






Rasa NLU Chi 中的组件之间的数据流动
如果需要查看如何在ubuntu中使用pycharm调试rasa nlu chi可查看另一篇博文https://blog.csdn.net/qq_41475825/article/details/119646149?spm=1001.2014.3001.5501
一、pipline
language: "zh"
pipeline:
- name: "nlp_mitie"
model: "../data/total_word_feature_extractor_zh.dat"
- name: "tokenizer_jieba" #对应jieba_tokenizer
- name: "ner_mitie" #对应mitie_entity_extractor
- name: "ner_synonyms" #对应entity_synonyms,可去掉该组件,下面不对该组件进行讨论
- name: "intent_entity_featurizer_regex" #对应regesFeaturizer
- name: "intent_featurizer_mitie" #对应mitiefeaturizer
- name: "intent_classifier_sklearn" #对应sklearn_intent_classifier
整体流程:
假设用户输入数据:“我发烧了应该吃什么药?”,首先通过jieba_tokenizer得到tokens: [我,发烧,了,该,吃,什么药,?],然后mitie_entity_extractor基于token获得entity的信息(实体类型,位置),*接着entity_synonyms将实体替换成同义词(需要提前设置,这里不重要)得到新的tokens,*接着regesFeaturizer和mitiefeaturizer利用tokens分别采用不同的策略得到不同文本的语义向量text_feature(合并策略是直接将两个语义向量拼接),最后sklearn_intent_classifier利用语义向量text_feature得到各个意图的概率。
二、调试信息及说明
- 初始化
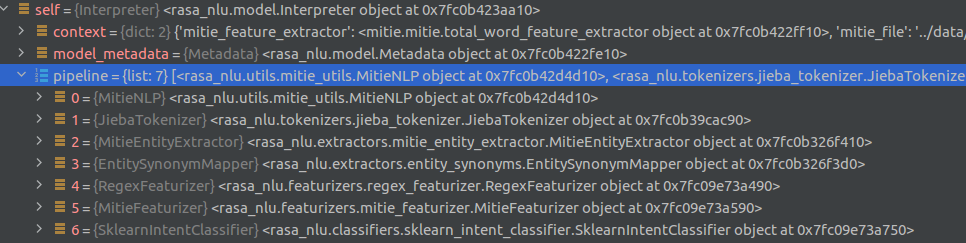
首先rasa nlu将在model.py中读取配置文件并且初始化pipline,每个组件按声明的顺序进行存放,如下图。
上述文本作为一个text传入rasa nlu,rasa nlu将其初始化一个Message对象,其中包括我们传入的文本信息“我发烧了该吃什么药?”(注意这个Message对象,每个组件都是从该Message中获取数据或者将输出添加到该Message对象中)

然后massage将作为参数依次传入每个组件。

- jieba_tokenizer分词。首先获取message.text:“我发烧了该吃什么药?”,将其分词成8个token:[我,发烧,了,该,吃,什么药,?],可以看到该message.data相比于初始message.data新增加了一个键值对(tokens:[]),如下图。

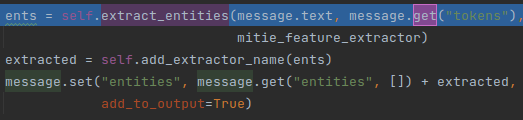
- mitie_entity_extractor实体提取。该组件必须处于Tokenizers后面,因为该组件需要用到Tokenizer组件的输出。
下列代码为该组件的核心逻辑,extractor_entities()是模型的接口,传入的参数包括原始文本,以及上一组件的输出“tokens”,mitie的词向量模型(用于将token转化为词向量)。ents为提取到的实体,json格式。
message.set()将该组件的输出的数据增添到message中。
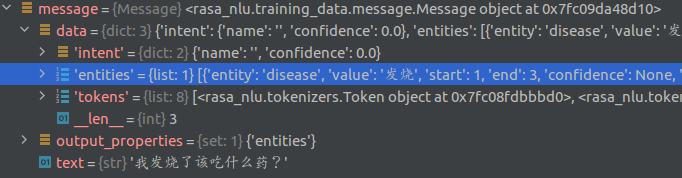
下面是mitie_entity_extractor的输出结果,在message中增添了entities。
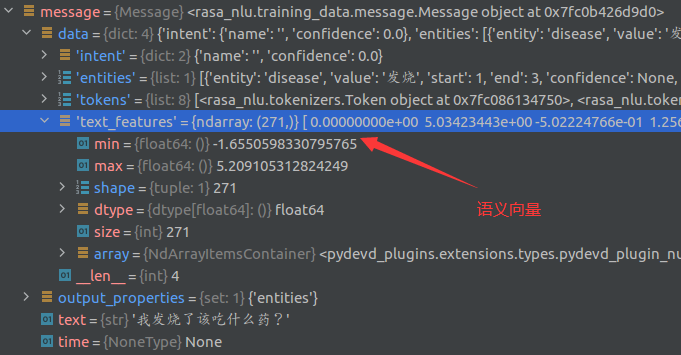
- mitieFeaturizer提取语义特征。下列代码中feature_for_tokens为获取模型的接口,传入的参数主要包括tokens和词向量模型,features为提取的特征向量。(intent_entity_featurizer_regex组件同intent_featurizer_mitie传入的参数和输出结果形式一直,只不过是提取特征的方式不同,不赘述)

经过特征提取后的可以看到message.data中多了text_features。
- sklearn_intent_classifier意图分类,首先获得语义特征向量,然后使用模型得到各个意图的概率(多分类问题),最后将模型的输出进行规范化输出即可。
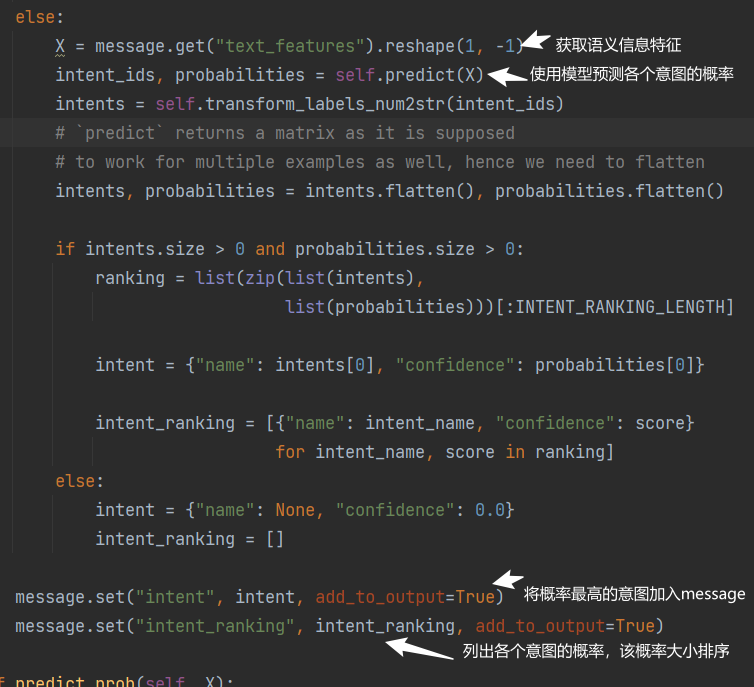
结果输出,可以看到message.data更新了intent和增加了intent_ranking。
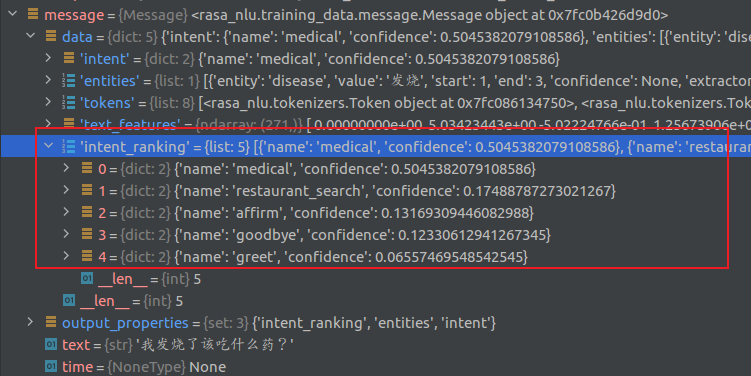
至此,nlu的主体流程结束。














 1275
1275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









