会稀释,所以在拼接过程中,需要对原始query复制几份再来拼接,用公式来描述,就是这样,其中d‘是大模型生成的内容,n是复制的次数。
(2).向量检索: 向量召回的泛化能力是比较强的,直接拼接
𓀀 [Paper]: Large Language Models Know Your Contextual Search Intent: A Prompting Framework
Abstract: LLM4CS,其让LLMs作为基于文本的搜索意图解释器,以帮助会话型搜索。简单来说,LLM4CS采用了三个步骤来做这件事情:1)多轮问题重写:结合上下文将当前句子改写成语义完整的句子。2)回复生成:利用LLM生成回复,同时结合回复信息可以辅助提高检索效果。3)语义信息聚合:尝试了不同的语义信息聚合方法提升检索效果。在包括CAsT-19、CAsT-20和CAsT-21在内的三个广泛使用的会话型搜索基准上进行的广泛自动评估和人工评估,都展现出了显著的性能。
𓀀 [Paper]: In-context retrieval-augmented language models
Abstract: *提出一种In-Context RALM方法,其整体思路如下 图中Prefix可视为LLM解码出来的token片段,Retrieved Evidence是利用token片段检索出来的文本,将其拼在一起,形成新的prompt,然后解码下Suffix token片段,其中绿色标记代表从检索的文本中获取的信息。
图中Prefix可视为LLM解码出来的token片段,Retrieved Evidence是利用token片段检索出来的文本,将其拼在一起,形成新的prompt,然后解码下Suffix token片段,其中绿色标记代表从检索的文本中获取的信息。
LLM如何利用检索到的内容来输出的方法;
(1)直接放在prompt:这是一种比较简单的操作方式,将检索到与query相关的内容直接放在prompt中,当成一个背景知识交给大模型直接来输出;该方式简洁但结合方式过于粗糙,难以达到精控调节的目的。
(2)KNN+LLM:在推理中,将两个next_token 分布进行融合解码,一个分布来自LLM自身输出,一个是来自检索的top-k token,具体为利用LLM embedding方式在外挂知识库中查找与query token相似的token;该方式存在一个缺陷是需要额外构建一个向量库;
(3)自回归方式检索+解码:思路为先利用LLM解码出部分tokens,然后检索与该tokens相似的文本(文档),然后拼接在prompt中,进行next-tokens预测,这样自回归式的完成解码。该策略对比前两种,好处是能实现更细粒度的检索与融合,且不需要构建向量,或者涉及参数训练等额外工作;
Link: https://zhuanlan.zhihu.com/p/647112059
𓀀 [Paper]: REPLUG: retrieval-augmented black-box language models
Abstract: 之前的方法都是让lm来适应检索器,本文的方法是让检索器适应lm,即调整检索器检索文档的概率,来匹配lm输出ground truth的概率,lm输出ground true的概率越高,表示该被检索的文档,使lm的困惑越低,因此提高检索器检索该类文档的概率。
𓀀 [Paper]: One Embedder, Any Task: Instruction-Finetuned Text Embeddings
Abstract: 在文本向量化的方向上,一直以来的做法是,用领域和具体任务数据来训练对应的文本向量化模型来达到更好的效果,不同领域/任务的模型很难迁移或者说迁移效果不好,例如金融领域的模型就不能直接迁移到医疗领域,而在文本检索域可能更偏爱 DPR 模型,而 SimCSE 模型可能和文本对相似度任务更搭配。所以,总结目前文本向量化的方法,最佳实践是选择任务匹配的模型,使用领域任务对应的数据。而 INSTRUCTOR 方法的思路是,借鉴 Instruction Tuning 的思路,在进行文本向量化时,送入模型的不仅是待向量化处理的文本,还有对应领域和任务的指令性描述。以此实现同样的输入文本,在免训练的条件下,通过不同的指令性描述来生成对应领域和任务的向量化表示。
𓀀 [Paper]: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Abstract: https://blog.csdn.net/hubojing/article/details/136217782
𓀀 [Paper]: REALM: Retrieval-Augmented Language Model Pre-Training
Abstract: 预训练语言模型被证明能够捕获巨量的公共知识。然而,这些知识存储在参数中,有以下两个缺点:
-
这些知识是隐式的,使用时难以解释模型储存、使用的知识;
-
模型学习到的知识的量级和模型大小(参数量)相关,因此为了学习到更多的知识,需要扩充模型大小。
REALM在Open-QA的任务上fine-tune之后,显示了本文方法的有效性,有4~16%的提升。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 4087
4087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









