 Carla中相机传感器调用指南
Carla中相机传感器调用指南






Carla作为强大的自动驾驶仿真平台,而传感器模型是模拟自动驾驶车辆感知环境的核心组件。本章开始主要介绍Carla中支持的几种不同的传感器模型,并且去如何调用这些传感器模型。首先先介绍相机传感器模型。
Carla提供了多种相机传感器模型,包括RGB相机、深度相机、语义分割相机等。这些传感器可以模拟真实世界中的相机行为,生成高质量的图像数据。RGB相机捕获彩色图像,深度相机提供每个像素到相机的距离信息,语义分割相机为每个像素分配类别标签。
目录
1. RGB相机:
RGB相机模拟普通彩色摄像头,输出与真实世界一致的RGB图像。适用于场景可视化、目标检测等任务。
1.1 特性:
- 输出格式:BGRA 8-bit(默认包含Alpha通道)
- 可调整分辨率、视野角(FOV)、曝光等参数
1.2 代码示例:
camera_rgb_bp = blueprint_library.find('sensor.camera.rgb')
camera_rgb_bp.set_attribute('image_size_x', '800')
camera_rgb_bp.set_attribute('image_size_y', '600')
camera_rgb_transform = carla.Transform(carla.Location(x=1.5, z=2.4))
camera_rgb = world.spawn_actor(camera_rgb_bp, camera_rgb_transform, attach_to=vehicle)2. 深度相机:
深度相机输出每个像素的深度信息(距离相机的Z轴距离),以灰度或伪彩色形式呈现。
2.1 特性:
- 输出格式:Float32数组(需转换为可视化格式)
- 深度范围:0.0(近)到1.0(远)
2.2 代码示例:
# 创建深度相机
camera_depth_bp = blueprint_library.find('sensor.camera.depth')
camera_depth_bp.set_attribute('image_size_x', '800')
camera_depth_bp.set_attribute('image_size_y', '600')
camera_depth = world.spawn_actor(camera_depth_bp, camera_rgb_transform, attach_to=vehicle)3. 语义分割相机:
语义分割相机为每个像素分配类别标签(如车辆、道路、行人),用于场景理解任务。
3.1 特性:
- 输出格式:BGRA 8-bit(每个颜色通道对应不同类别)
- 提供预定义的12种物体类别标签
3.2 代码示例:
# 创建语义分割相机
camera_semseg_bp = blueprint_library.find('sensor.camera.semantic_segmentation')
camera_semseg_bp.set_attribute('image_size_x', '800')
camera_semseg_bp.set_attribute('image_size_y', '600')
camera_semseg = world.spawn_actor(camera_semseg_bp, camera_rgb_transform, attach_to=vehicle)
4. 对比分析:
4.1 完整代码:
import pygame
import numpy as np
import glob
import os
import sys
try:
sys.path.append(glob.glob('../carla/dist/carla-*%d.%d-%s.egg' % (
sys.version_info.major,
sys.version_info.minor,
'win-amd64' if os.name == 'nt' else 'linux-x86_64'))[0])
except IndexError:
pass
import carla
# 连接Carla服务器
client = carla.Client('localhost', 2000)
client.set_timeout(10.0)
world = client.get_world()
# 获取蓝图库
blueprint_library = world.get_blueprint_library()
# 创建车辆
vehicle_bp = blueprint_library.find('vehicle.tesla.model3')
spawn_point = world.get_map().get_spawn_points()[0]
vehicle = world.spawn_actor(vehicle_bp, spawn_point)
vehicle.apply_control(carla.VehicleControl(throttle=0.3, steer=0.6, brake=0.0, reverse=True))
# 创建RGB相机
camera_rgb_bp = blueprint_library.find('sensor.camera.rgb')
camera_rgb_bp.set_attribute('image_size_x', '800')
camera_rgb_bp.set_attribute('image_size_y', '600')
camera_rgb_transform = carla.Transform(carla.Location(x=1.5, z=2.4))
camera_rgb = world.spawn_actor(camera_rgb_bp, camera_rgb_transform, attach_to=vehicle)
# 创建深度相机
camera_depth_bp = blueprint_library.find('sensor.camera.depth')
camera_depth_bp.set_attribute('image_size_x', '800')
camera_depth_bp.set_attribute('image_size_y', '600')
camera_depth = world.spawn_actor(camera_depth_bp, camera_rgb_transform, attach_to=vehicle)
# 创建语义分割相机
camera_semseg_bp = blueprint_library.find('sensor.camera.semantic_segmentation')
camera_semseg_bp.set_attribute('image_size_x', '800')
camera_semseg_bp.set_attribute('image_size_y', '600')
camera_semseg = world.spawn_actor(camera_semseg_bp, camera_rgb_transform, attach_to=vehicle)
# 初始化Pygame显示
pygame.init()
display = pygame.display.set_mode((800, 600))
pygame.display.set_caption('Carla Camera Sensor')
# 处理相机数据回调
def process_image(image):
array = np.frombuffer(image.raw_data, dtype=np.dtype("uint8"))
array = np.reshape(array, (image.height, image.width, 4))
array = array[:, :, :3]
array = array[:, :, ::-1]
return array
# 转换深度数据为伪彩色
def process_depth(image):
depth_data = np.array(image.raw_data).reshape((image.height, image.width, 4))
depth_meters = depth_data[:, :, 0] * 1000 # 转换为米
image.save_to_disk('output/depth/%06d.png' % image.frame)
def process_segmentation(image):
image.convert(carla.ColorConverter.CityScapesPalette)
image.save_to_disk('output/seg/%06d.png' % image.frame)
# 设置相机数据回调
camera_rgb.listen(lambda image: display.blit(pygame.surfarray.make_surface(process_image(image)), (0, 0)))
#camera_depth.listen(lambda image: display.blit(pygame.surfarray.make_surface(process_image(image)), (0, 0)))
#camera_semseg.listen(lambda image: display.blit(pygame.surfarray.make_surface(process_image(image)), (0, 0)))
pygame.display.flip()
# 运行主循环
try:
while True:
pygame.event.pump()
pygame.display.flip()
finally:
camera_rgb.destroy()
camera_depth.destroy()
camera_semseg.destroy()
vehicle.destroy()
pygame.quit()
4.2 结果对比:
RGB相机的输出如下:
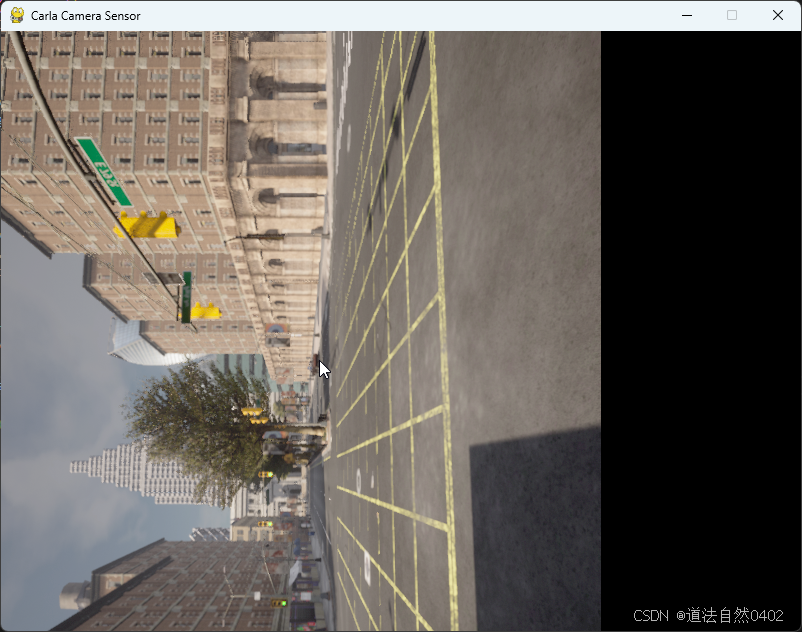
深度相机的输出如下:
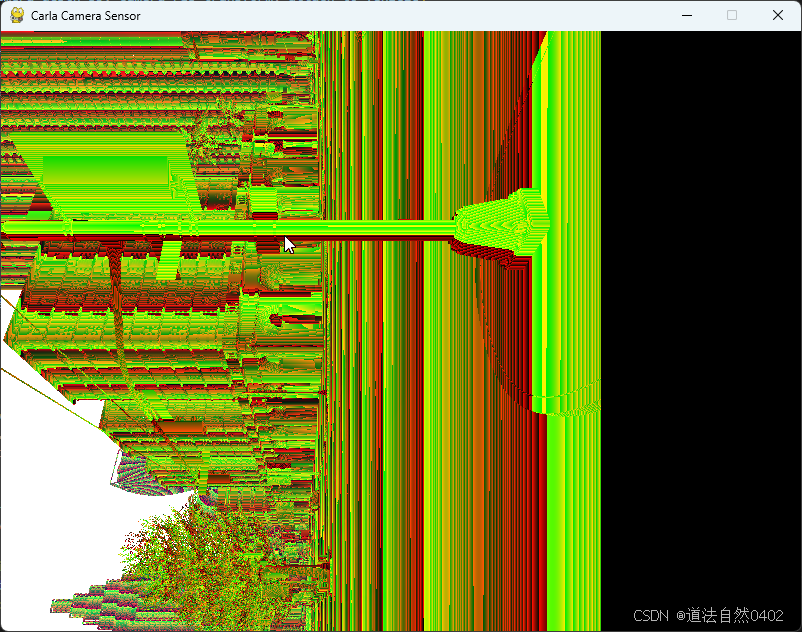
语义分割相机的输出如下:
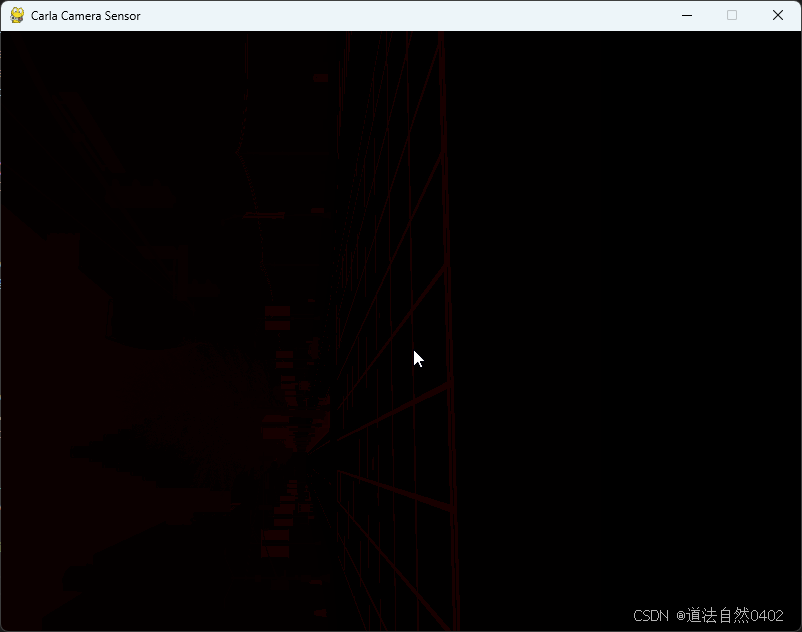
4.3 数据维度:
- RGB相机:3通道(BGR)或4通道(BGRA)
- 深度相机:1通道(实际存储为Float32)
- 语义相机:3通道(颜色编码的类别)
4.4 典型应用:
- RGB:人类可读的视觉分析
- 深度:距离测量、3D重建
- 语义:自动标注、场景理解
性能开销: 深度相机和语义相机的计算开销通常高于RGB相机,因涉及额外数据转换。
可视化差异: RGB图像可直接显示,深度和语义数据需后处理(如归一化、调色板映射)才能直观理解。



















 5879
5879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











