




 本文详细介绍了MPSOC中的ACP、HPC和HP三个接口,包括它们的性能特点、位置、使用注意事项以及在缓存一致性中的作用。并通过实测对比了三种接口的延迟、带宽和一致性维护成本。
本文详细介绍了MPSOC中的ACP、HPC和HP三个接口,包括它们的性能特点、位置、使用注意事项以及在缓存一致性中的作用。并通过实测对比了三种接口的延迟、带宽和一致性维护成本。
一文详解ACP、HPC和HP——MPSOC
写在前面:目前在网上关于ACP的文章几乎都是简单的介绍,并没有具体的说明如何使用。在本文中主要是围绕Cache一致性问题详细说明介绍AXI-ACP、AXI-HPC、AXI-HP的三个接口的性能和具体用法
一、ACP、HPC和HP是个啥?
这三个接口都是PS端的AXI从接口,都可以从PL端传输数据到PS端。可以看一下ug1085中官方的介绍:
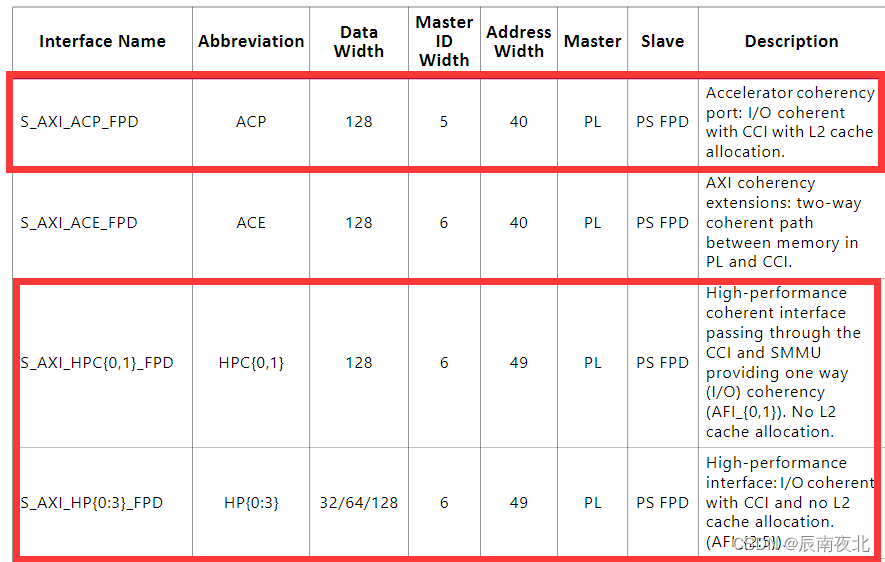
从文档中,可以看出这三种接口的区别,首先是数据的宽度,HP接口有32/64/128可选,其次是地址的宽度。再看后面的描述:
- ACP:加速一致性接口,通过CCI和L2的缓存分配,具有IO缓存一致性。
- HPC:高性能缓存一致性接口,直通CCI和SMMU,提供单向的缓存一致性,没有L2缓存分配
- HP:高性能接口,通过CCI实现缓存一致性,没有L2缓存分配。
看到这里,就会疑问,什么是CCI,什么叫one-way conherency?同时可以看到ACE支持 two-way conherency,这又是什么?为什么HPC叫高性能缓存一致性接口,而HP叫高性能接口?下面有解答。
二、三个接口在MPSOC中的位置
1)接口的位置
上面大致的了解了三个接口,那具体的情况是什么样的,可以看下面的这个图:(高清的图,可以去看UG1085手册P1095)
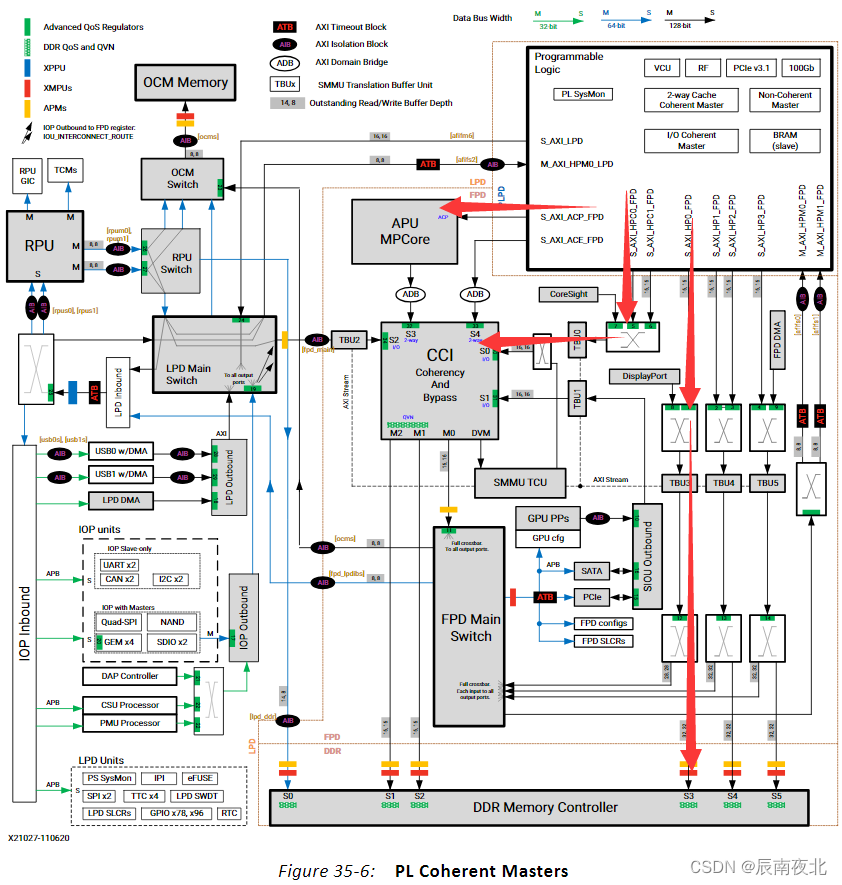
从上图可以看出这三个接口在整个SOC系统中所在的位置。
- ACP接口:直接是与APU核心连接的(具体连接到了哪里,可以看下面)。
- HPC接口:通过内部互联接口,最终与CCI的S0接口连接。
- HP接口:通过内部互联接口,最终与PS端的DDR控制器的S3接口连接。
2)MPSOC的内部缓存结构
那ACP接口具体连接到了CPU核心的哪里?可以看下面这个图:
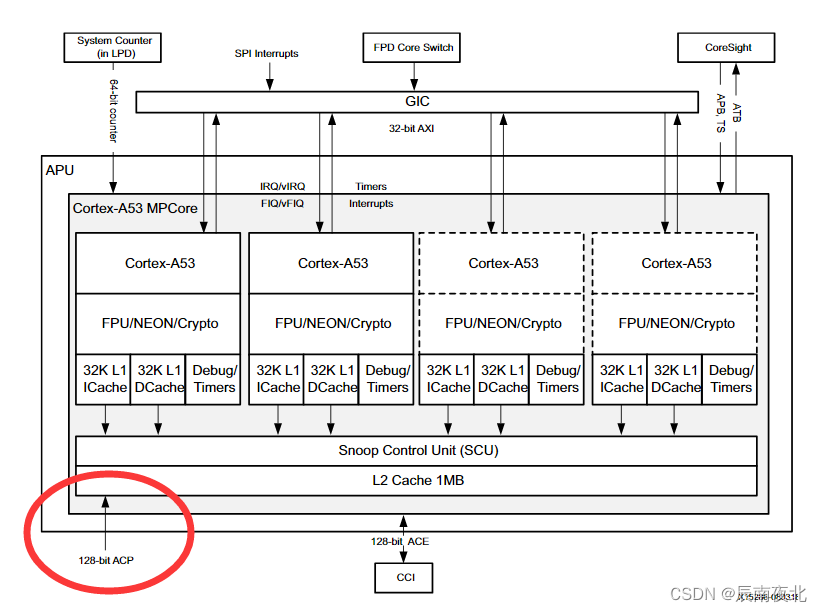
到这,也得了解一下MPSOC内部的缓存结构,图中可以看出,整个MPSOC一共有两级缓存,L1和L2。四核A53,各自拥有L1 ICache和DCache,大小都为32KB,而L2 Cache则是共享的,且不分指令和数据。而ACP接口则是直接连接在这个L2缓存上,如上图所示。
3)Cache的五种状态
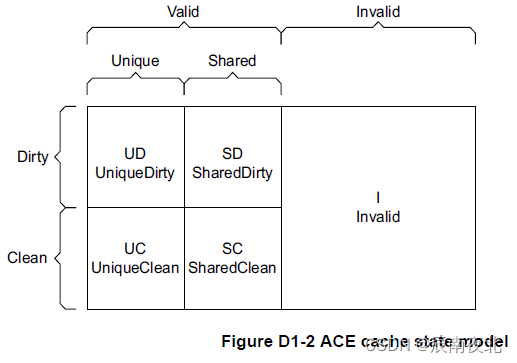
在继续往下讲之前,要了解一下Cache的五种状态,这也是保证缓存一致性的根本。
- Valid/Invalid:当有效的时候,表示缓存行是存在于缓存当中的
- Unique/Shared:如果是唯一的,则表示该缓存行仅存在于一个缓存中,共享时,表示存在于多个缓存中
- Clean/Dirty:如果是Clean,则表示缓存不必要去更新主内存,因为没有做过修改,如果是Dirty,则表示当前缓存已经相对主内存做了修改,之后需要及时更新到主内存中。
而在上一小节中的图里面,有一个Snoop Control Unit,该单元作用就是监听各个CPU中的L1 Dcache中的这些标志位,来维护Cache的这五种状态。同时还负责各个CPU之间的互联仲裁、通信、系统内存传输等。
4)何为CCI
在上面描述中或者图中,都有看到CCI,那什么是CCI,它的全名叫做Cache Coherent Interconnect,是一个缓存一致性互联模块。都是通过ACE接口进行互联。而在MPSOC中,使用的是ARM的CCI-400的硬核,该IP的总体框图如下:
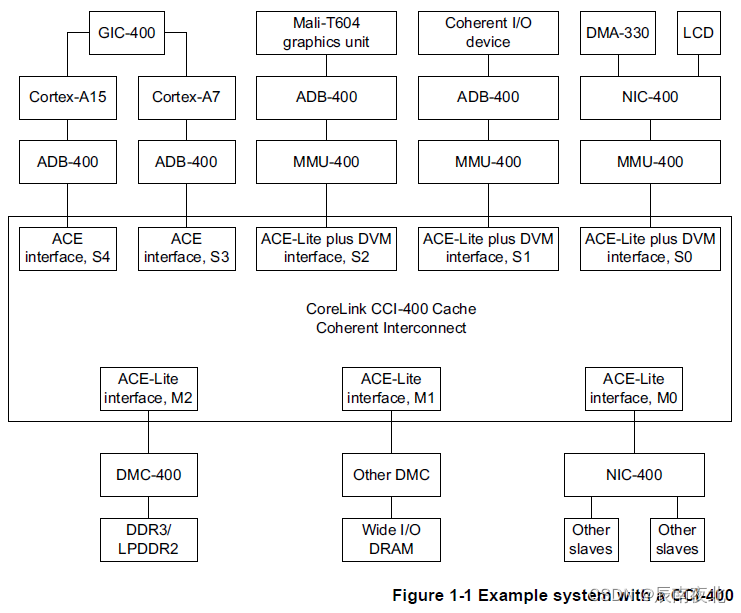
它是有5个ACE Slave接口,每个接口的功能又有差别,同时还有三个ACE Master接口。想具体了解,可以去看CCI-400的手册,同时还需要了解一下ACE接口。
5)one-way or two-way conherency
在最开始说到,HPC接口提供了单向的缓存一致性,ACE接口则提供了双向的缓存一致性。那这俩有什么区别呢?区别就在于:
-
one-way conherency:指的就是PL端这边是不存在Cache的,只是根据PS端的Cache来保证HPC端读写的数据和PS端Cache上的数据是一致的,
-
two-way conherency:指的是,在PL端的内部也可以实现一个Cache,然后通过ACE接口和CCI模块,来保证PS端内部的Cache和PL端内部的Cache具有一致性。具体可以看下面的这个框图:
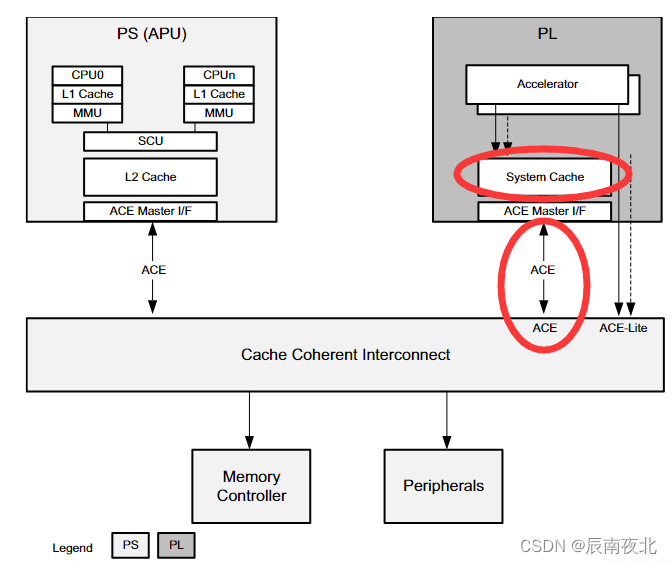
two-way conherency实现了PS端和PL端的Cache到Cache的访问,直接避开了PS端的DDR,加速了访问过程,同时减少了DDR的负载和带宽需求。
三、如何用这三个接口
经过上面的介绍,其实也大致了解到了,ACP接口和HPC接口,能够实现缓存一致性的传输。因为ACP是直接访问CPU的L2 Cache的,而HPC则是通过CCI的帮助下,来实现缓存一致性。但是HP接口则没有缓存一直性的功能。
1)ACP的使用注意事项
其实ACP的使用和HPC、HP的使用差不多是一样的,都是AXI的接口,但是有些细节则不一样,需要注意:
如果不满足,则AXI事务将会返回slave error错误
- 只支持INCR模式。
- 由于是直接访问L2Cache,所以每次传输的长度必须和CacheLine对齐。只支持64Byte和16Byte对齐传输,由于数据位宽固定是128bit,所以AxLEN只能是0x03或者0x00
- AxCACHE只能是0b0111,0b1011,0b1111。
- ACP的Outstanding能力最高只能是4(可以是读/写的任意组合),但是每个ID的Outstanding能力只能为1
2)HPC的使用注意事项
如果使用HPC接口的缓存一致性这个特性,需要:
- 使得AxCACHE[3:2]=2’b11.
- 同时需要使能CCI模块的S3端口的Snoop功能。
- 同时还需要将传输的Memory设置成Outer Shareable
(1)为什么需要这样设置?
-
关于CCI的寄存器
首先HPC接口并没有直接连接到CPU的缓存,而是通过CCI接口连接到CPU的缓存中,通过最上面的图可以知道,CCI是通过S3端口连接到CPU的。缺省设置下,CCI是不监听S3端口的传输的,也就是说CPU的Cache上有哪些地址的数据,数据是否被修改,CCI默认是不知道的,如果需要利用CCI的Cache的同步功能,需要开启CCI S3端口的监听功能。Snoop_Control_Register_S3寄存器的地址是0xFD6E4000,Snoop功能是该寄存器的最低位。(可以通过MPSOC的寄存器手册查看UG1087)如下图所示,可以看出默认该bit位是0。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwPhooFu-1692698856883)(C:\Users\11492\AppData\Roaming\Typora\typora-user-images\image-20230822144544220.png)]](https://i-blog.csdnimg.cn/blog_migrate/40c98faf20e8771c2a3e2fea2f8bafa6.png)
同时手册中在介绍ACP的时候也提到过(所以手册中的recommended还是一定要看的)。如下图:

当然Xilinx的Wiki也有提到:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-745MEEdr-1692698856883)(C:\Users\11492\AppData\Roaming\Typora\typora-user-images\image-20230822154659115.png)]](https://i-blog.csdnimg.cn/blog_migrate/e7433698485e1130b037d94cdf9f1e3c.png)
-
其次关于Outer Shareable
内存的cache属性包括non-shareable, inner shareable,outer shareable。inner shareable范围只包含A53 和L2 cache。缺省情况下,Inner Shareable的内存传输不会被广播给CCI。为了使能硬件同步cache,必须使Inner Shareable的内存传输也被广播给CCI或者将内存的属性配置为outer shareable。
(2)具体该如何设置?
-
配置CCI的寄存器
//可以在FSBL中配置,也可以在Application中配置。 //如果在FSBL中配置,需要在fsbl的main函数中的XFSBL_STAGE4下面去配置 unsigned int snoop_control=0; snoop_control = Xil_In32(0xFD6E4000); Xil_Out32(0xFD6E4000, snoop_control|0x1); snoop_control = Xil_In32(0xFD6E4000); -
配置Outer Shareable
由于上面提到,可以配置为,将Inner Shareable的内存传输也被广播给CCI,这个是在一篇博客中看到的,这个寄存器地址为0xFF41A040,而且需要在A53复位的时候进行配置,因此需要修改boot.bin文件,相对比较麻烦,而且在MPSOC的寄存器手册中我也没有看到这个寄存器,所以还是配置成Outer Shareable方便一点。
//直接将需要操作的地址配置成OUTER_SHAREABLE即可 Xil_SetTlbAttributes(USR_DMA_DST_ADDR,DEVICE_MEMORY|OUTER_SHAREABLE);
3)HP接口
HP接口就比较简单了,由于没有缓存一致性的特性,就正常使用就行。
四、三种接口的性能对比
1)关于ACP接口
该接口与紧密耦合的协处理器相比,ACP访问的延迟较长,就不太适用于细粒度的指令级加速。但是又因为每次的传输只有64byte或者16byte,与HPC相比,带宽较小,也不适合粗粒度加速(如视频帧级处理),但是比较适合中粒度事务的加速,比如视频块级别的处理等。
但是与HPC和HP接口相比,由于ACP直接连接到L2 Cache,因此,单次访问的延迟比较小。且不需要软件来维护Cache的一致性,能够提高整体的软件运行效率。
且从Xilinx的手册中可以得知,如果从功耗和性能的角度来说,要实现Cache I/O的一致性,使用HPC接口和ACE接口要比ACP接口会好一点。

2)关于HPC接口
通过以上正确配置之后,使用HPC接口实现Cache IO的一致性,能够减少软件维护Cache一致性的开销,且带宽够大。但是由于经过CCI模块,与HP接口相比,单次访问的延迟会比HP接口多几个CLK。
3)关于HP接口
由于HP接口没有Cache一致性的特性,因此需要软件上去维护Cache的一致性,也就是说,每次使用HP接口传输完之后或者之前(根据读或者写)都需要使用Xil_DCacheFlush()或者Xil_DCacheFlushRange,来更新缓存或者使缓存无效。单次访问的延迟要比HPC少几个CLK,但是需要软件去维护Cache一致性。
4)综合对比
-
从单次访问延迟来看:ACP<HP<HPC
实测数据:PL使用150Mhz时钟,对PS端进行写操作,Burst长度为4,数据位宽128bit
- ACP单次访问的延迟:大概为37个clk
- HPC单次访问的延迟:大概为50个clk
- HP单次访问的延迟:大概为46个clk
-
从传输带宽来看:HPC≈HP>ACP
-
从CPU维护Cache一致性的开销来看:HPC≈ACP<HP
五、实际测试验证
由于Xilinx自带DMA的AXI中的AxCache不可修改,因此如果需要测试,则需要自己写一个DMA模块,搭建block design如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HidQjKbG-1692698856883)(C:\Users\11492\AppData\Roaming\Typora\typora-user-images\image-20230822164708732.png)]](https://i-blog.csdnimg.cn/blog_migrate/3fd3509617eec81d7ea8d0e9efab542b.png)
自己写了一个user_dma模块,从PL传输数据到PS端,可以从PS端配置burst的长度、传输的目的地址、AWCache的值、AWprot的值、和起始数据(传输的数据是递增的)
-
usr dma配置接口时钟100M,数据流时钟为150M(一般控制和数据都是不同的时钟,方便之后使用,就直接采用不同的时钟来测试)
-
PS同时引出ACP、HPC和HP三种接口,通过访问地址来区分具体通过哪些端口访问PS。地址分配如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-00uoWP5O-1692698856884)(C:\Users\11492\AppData\Roaming\Typora\typora-user-images\image-20230822164918949.png)]](https://i-blog.csdnimg.cn/blog_migrate/ca1b361df23dfa46f0c6e7c8e84caab3.png)
可以看出,当访问0x00000000-0x1FFFFFFF时,使用的ACP接口,当访问0x20000000-0x3FFFFFFF时,使用的是HPC接口,当访问0x40000000-0x5FFFFFFF时,使用的是HP接口。
-
同时可以产生中断。
PS端的核心配置如下:
//以下是各个配置寄存器的地址
#define USR_DMA_BASE_ADDR 0x2000000000
#define USR_DMA_DST_ADDR_ADDR USR_DMA_BASE_ADDR
#define USR_DMA_INT_DATA_ADDR USR_DMA_BASE_ADDR + 0x04
#define USR_DMA_CACHE_ADDR USR_DMA_BASE_ADDR + 0x08
#define USR_DMA_ENABLE_ADDR USR_DMA_BASE_ADDR + 0x0C
#define USR_DMA_UPDATE_ADDR USR_DMA_ENABLE_ADDR + 0x04
#define USR_DMA_PROT_ADDR USR_DMA_UPDATE_ADDR + 0x04
#define USR_DMA_BURST_LEN_ADDR USR_DMA_PROT_ADDR + 0x04
//传输的目的地址
//0x00000000-0x1FFFFFFF ACP
//0x20000000-0x3FFFFFFF HPC
//0x40000000-0x5FFFFFFF HP
#define USR_DMA_DST_ADDR 0x20000000
//配置相关信息
Xil_Out32(USR_DMA_DST_ADDR_ADDR,USR_DMA_DST_ADDR); //配置目的地址
Xil_Out32(USR_DMA_INT_DATA_ADDR,0x00);//配置起始数据
Xil_Out32(USR_DMA_CACHE_ADDR,0x0F); //配置awcache信号
Xil_Out32(USR_DMA_PROT_ADDR,0x00);//配置awprot信号
Xil_Out32(USR_DMA_BURST_LEN_ADDR,0x04);//配置burst长度
Xil_Out32(USR_DMA_UPDATE_ADDR,0x01);//更新配置
Xil_Out32(USR_DMA_ENABLE_ADDR,0x01);//启动传输
1、测试ACP接口
-
单次延迟:可以看出从发送写地址到收到response的写回复中间有36个clk的延迟。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-En1kvCFT-1692698856884)(C:\Users\11492\AppData\Roaming\Typora\typora-user-images\image-20230822175239343.png)]](https://i-blog.csdnimg.cn/blog_migrate/1742074befd5766648f984d70c11ce50.png)
-
Cache一致性测试
- 测试流程:
- CPU对地址0x10000000地址进行写操作,CPU将该地址数据写为0x15,由于开启了Dcache,此时0x10000000的数据存在cache中
- 开启DMA传输,传输的起始数据为0x00。
- 在传输结束后的中断中,CPU查看0x10000000的数据,如果数据仍然为0x15,则说明传输的数据并未修改cache,如果数据为0x00,则说明已经将cache进行了修改。
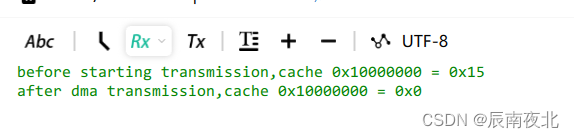
- 测试流程:
2、测试HPC接口
-
单次访问延迟:可以看出从发送写地址到收到response的写回复中间有48个clk的延迟。
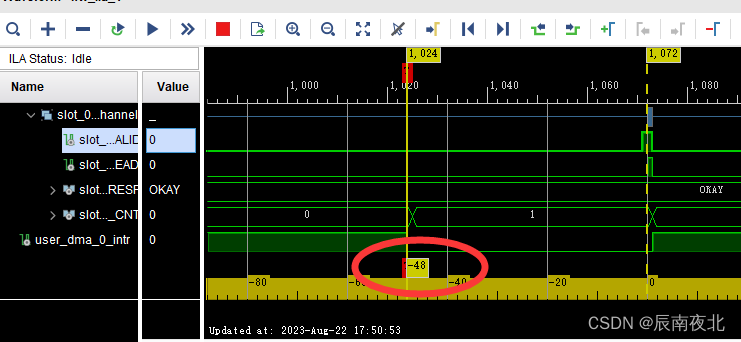
-
Cache一致性测试
-
不开启Cache特性(即不配置Outer Shareable和CCI的S3 Snoop寄存器)
-
CPU对地址0x20000000地址进行写操作,CPU将该地址数据写为0x15,由于开启了Dcache,此时0x20000000的数据存在cache中
-
开启DMA传输,传输的起始数据为0x00。
-
在传输结束后的中断中,CPU查看0x20000000的数据

可以看到,如果不做任何操作,此次传输并未改变Cache的数据。
实际上此次传输也没有改变DDR的数据,因为此时CPU的Cache上仍有0x20000000的数据,如果此时PL通过HPC(没有Cache一致性)来修改DDR中相应位置的数据,之后CPU还会将Cache上0x20000000的数据刷到DDR中。比如下图:

那如果不适用Cache一致性,在软件上如何修改?
-
CPU对地址0x20000000地址进行写操作,CPU将该地址数据写为0x15,由于开启了Dcache,此时0x20000000的数据存在cache中
-
等CPU操作完之后,使用
Xil_DCacheFlush将Cache中的存入内存。 -
开启DMA传输,传输的起始数据为0x00。
-
再使用
Xil_DCacheInvalidate操作将数据再更新到Cache中 -
在传输结束后的中断中,CPU查看0x20000000的数据

-
-
开启Cache特性
-
在FSBL中修改CCI的S3 Snoop寄存器
-
在App开始配置0x20000000为
OUTER_SHAREABLE -
CPU对地址0x20000000地址进行写操作,CPU将该地址数据写为0x15,由于开启了Dcache,此时0x20000000的数据存在cache中
-
开启DMA传输,传输的起始数据为0x00。
-
在传输结束后的中断中,CPU查看0x20000000的数据
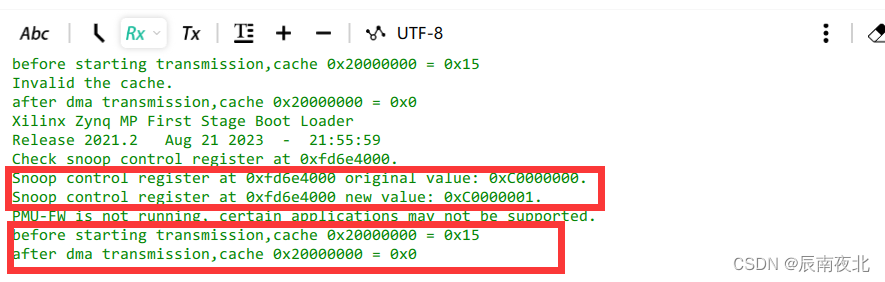
-
-
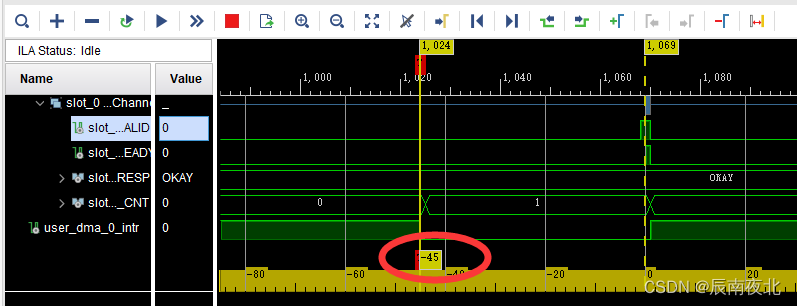
3、测试HP接口
- 单次访问延迟测试:可以看出从发送写地址到收到response的写回复中间有45个clk的延迟。
写在最后:如需引用请注明出处。总的测试工程已经上传至我的资源,可自行下载,如果需要积分,可以留言发送邮箱,使用的Vivado版本为2021.2。文中如果错误的地方,可以留言探讨交流。

















 14
14

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









