






C I F A R 系 列 CIFAR系列 CIFAR系列
官网:http://www.cs.toronto.edu/~kriz/cifar.html
链接:https://pan.baidu.com/s/1l1LZqs7n48OlGIciErcFWg
提取码:1234
一 CIFAR10
import pickle
import cv2
import numpy as np
import os
# 1.确定文件路径
file_data_batch_1 = './cifar10/data_batch_1'
file_data_batch_2 = './cifar10/data_batch_2'
file_data_batch_3 = './cifar10/data_batch_3'
file_data_batch_4 = './cifar10/data_batch_4'
file_data_batch_5 = './cifar10/data_batch_5'
file_batches_meta = './cifar10/batches.meta'
file_test_batch = './cifar10/test_batch'
# 2.将数据文件转为dict
def unpickle(file): # 该函数将cifar10提供的文件读取到python的数据结构(字典)中
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='iso-8859-1')
fo.close()
return dict
# 3.查看训练集
dict_train_batch1 = unpickle(file_data_batch_1) # 将data_batch文件读入到数据结构(字典)中
print("*********字典的4组键值对**************")
print(dict_train_batch1.keys()) # 字典里有4组键值对
print("*********dict_train_batch1**************")
print(dict_train_batch1) # 每个batch是一个字典
'''
训练集的dict有四组值:
1.batch_label:表示是第几个训练集
2.labels:每张训练图片对应的label,data每一行对应的标签(数字0-9),是个一维数组,10000个元素
3.data:训练集数据(数据在0-255之间),32*32图片的数值化数组,是一个10000*3072的numpy二维数组, 每一行代表一张图片,一行分3段(红r绿g蓝b色道),每段1024个元素
4.filenames:每张训练图片数据的名字(png格式), data每一行对应的文件名,同是一个一维数组,10000个元素
'''
print('---------------------data--------------------------')
data_train_batch1 = dict_train_batch1.get('data') # 字典中取data
print(data_train_batch1)
print(data_train_batch1.shape)
print('---------------------labels--------------------------')
labels = dict_train_batch1.get('labels') # 字典中取labels
print(labels)
print(len(labels))
print('-----------------------filenames------------------------')
filenames = dict_train_batch1.get('filenames') # 字典中取filenames
print(filenames)
print(len(filenames))
# 4.查看测试集
dict_test_batch = unpickle(file_test_batch)
print('------------------dict_test_batch-----------------------------')
print(dict_test_batch.keys())
# 5.查看Meta
dict_meta_batch = unpickle(file_batches_meta)
print('------------------dict_meta_batch-----------------------------')
print(dict_meta_batch)
# 6.npy转img
'''
1.npy转三通道img
2.img存到对应的label文件夹
'''
def makedir(path):
# 判断路径是否存在
isExists = os.path.exists(path)
if not isExists:
# 如果不存在,则创建目录(多层)
os.makedirs(path)
print('目录创建成功!')
# return True
# else:
# # 如果目录存在则不创建,并提示目录已存在
# # print('目录已存在!')
# return False
# 6.1 确定所有数据集的文件路径
file_data_batch_list = [file_data_batch_1,file_data_batch_2,file_data_batch_3,file_data_batch_4,file_data_batch_5,file_test_batch]
# 6.2 npy转三通道img,并将img存到对应的label文件夹
for i in range(6):
dict_train_batch = unpickle(file_data_batch_list[i])
data_train_batch = dict_train_batch.get('data') # 字典中取data
labels = dict_train_batch.get('labels') # 字典中取labels
for j in range(10000):
matrix = np.reshape(data_train_batch[j], (3, 32, 32))
matrix = matrix.transpose(1, 2, 0) # rgb --> bgr
label = labels[j]
makedir("./image/"+str(label)) # 创建保存图片的文件夹
cv2.imwrite("./image/"+str(label)+"/"+str(i)+"_"+str(j)+".png", matrix) # 保存图像
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000
randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
CIFAR10有6w张32*32的图片,一共有10个类别,每个类别6000张,5w张训练,1w张测试。
数据集实际被分为6batches,5份训练,1份测试,每份均为1w张。测试集的1w张,是随机从10个类别中分别抽取的1000张,类别完全均衡。5份训练集中,可能某份内,一个类别的数据比另一个类别少或多,但是整体5份里面各类数据的总和是5000份。
10个类别如下:

从官网下载的数据已经不是原始图片啦,而是经过数值化的numpy数组
数据读取
1.确定文件路径
file_data_batch_1 = '.\\major_dataset_repo\\cifar10\\data_batch_1'
file_data_batch_2 = '.\\major_dataset_repo\\cifar10\\data_batch_2'
file_data_batch_3 = '.\\major_dataset_repo\\cifar10\\data_batch_3'
file_data_batch_4 = '.\\major_dataset_repo\\cifar10\\data_batch_4'
file_data_batch_5 = '.\\major_dataset_repo\\cifar10\\data_batch_5'
file_batches_meta = '.\\major_dataset_repo\\cifar10\\batches.meta'
file_test_batch = '.\\major_dataset_repo\\cifar10\\test_batch'
2.将数据文件转为dict
def unpickle(file): # 该函数将cifar10提供的文件读取到python的数据结构(字典)中
import pickle
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='iso-8859-1')
fo.close()
return dict
3.查看训练集
dict_train_batch1 = unpickle(file_data_batch_1) # 将data_batch文件读入到数据结构(字典)中
print(dict_train_batch1.keys()) # 字典里有4组键值对
dict_keys([‘batch_label’, ‘labels’, ‘data’, ‘filenames’])
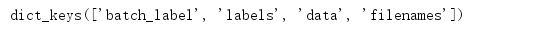
print(dict_train_batch1) # 每个batch是一个字典

训练集的dict有四组值
- batch_label:表示是第几个训练集
- labels:每张训练图片对应的label,data每一行对应的标签(数字0-9),是个一维数组,10000个元素
- data:训练集数据(数据在0-255之间),32*32图片的数值化数组,是一个
10000*3072的numpy二维数组, 每一行代表一张图片,一行分3段(红绿蓝色道),每段1024个元素 - filenames:每张训练图片数据的名字(png格式), data每一行对应的文件名,同是一个一维数组,10000个元素
print('-----------------------------------------------')
data_train_batch1 = dict_train_batch1.get('data') # 字典中取data
print(data_train_batch1)
print(data_train_batch1.shape)
print('-----------------------------------------------')
labels = dict_train_batch1.get('labels') # 字典中取labels
print(labels)
print(len(labels))
print('-----------------------------------------------')
filenames = dict_train_batch1.get('filenames') # 字典中取filenames
print(filenames)
print(len(filenames))
print('-----------------------------------------------')

查看测试集
dict_test_batch = unpickle(file_test_batch)
print(dict_test_batch.keys())
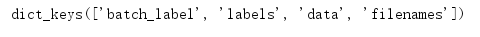
其他同训练集一样
查看Meta
dict_meta_batch = unpickle(file_batches_meta)
print(dict_meta_batch)
{‘num_cases_per_batch’: 10000, ‘label_names’: [‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’], ‘num_vis’: 3072}
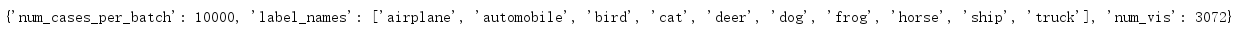
二 CTFAR100
从官网下载的数据已经不是原始图片啦,而是经过数值化的numpy数组
it has 100 classes containing 600 images each. There are 500 training images and 100 testing images per class.
The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a “fine” label (the class to which it belongs) and a “coarse” label (the superclass to which it belongs).
100个类别如下
| Superclass | Classes |
|---|---|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television |
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
1.确定文件路径
file_train = '.\\major_dataset_repo\\cifar100\\train'
file_test = '.\\major_dataset_repo\\cifar100\\test'
file_meta = '.\\major_dataset_repo\\cifar100\\meta'
2.将数据文件转为dict
def unpickle(file): # 该函数将cifar10提供的文件读取到python的数据结构(字典)中
import pickle
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='iso-8859-1')
fo.close()
return dict
3.查看训练集
dict_train = unpickle(file_train) # 将data_batch文件读入到数据结构(字典)中
print(dict_train.keys()) # 字典里有4组键值对
dict_keys([‘filenames’, ‘batch_label’, ‘fine_labels’, ‘coarse_labels’, ‘data’])
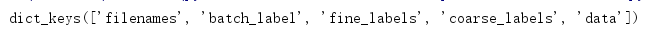
训练集的dict有四组值
- filenames:
- batch_label:
- fine_labels:
- coarse_labels:
- data:
print('-----------------------------------------------')
filenames = dict_train.get('filenames') # 字典中取filenames
print(filenames)
print('-----------------------------------------------')
batch_label = dict_train.get('batch_label') # 字典中取batch_label
print(batch_label)
print('-----------------------------------------------')
fine_labels = dict_train.get('fine_labels') # 字典中取fine_labels
print(fine_labels)
print(len(fine_labels))
print('-----------------------------------------------')
coarse_labels = dict_train.get('coarse_labels') # 字典中取coarse_labels
print(coarse_labels)
print(len(coarse_labels))
print('-----------------------------------------------')
data = dict_train.get('data') # 字典中取data
print(data)
print(data.shape)
print('-----------------------------------------------')

查看测试集
dict_test = unpickle(file_test)
print(dict_test.keys())

其他同训练集一样
查看Meta
dict_meta_batch = unpickle(file_batches_meta)
print(dict_meta_batch)
{
‘fine_label_names’:
[‘apple’, ‘aquarium_fish’, ‘baby’, ‘bear’, ‘beaver’, ‘bed’, ‘bee’, ‘beetle’, ‘bicycle’, ‘bottle’, ‘bowl’, ‘boy’, ‘bridge’, ‘bus’, ‘butterfly’, ‘camel’, ‘can’, ‘castle’, ‘caterpillar’, ‘cattle’, ‘chair’, ‘chimpanzee’, ‘clock’, ‘cloud’, ‘cockroach’, ‘couch’, ‘crab’, ‘crocodile’, ‘cup’, ‘dinosaur’, ‘dolphin’, ‘elephant’, ‘flatfish’, ‘forest’, ‘fox’, ‘girl’, ‘hamster’, ‘house’, ‘kangaroo’, ‘keyboard’, ‘lamp’, ‘lawn_mower’, ‘leopard’, ‘lion’, ‘lizard’, ‘lobster’, ‘man’, ‘maple_tree’, ‘motorcycle’, ‘mountain’, ‘mouse’, ‘mushroom’, ‘oak_tree’, ‘orange’, ‘orchid’, ‘otter’, ‘palm_tree’, ‘pear’, ‘pickup_truck’, ‘pine_tree’, ‘plain’, ‘plate’, ‘poppy’, ‘porcupine’, ‘possum’, ‘rabbit’, ‘raccoon’, ‘ray’, ‘road’, ‘rocket’, ‘rose’, ‘sea’, ‘seal’, ‘shark’, ‘shrew’, ‘skunk’, ‘skyscraper’, ‘snail’, ‘snake’, ‘spider’, ‘squirrel’, ‘streetcar’, ‘sunflower’, ‘sweet_pepper’, ‘table’, ‘tank’, ‘telephone’, ‘television’, ‘tiger’, ‘tractor’, ‘train’, ‘trout’, ‘tulip’, ‘turtle’, ‘wardrobe’, ‘whale’, ‘willow_tree’, ‘wolf’, ‘woman’, ‘worm’],
‘coarse_label_names’:
[‘aquatic_mammals’, ‘fish’, ‘flowers’, ‘food_containers’, ‘fruit_and_vegetables’, ‘household_electrical_devices’, ‘household_furniture’, ‘insects’, ‘large_carnivores’, ‘large_man-made_outdoor_things’, ‘large_natural_outdoor_scenes’, ‘large_omnivores_and_herbivores’, ‘medium_mammals’, ‘non-insect_invertebrates’, ‘people’, ‘reptiles’, ‘small_mammals’, ‘trees’, ‘vehicles_1’, ‘vehicles_2’]
}
c i f a r 10 : n p y 转 i m g cifar10:npy转img cifar10:npy转img
每个图片的npy根据label存到每个label文件夹中
- 1.npy转三通道img
- 2.img存到对应的label文件夹
import cv2
import numpy as np
1.确定文件路径
file_data_batch_1 = './cifar10/data_batch_1'
file_data_batch_2 = './cifar10/data_batch_2'
file_data_batch_3 = './cifar10/data_batch_3'
file_data_batch_4 = './cifar10/data_batch_4'
file_data_batch_5 = './cifar10/data_batch_5'
file_batches_meta = './cifar10/batches.meta'
file_test_batch = './cifar10/test_batch'
file_data_batch_list = [file_data_batch_1,file_data_batch_2,file_data_batch_3,file_data_batch_4,file_data_batch_5]
2.将数据文件转为dict
def unpickle(file): # 该函数将cifar10提供的文件读取到python的数据结构(字典)中
import pickle
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='iso-8859-1')
fo.close()
return dict
3.查看训练集
dict_train_batch1 = unpickle("./cifar10/data_batch_1") # 将data_batch文件读入到数据结构(字典)中
print(dict_train_batch1.keys()) # 字典里有4组键值对
data_train_batch1 = dict_train_batch1.get('data') # 字典中取data
#print(data_train_batch1)
print(data_train_batch1.shape)
print('-----------------------------------------------')
labels = dict_train_batch1.get('labels') # 字典中取labels
#print(labels)
print(len(labels))
print('-----------------------------------------------')
4.npy转三通道img
for i in range(5):
dict_train_batch = unpickle(file_data_batch_list[i])
data_train_batch = dict_train_batch.get('data') # 字典中取data
labels = dict_train_batch.get('labels') # 字典中取labels
for j in range(10000):
matrix = np.reshape(data_train_batch[j], (3, 32, 32))
matrix = matrix.transpose(1, 2, 0)
label = labels[j]
cv2.imwrite("./image/"+str(label)+"/"+str(i)+"_"+str(j)+".png", matrix)
测试
import cv2
import numpy as np
matrix = np.reshape(data_train_batch1[0], (3, 32, 32))
matrix = matrix.transpose(1, 2, 0)
cv2.imwrite("img_test_show.png", matrix)
img = cv2.imread("img_test_show.png")
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









