










论文:EyeCLIP: A visual–language foundation model for multi-modal ophthalmic image analysis
代码:https://github.com/Michi-3000/EyeCLIP
EyeCLIP和传统眼科视觉大模型有什么区别?
EyeCLIP突破了传统眼科视觉大模型的局限,通过多模态整合和视觉-语言联合学习,实现了更全面的眼科数据理解和更灵活的跨任务应用能力,从而更接近人类专家的诊断思维过程。
EyeCLIP与传统眼科视觉大模型相比有几个关键区别:
-
多模态整合:
EyeCLIP能够同时处理多种眼科检查模态(如CFP、OCT、FFA等11种模态),而传统模型通常只专注于单一或少数几种模态。这使得EyeCLIP能更全面地理解眼部健康状况。 -
视觉-语言联合学习:
EyeCLIP通过整合医疗报告文本,实现了视觉和语言的联合学习。这使得模型能够捕捉到更丰富的语义信息,而不仅仅局限于图像特征。 -
零样本/少样本能力:
得益于其视觉-语言预训练策略,EyeCLIP展现出了强大的零样本和少样本学习能力,特别是在罕见疾病诊断方面。传统模型通常需要大量标记数据才能在新任务上表现良好。 -
跨模态检索:
EyeCLIP能够执行图像到文本、文本到图像、图像到图像的跨模态检索任务,这是传统单模态模型所不具备的能力。 -
通用性与迁移能力:
EyeCLIP不仅限于眼科疾病诊断,还能应用于系统性疾病预测、视觉问答等多种下游任务,展现出更强的通用性和迁移能力。 -
长尾分布处理:
通过整合文本数据和多模态信息,EyeCLIP在处理长尾分布的罕见疾病方面表现出色,这是传统模型的一个常见弱点。 -
自监督学习策略:
EyeCLIP采用了结合重建学习和对比学习的创新自监督策略,能更好地利用未标记数据。
总的来说,EyeCLIP代表了向更全面、更智能的眼科AI系统迈进的一大步,能够更好地模拟人类专家的诊断过程,处理复杂的真实世界医疗场景。
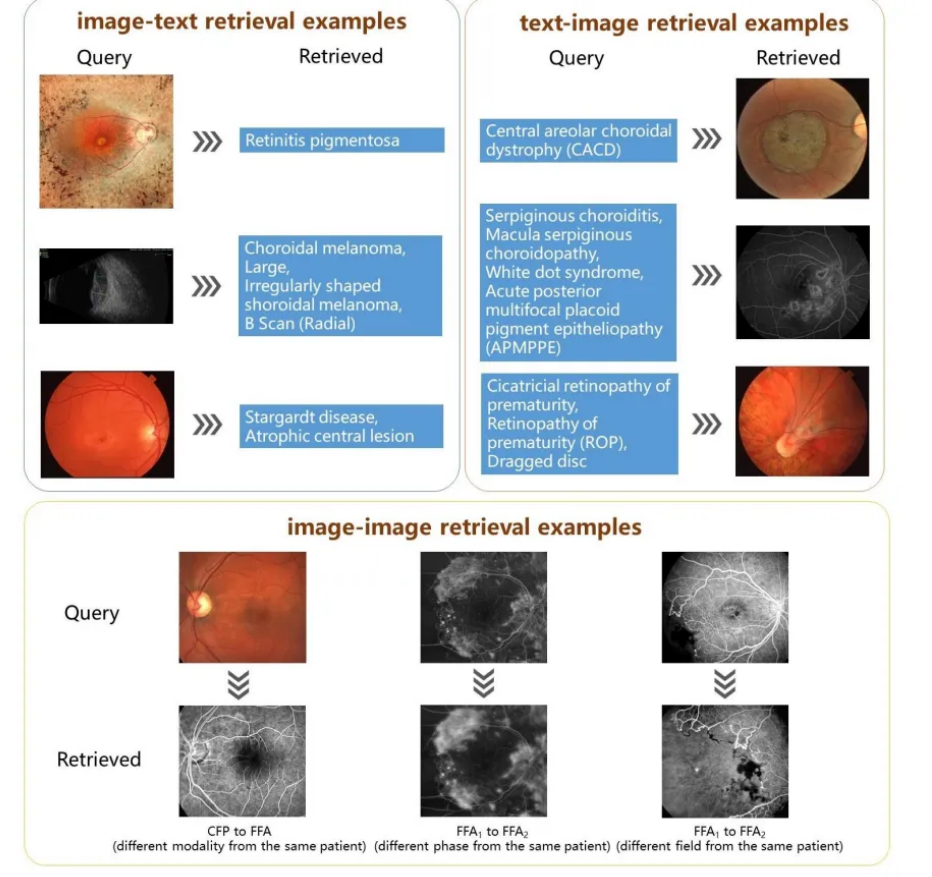
这张图展示了EyeCLIP模型在眼科领域进行跨模态检索的能力,分为三个部分:
-
图像到文本检索(image-text retrieval examples):
- 展示了如何从眼部图像检索相关的医学描述。例如,一张眼底图像被识别为"视网膜色素变性"(Retinitis pigmentosa)。
-
文本到图像检索(text-image retrieval examples):
- 展示了如何根据医学描述检索相关的眼部图像。例如,“中央局部脉络膜萎缩”(Central areolar choroidal dystrophy)这个描述成功检索到了相应的眼底图像。
-
图像到图像检索(image-image retrieval examples):
- 展示了如何从一种眼部检查图像检索到同一患者的另一种检查图像。例如:
- 从彩色眼底照相(CFP)检索到眼底荧光血管造影(FFA)图像
- 在同一种检查方法(FFA)下,检索不同时期的图像
- 在同一种检查方法(FFA)下,检索不同视野的图像
- 展示了如何从一种眼部检查图像检索到同一患者的另一种检查图像。例如:
这些例子展示了EyeCLIP模型在处理不同类型的眼科图像和相关医学描述时的灵活性和准确性。
模型能够在不同模态(如图像和文本)之间建立联系,并能识别同一患者在不同检查方法或时期下的相关图像。这种能力对于辅助眼科诊断和研究具有重要价值。
秒懂大纲
├── EyeCLIP【主题】
│ ├── 背景和问题【研究动机】
│ │ ├── 眼科疾病的早期检测至关重要【背景】
│ │ ├── AI基础模型在解决眼科挑战方面有潜力【技术潜力】
│ │ └── 现有眼科基础模型的局限性【问题】
│ │ ├── 主要聚焦单一模态【局限】
│ │ └── 缺乏多模态信息整合【局限】
│ │
│ ├── 方法【研究方法】
│ │ ├── 数据集【数据来源】
│ │ │ ├── 277万多模态眼科图像【图像数据】
│ │ │ └── 11180份文本报告【文本数据】
│ │ │
│ │ ├── 模型架构【技术细节】
│ │ │ ├── 基于CLIP框架【基础架构】
│ │ │ ├── 添加图像解码器【创新点】
│ │ │ └── 多任务学习策略【训练策略】
│ │ │ ├── 自监督重建【学习任务】
│ │ │ ├── 多模态图像对比学习【学习任务】
│ │ │ └── 图像-文本对比学习【学习任务】
│ │ │
│ │ └── 训练过程【实施细节】
│ │ ├── 图像预处理【数据准备】
│ │ ├── 学习率调整【训练技巧】
│ │ └── 硬件配置【资源需求】
│ │
│ ├── 结果【研究成果】
│ │ ├── 下游任务性能【评估指标】
│ │ │ ├── 眼科疾病诊断【应用】
│ │ │ ├── 系统性疾病预测【应用】
│ │ │ ├── 视觉问答【应用】
│ │ │ └── 跨模态检索【应用】
│ │ │
│ │ └── 与其他模型的比较【性能对比】
│ │ ├── CLIP【对比对象】
│ │ ├── BioMedCLIP【对比对象】
│ │ ├── PubMedCLIP【对比对象】
│ │ └── RETFound【对比对象】
│ │
│ └── 讨论【研究意义】
│ ├── EyeCLIP的优势【模型特点】
│ │ ├── 多模态对齐【优势】
│ │ └── 视觉-语言预训练整合【优势】
│ │
│ ├── 潜在应用【实际价值】
│ │ ├── 资源有限地区的早期诊断【应用场景】
│ │ └── 系统性疾病的早期检测【应用场景】
│ │
│ └── 局限性和未来方向【研究展望】
│ ├── 数据质量和多样性的影响【局限】
│ ├── 语言描述的标准化需求【改进方向】
│ └── 临床实践中的伦理考量【挑战】
提出背景
根据论文内容,我可以总结出EyeCLIP的研究背景、问题类别和具体问题如下:
- 研究背景:
├── 眼科疾病的重要性和挑战【背景】
│ ├── 早期检测对预防视力丧失至关重要【重要性】
│ └── 医疗资源不足,尤其在欠发达地区【挑战】
│
├── AI在眼科领域的应用前景【技术背景】
│ └── AI基础模型在解决眼科挑战方面显示出巨大潜力【潜力】
- 问题类别:
├── 眼科AI诊断模型的局限性【问题类别】
│ ├── 单一模态限制【具体问题】
│ │ └── 现有模型主要聚焦于单一图像模态【局限描述】
│ │
│ ├── 多模态信息整合不足【具体问题】
│ │ └── 缺乏有效利用多种检查方式提供的互补信息【局限描述】
│ │
│ └── 长尾分布问题【具体问题】
│ └── 标准的全监督或无监督学习方法难以处理罕见病例【局限描述】
- 具体问题:
├── EyeCLIP旨在解决的具体问题【解决方案】
│ ├── 多模态数据的有效利用【目标】
│ │ └── 整合多种眼科检查方式的信息【方法】
│ │
│ ├── 跨模态一致性【目标】
│ │ └── 建立不同检查模态之间的关联【方法】
│ │
│ ├── 长尾分布问题【目标】
│ │ └── 通过整合临床文本数据来捕获更广泛的疾病谱【方法】
│ │
│ └── 提高模型的通用性和适应性【目标】
│ └── 开发能够应用于多种下游任务的基础模型【方法】
EyeCLIP是为了解决现有眼科AI诊断模型在多模态数据整合、跨模态一致性和长尾分布处理方面的局限性,而提出的视觉-语言基础模型,旨在提高眼科疾病诊断的准确性、效率和适用范围。
解法拆解
-
目的:开发一个多模态眼科图像分析的视觉-语言基础模型,提高眼科疾病诊断的准确性、效率和适用范围。
-
问题:
- 现有眼科AI模型主要聚焦单一模态
- 缺乏多模态信息的有效整合
- 难以处理长尾分布的疾病数据
-
解法:开发EyeCLIP视觉-语言基础模型
子解法1(因为多模态数据整合需求):使用大规模多模态眼科数据集进行预训练
之所以用这个子解法,是因为眼科诊断需要整合多种检查方式的信息。
子解法2(因为跨模态一致性需求):设计多任务学习策略
之所以用这个子解法,是因为需要建立不同检查模态之间的关联。
子解法3(因为长尾分布问题):整合临床文本数据
之所以用这个子解法,是因为文本数据可以捕获更广泛的疾病谱。
子解法4(因为模型通用性需求):采用CLIP框架并进行改进
之所以用这个子解法,是因为CLIP框架具有良好的迁移学习能力。
例子:
在眼科疾病诊断中,医生通常需要综合分析多种检查结果(如眼底照片、OCT、FFA等)。
EyeCLIP模仿这一过程,通过整合多模态数据和文本信息,提高了模型对复杂眼科病例的理解和诊断能力。
- 这些子解法的逻辑链是一个网络结构,可以用以下决策树形式表示:
├── EyeCLIP视觉-语言基础模型【主要解法】
│ ├── 使用大规模多模态眼科数据集进行预训练【子解法1】
│ │ └── 整合277万多模态眼科图像和11180份文本报告【具体实施】
│ │
│ ├── 设计多任务学习策略【子解法2】
│ │ ├── 自监督重建【学习任务】
│ │ ├── 多模态图像对比学习【学习任务】
│ │ └── 图像-文本对比学习【学习任务】
│ │
│ ├── 整合临床文本数据【子解法3】
│ │ └── 使用层次化关键词提取算法处理医疗报告【具体实施】
│ │
│ └── 采用CLIP框架并进行改进【子解法4】
│ └── 添加图像解码器以实现自监督重建【具体改进】
- 分析隐性特征:
在EyeCLIP的解法中,存在一些隐性特征和中间步骤:
隐性特征1:多模态数据对齐
这个特征隐藏在子解法1和子解法2中。
EyeCLIP不仅使用了大规模多模态数据,还通过多任务学习策略实现了不同模态数据之间的对齐。
这是一个关键的隐性步骤,使得模型能够更好地理解和利用多模态信息。
隐性特征2:层次化语义学习
这个特征隐藏在子解法3中。
通过使用层次化关键词提取算法处理医疗报告,EyeCLIP实现了对复杂医学概念的层次化理解。
这种方法能够捕获疾病之间的层次关系,有助于处理长尾分布问题。
隐性特征3:自监督学习与迁移学习的结合
这个特征隐藏在子解法2和子解法4中。
EyeCLIP通过结合自监督重建任务和CLIP的迁移学习能力,实现了一种新的学习范式。
这种结合使得模型既能学习到数据的内在结构,又能很好地适应不同的下游任务。
这些隐性特征共同构成了EyeCLIP的核心创新,使其能够有效地处理多模态眼科数据,并在各种下游任务中表现出色。
创意视角
10个产生创意的思路:
- 组合:
- 将EyeCLIP与虚拟现实(VR)技术结合,创造一个沉浸式眼科诊断体验。
- 融合EyeCLIP和可穿戴设备技术,开发智能眼镜,实时分析用户的视觉健康状况。
- 拆开:
- 将EyeCLIP的功能模块化,允许用户根据需求选择性地使用某些功能。
- 拆分EyeCLIP的训练过程,允许医疗机构使用自己的数据集进行定制化微调。
- 转换:
- 将EyeCLIP从诊断工具转变为眼科教育平台。
- 转换EyeCLIP的应用领域,将其技术应用于其他需要精细图像分析的领域,如皮肤科或放射学。
- 借用:
- 从社交媒体算法中借鉴个性化推荐技术,优化EyeCLIP的诊断路径。
- 借用自然语言处理中的情感分析技术,使EyeCLIP能解读医生报告中的语气和紧迫性。
- 联想:
- 联想到蜜蜂的复眼结构,开发"复眼EyeCLIP"系统。
- 联想到人体免疫系统,开发一个能自我更新和适应新疾病模式的EyeCLIP版本。
- 反向思考:
- 设计一个"反向EyeCLIP",不是诊断疾病,而是预测健康眼睛未来可能出现的问题。
- 开发一个EyeCLIP版本,专门识别和分析正常健康的眼睛,以更好地理解正常变异范围。
- 问题:
- 深入探讨"为什么EyeCLIP可能会误诊?",开发一个错误分析和自我纠正模块。
- 思考"如何让患者更好地理解EyeCLIP的诊断结果?",开发一个患者友好的解释界面。
- 错误:
- 分析EyeCLIP的错误诊断案例,开发一个"错误学习"模块,持续改进模型性能。
- 创建一个"诊断挑战模式",故意加入错误或难以诊断的案例,以训练医生和改进算法。
- 感情:
- 为EyeCLIP添加情感识别功能,分析患者在诊断过程中的情绪反应。
- 开发一个"同理心模块",使EyeCLIP能根据患者的情绪状态调整其输出的语言和内容。
- 模仿:
- 模仿人类医生的诊断思维过程,开发一个"思维链"版本的EyeCLIP,展示其推理过程。
- 模仿自然界中的进化过程,创建一个能够通过"基因算法"不断优化自身的EyeCLIP版本。
9个量产创意的方法:
- 联想:
- 将EyeCLIP与天气预报系统联系,开发一个预测季节性眼病爆发的模型。
- 联想到图书馆索引系统,创建一个眼科图像和病例的智能检索系统。
- 最渴望联结:
- 将EyeCLIP与个人健康追踪app结合,满足用户对全面健康监测的渴望。
- 将EyeCLIP诊断结果与虚拟化妆app结合,满足用户对美丽与健康并重的渴望。
- 空隙填补:
- 开发EyeCLIP的移动版本,填补偏远地区缺乏眼科专家的空缺。
- 创建EyeCLIP的儿童友好版本,解决儿童眼科检查困难的问题。
- 再定义:
- 将EyeCLIP重新定义为一个个人视力健康管理助手,而不仅仅是诊断工具。
- 重新定义EyeCLIP为一个跨学科研究平台,连接眼科学与其他医学领域。
- 软化:
- 开发一个游戏化版本的EyeCLIP,让日常视力检查变得有趣和轻松。
- 创建一个"眼睛艺术家"模式,将诊断图像转化为艺术作品,减轻患者的焦虑。
- 附身:
- 以著名艺术家的视角重新设计EyeCLIP的用户界面,提升用户体验。
- 模仿侦探的思维方式,开发一个"眼睛侦探"模式,引导用户发现自己眼睛的独特之处。
- 配角:
- 强化EyeCLIP的数据管理功能,使其成为眼科诊所的全面管理系统。
- 开发一个辅助模块,帮助验光师更精确地配置眼镜。
- 刻意:
- 开发一个"极限测试"版本,故意使用最困难和罕见的病例来挑战和改进EyeCLIP。
- 创建一个"未来眼睛"模拟器,夸张地展示不同生活习惯对未来视力的潜在影响。
- 使用视角:
- 从患者的角度重新设计EyeCLIP的输出,使诊断结果更容易理解和接受。
- 开发一个"医生视角"模式,帮助新医生理解资深专家如何解读EyeCLIP的结果。
中文意译
青光眼、黄斑变性和糖尿病性视网膜病变等眼部疾病的早期发现对于防止视力丧失至关重要。
尽管人工智能基础模型在应对这些挑战方面展现出巨大潜力,但目前的眼科基础模型主要集中在单一模态上,而眼部疾病的诊断却需要多种模态。
一个关键但常被忽视的方面是如何利用同一患者在不同模态下的多角度信息。
另外,由于眼科疾病呈长尾分布的特性,传统的全监督或无监督学习方法往往难以应对。
因此,整合临床文本以涵盖更广泛的疾病谱变得尤为重要。
我们提出了 EyeCLIP ,这是一个利用超过 277 万张多模态眼科图像和部分文本数据开发的视觉-语言基础模型。
为了充分利用大规模的多模态标记和未标记数据,我们引入了一种新的预训练策略。
这种策略结合了自监督重建、多模态图像对比学习和图像-文本对比学习,旨在学习多种模态的共享表示。
通过 14 个基准数据集的评估, EyeCLIP 展现出了在广泛的眼部和全身疾病相关任务中的应用能力,在疾病分类、视觉问答和跨模态检索等方面达到了最先进水平。
EyeCLIP 相比先前的方法有了显著进步,尤其在现实世界的长尾场景中,展示出了少样本甚至零样本的能力,这一点尤为引人注目。
青光眼、黄斑变性和糖尿病性视网膜病变等眼科疾病严重威胁着全球视力健康,常常导致视力受损甚至失明。
然而,由于医疗资源不足,特别是在医疗服务欠发达地区和发展中国家,及时诊断和治疗仍然面临重大挑战。
这种资源分配不均使得眼部疾病的早期发现和干预变得尤为困难,进一步加重了这些疾病的负担。
人工智能(AI)通过自动化分析眼科图像和辅助医生诊断,可以显著减轻专科医生的工作负担。
近年来,全球范围内已经从执行单一任务转向构建基础模型。
这些模型在大量标记或未标记数据上进行预训练后,可以轻松适应各种下游任务,既节省了数据,又减少了数据准备的成本和时间,同时提高了模型的泛化能力。
RETfound 是眼科领域首个提出的基础模型,采用自监督重建学习,但它仅在彩色眼底摄影(CFP)和光学相干断层扫描(OCT)等单独的图像模态上进行训练。
为解决这个问题,EyeFound 被提出,它学习多模态眼科成像的共享表示。
然而,现有的基础模型仍然缺乏模态间一致性和图像-语言对齐,我们认为这在实际应用中至关重要。
在临床实践中,多种检查方法如 CFP、OCT、眼底荧光血管造影(FFA)和眼底自发荧光(FAF)等对于检查不同的眼部病理最为理想。
每种检查方法都能提供关于眼睛结构和功能的独特且互补的信息。
先前的研究已经证明了不同模态在提升 AI 模型疾病分类和分割能力方面的互补性。
因此,有效利用多模态数据对于获取多角度信息至关重要,确保模态间的一致性可以作为自监督学习的重要线索。
此外,专家解读的眼科报告和诊断提供了丰富的文本上下文,这有助于学习医学领域常见的具有层次概念的长尾表示。
通过整合临床文本,AI 模型可以更好地模拟人类专家的认知过程,使它们能够在不断变化的环境中处理复杂的、真实世界的临床问题。
在这项研究中,我们提出了 EyeCLIP,这是一个旨在利用真实世界多源、多模态数据的眼科视觉-语言基础模型。
EyeCLIP 在包含 2,777,593 张多模态眼科图像和来自 128,554 名患者的 11,180 份报告的数据集上进行了预训练,采用自监督学习和多模态对齐方法。
具体而言,训练过程结合了自监督重建、多模态图像对比和图像-文本对比学习。
随后,我们在 14 个多国数据集上验证了 EyeCLIP,评估了其在零样本、少样本和监督设置下在不同任务中的表现,包括多模态眼部疾病诊断、系统性疾病预测、视觉问答(VQA)和跨模态检索。
EyeCLIP 能够有效学习多种检查的共享表示,通过充分利用真实世界中大量未标记、多检查和标记数据,实现零样本疾病诊断和改进的语言理解。
我们相信,我们的方法不仅代表了眼科基础模型的重大进步,而且为在其他医学领域的临床实践中积累的不完整多模态医疗数据训练基础模型提供了宝贵的见解。
EyeCLIP 的开发利用了多中心、多模态的数据集
EyeCLIP 系统通过使用来自中国各地区和医院的 128,554 名患者的 277 万多张多模态图像和 11,180 份报告进行训练,全面学习眼科的视觉-语言特征。

这两张图共同描述了EyeCLIP(一种眼科视觉-语言基础模型)的研究设计和性能。
-
发展数据集 (a. Development Dataset):
- 来自中国9个省份、257家医院的128,554名参与者的数据。
- 包含2,777,593张图像,涵盖11种模态。
- 11,180份医疗报告。
- 使用分层关键词提取方法处理报告。
-
预训练 (b. Pretraining):
- 采用自监督重建学习。
- 跨模态(图像)对比学习。
- 文本-图像对比学习。
-
下游数据集 (c. Downstream Dataset):
- 包括单模态眼科任务、多模态眼科任务和系统性疾病预测。
- 使用来自多个国家的数据集进行验证。
- 涵盖零样本、少样本和监督微调场景。
-
下游性能 (d. Downstream Performance):
- 多模态多疾病分类。
- 跨模态检索(文本到图像、图像到图像、图像到文本)。
- 视觉问答任务。
-
EyeCLIP的优势:
- 在各种下游任务中显著优于基线模型。
- 包括零样本分类、多模态检索、视觉问答和监督系统性疾病预测。
总的来说,这些图展示了EyeCLIP模型的全面性能,从其大规模多模态数据集的构建,到预训练策略,再到在各种眼科相关任务中的出色表现。
EyeCLIP展现了在眼科领域应用视觉-语言模型的潜力,特别是在处理复杂的多模态数据和各种临床任务方面。
训练完成后, EyeCLIP 可以直接应用于分类和跨模态检索任务,无需额外训练。
此外,它还可以通过数据高效的方式进行微调,用于眼部疾病诊断、系统性疾病预测和交互式视觉问答(VQA)等下游应用。
图 2a 显示了 EyeCLIP 在各种下游任务中相比通用领域 CLIP 模型、医学领域 BioMedCLIP 和 PubMedCLIP 、以及眼科领域 RETFound 的整体优越性能。
EyeCLIP 在零样本、少量数据和全数据训练条件下的眼部疾病分类中表现卓越
零样本迁移能力使得单个预训练的基础模型可以直接应用于下游任务。
EyeCLIP 有潜力成为传统监督学习的强大基线,特别是在训练标签稀缺的情况下。
我们在九个公开的眼科数据集上评估了 EyeCLIP 的零样本分类性能,无需任务特定的训练。
使用彩色眼底照相(CFP)作为输入模态, EyeCLIP 在诊断眼科疾病方面显著优于其他模型(所有 P<0.001 ),在糖尿病视网膜病变(DR)诊断中 AUC 范围为 0.681 至 0.757 ,青光眼诊断中为 0.721 和 0.684 ,多种疾病诊断中为 0.660 和 0.688 。
对于光学相干断层扫描(OCT)图像, EyeCLIP 在 OCTID 和 OCTDL 数据集上分别达到了 0.800 和 0.776 的最高 AUROC 分数,显著高于其他模型(所有 P<0.001 )。
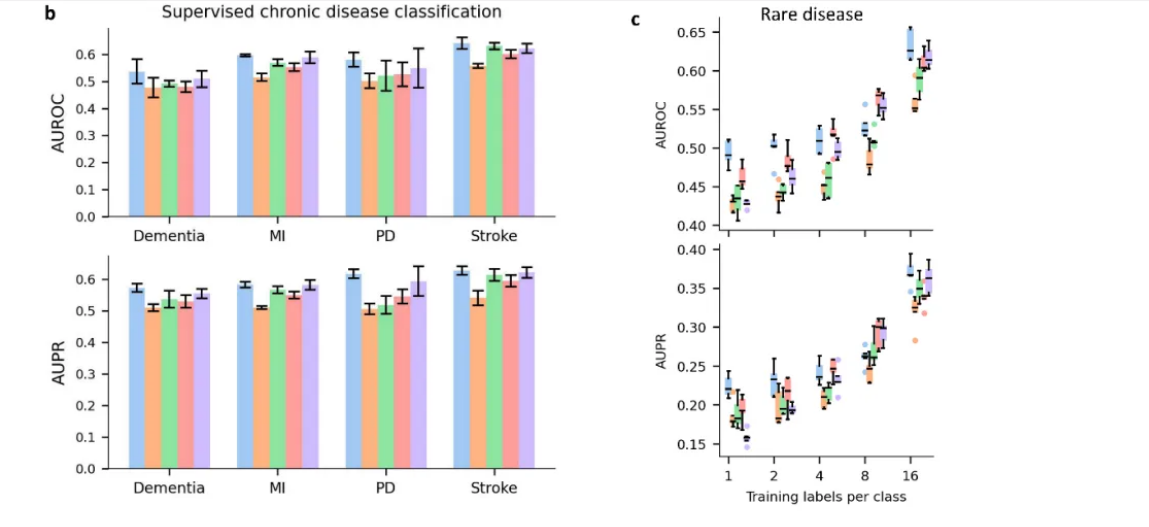
接下来,我们评估了 EyeCLIP 在这九个眼部疾病数据集上的少样本学习性能,分别使用 1、2、4、6 和 16 个有限的训练样本。
结果表明, EyeCLIP 能够在有限数据条件下实现良好的泛化,展示了以数据高效的方式诊断各种眼科疾病的能力,优于其他模型(所有 P<0.01 )。
AUROC 和 AUPR 的详细定量结果可在图 3 和扩展表 3 中查看。
特别值得注意的是,罕见疾病由于发病率低而常常缺乏足够的数据,这是医疗 AI 面临的常见挑战,因此最能从数据高效的训练中受益。
为此,我们进一步评估了 EyeCLIP 在罕见疾病少样本分类中的表现。
我们使用了由眼科医生精选的视网膜图像库子集,每个类别的图像数量大于 16 。
这个子集包含了 17 种罕见眼科疾病。
在所有测试设置中, EyeCLIP 在罕见疾病分类方面都优于其他模型。
详细结果可在图 4c 和扩展表 4 中查看。
最后,我们在 11 个包含单模态和多模态图像的公开数据集上,使用全数据监督训练范式测试了 EyeCLIP 的性能。
数据集按 55:15:30% 的比例分为训练、验证和测试集。
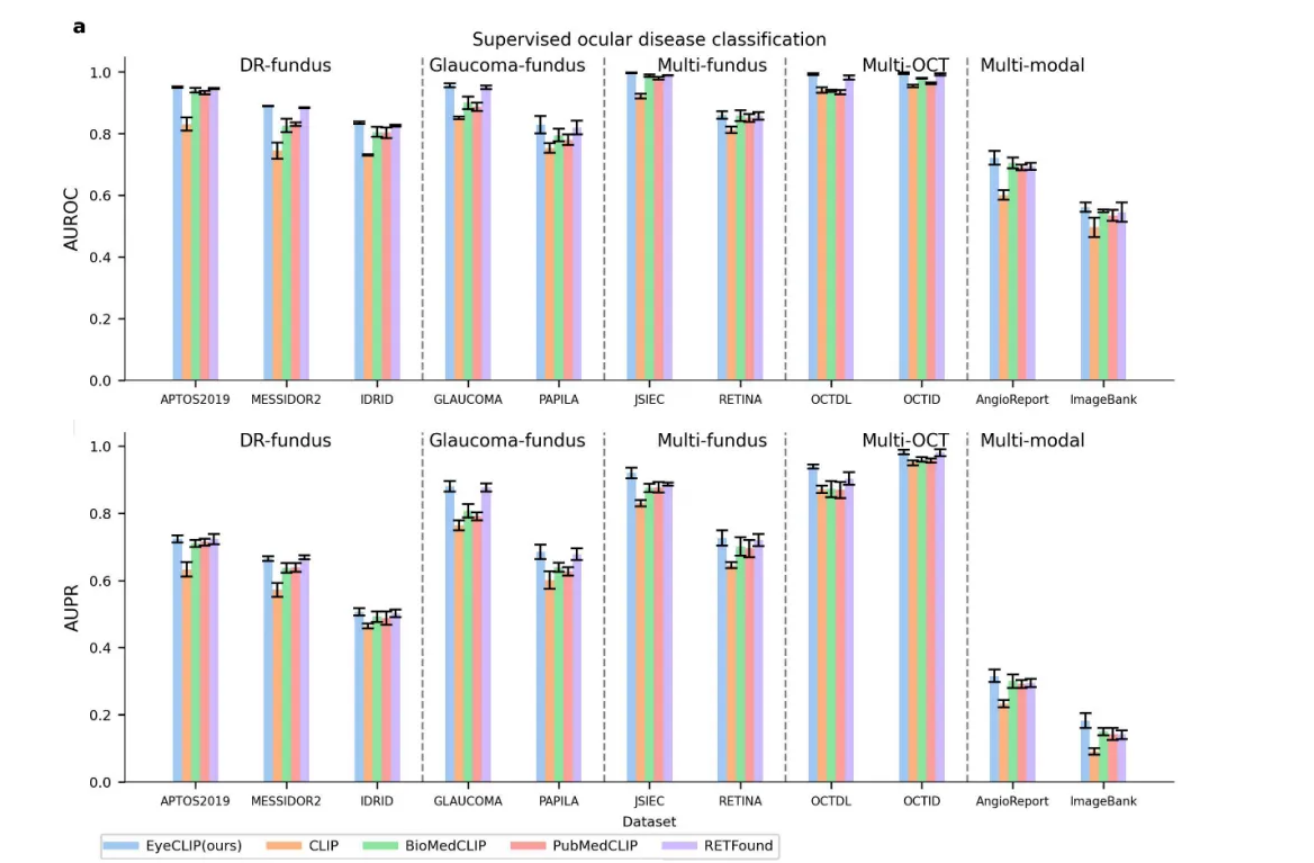
在单模态任务中, EyeCLIP 在大多数情况下优于竞争模型,仅在三个数据集上与第二好的模型 RETFound 性能相当。
在糖尿病视网膜病变分类任务中, EyeCLIP 在较小的 IDRiD 数据集上显著优于 RETFound ( AUROC 0.835 vs 0.826, P=0.013 ),而在更大的 APTOS2019 和 MESSIDOR2 数据集上与 RETFound 性能相当( P>0.05 )。
这表明 EyeCLIP 在数据效率方面优于 RETFound ,能够用更少的数据实现相同或更好的性能。
在青光眼和多种疾病分类任务中, EyeCLIP 始终优于其他模型。
对于 OCT 图像, EyeCLIP 在 OCTID 数据集上与 RETFound 性能相当( P>0.05 ),但在更具挑战性的 OCTDL 数据集上表现显著更好( AUROC 0.993 vs 0.982, P<0.001 )。
值得注意的是,尽管 RETFound 专门为 CFP 和 OCT 训练了独立的最优权重, EyeCLIP 仅使用一个通用编码器就达到了整体更好或相当的性能。
在多模态任务中, EyeCLIP 全面超越了所有比较模型。
在包含两种模态的 AngioReport 数据集上, EyeCLIP 以 0.721 的 AUROC 显著优于次优模型 BioMedCLIP 的 0.705 ( P<0.001 )。
更为引人注目的是, EyeCLIP 在具有 14 种模态和 84 种条件(包括罕见疾病)的高难度视网膜图像库数据集上表现最佳,AUROC 达到 0.561 ,显著优于第二好的模型 0.545 ( P<0.001 )。
EyeCLIP 在系统性疾病预测方面的表现
中风和心肌梗塞等系统性疾病对老年人构成重大威胁,常导致突发死亡。
眼睛被称为"身体健康的窗口",因为它富含可直接观察的血管。
因此,通过眼部检查预测系统性疾病的发生成为了早期筛查和预防的关键技术。
然而,这些疾病在一般人群中的发生率相对较低,导致正面训练数据有限。
在这种情况下,数据高效的训练方法变得尤为重要。
我们使用英国生物银行的数据评估了 EyeCLIP 基于眼科图像预测系统性疾病的性能。
实验包括对中风、痴呆、帕金森病和心肌梗塞的预测。
我们首先评估了 EyeCLIP 在少样本学习条件下的性能,分别使用 1、2、4、6 和 16 个有限的训练样本。
结果显示, EyeCLIP 在所有情况下都优于其他模型,展现出在预测系统性疾病方面的卓越数据效率。
在全数据监督训练中, EyeCLIP 排名第一,在各项指标上都取得了最佳成绩(所有 P<0.05 )。
EyeCLIP 在零样本跨模态检索中的表现
通过学习多模态嵌入的对齐潜在空间, EyeCLIP 实现了零样本跨模态检索能力。
这包括基于图像查询检索文本(图像到文本)、基于文本查询检索图像(文本到图像)、以及基于图像查询检索图像(图像到图像)。
这一功能在生物医学领域有广泛应用,如识别研究队列案例、辅助罕见疾病诊断和创建教育资源等。
我们在两个外部多模态图像-标题数据集(AngioReport 和视网膜图像库)上评估了 EyeCLIP 的性能,这些数据集涵盖了广泛的眼科概念。
为了专门研究其在罕见疾病上的表现,我们还手动选择了仅包含罕见疾病的视网膜图像库子集。
我们使用 Recall@K 作为评估指标,结果显示 EyeCLIP 在所有检索任务中都显著优于 BioMedCLIP (所有任务 P < 0.01 )。
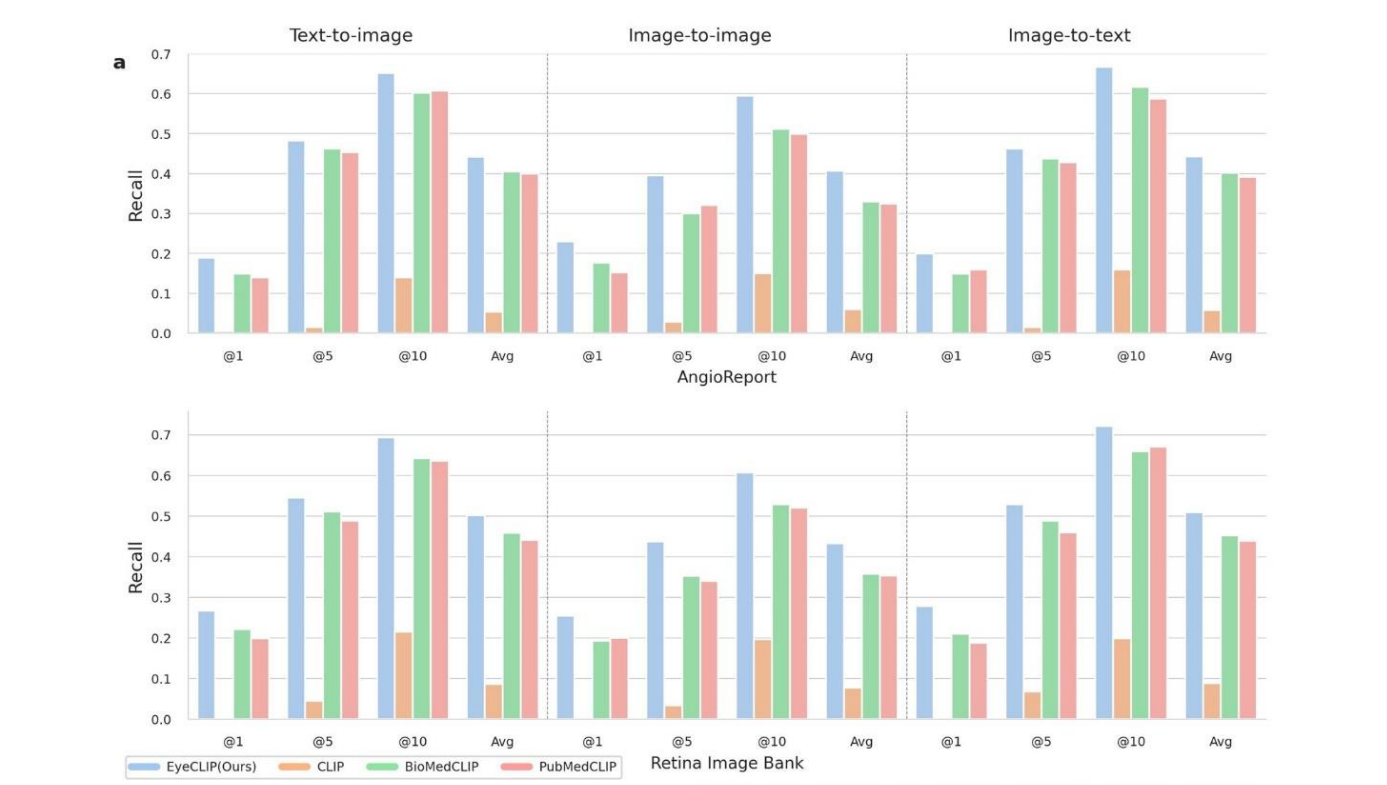

这三张图共同展示了EyeCLIP模型在零样本跨模态检索任务中的性能和工作原理。以下是对图中内容的详细分析:
-
图1:零样本多模态检索性能比较
- 展示了EyeCLIP与其他模型(CLIP, BioMedCLIP, PubMedCLIP)在两个数据集(AngioReport和Retina Image Bank)上的性能比较。
- 比较了三种检索任务:文本到图像、图像到图像、图像到文本。
- 使用Recall@K(K=1, 5, 10)和平均召回率作为评估指标。
- EyeCLIP在所有任务和数据集上都优于其他基线模型。
-
图2:跨模态检索的工作原理和示例
b. 展示了跨模态检索的基本原理:- 图像和文本通过各自的编码器映射到共同的嵌入空间。
- 在嵌入空间中计算相似度,检索最相似的结果。
c. 图像到图像检索示例:
- 展示了从不同模态(如SLO到FFA)或同一模态不同视野(如ICGA1到ICGA2)的图像检索。
d. 图像到文本和文本到图像检索示例:
- 展示了根据图像检索相关文本描述,以及根据文本描述检索相关图像的能力。
-
图3:图表说明
- 解释了图1中的实验设置和评估方法。
- 强调EyeCLIP在所有检索任务中都优于其他基线模型。
- 提到错误条表示95%置信区间。
- 指出更多示例可以在Extended Figure 2中找到。
这些图表全面展示了EyeCLIP在零样本跨模态检索任务中的卓越性能。
EyeCLIP能够有效地在图像和文本之间建立语义联系,实现高质量的跨模态检索。
这种能力在医学图像分析中特别有价值,可以帮助医生快速找到相关的病例、诊断信息和图像,提高诊断效率和准确性。
EyeCLIP的这种跨模态理解能力展示了其在医学AI领域的潜在应用价值,特别是在处理复杂的多模态医疗数据方面。
EyeCLIP 在视觉问答(VQA)任务上的零样本泛化能力
视觉-语言基础模型在眼科 VQA 任务中展现出了强大的泛化潜力。
我们将 EyeCLIP 的图像编码器与大型语言模型 Llama2-7b 结合,用于执行 VQA 任务。
由于缺乏成熟的公共眼科 VQA 数据集来进行少样本和全数据微调实验,我们使用视网膜图像库的多病数据进行微调,生成"Diagnosis:"作为问题来对齐图像、问题和语言模型特征。
随后,我们在外部 OphthalVQA 数据集上进行了零样本 VQA 测试,无需进一步训练。
OphthalVQA 是一个开放集 VQA 数据集,包含 6 种模态的 60 张图像,涉及 60 种眼科条件和 600 对问答对。
结果显示, EyeCLIP 展现出与大型语言模型的优越对齐能力,尽管图像和语言模块并未专门在开放集 VQA 数据上进行对齐。
EyeCLIP 在所有评估指标上都排名第一,包括精确匹配分数、F1 分数、精确度、召回率和 BLEU 分数(所有 P<0.001 )。
总的来说, EyeCLIP 在多个眼科相关任务中展现出了卓越的性能和泛化能力,为眼科诊断和研究提供了强大的工具支持。
讨论
本研究开发了 EyeCLIP ,这是一个多模态眼科图像分析的视觉-语言基础模型。
该模型利用了包含近 280 万张眼科图像的大型数据集,涵盖 11 种模态,并配有相应的分层语言数据。
我们创新的训练策略充分利用了真实世界数据的特性,包括多重检查和大量未标记及标记数据。
这种方法实现了跨多种检查和模态的共享表示。
EyeCLIP 显著提升了眼科和系统性疾病的分析能力,在零样本、少样本和全数据微调的下游任务中展现了最先进的效率和泛化能力。
EyeCLIP 的一个主要优势在于其多重检查的对齐能力,这一点在图像-图像检索任务和多模态图像分类任务中得到了充分证明。
相比之下,传统基础模型通常只专注于特定类型的检查,这限制了它们在实际应用中的有效性。
考虑到实际临床环境的复杂性,患者常常呈现各种病况并需要接受多重检查,因此,一个能够利用不同图像模态准确识别多种眼部病况的模型是非常必要的。
EyeCLIP 的开发涉及 11 种来自不同人群的模态,这使得它独特而强大,特别是在识别威胁视力的疾病方面表现出色,尤其是在标签不平衡的多模态、多疾病诊断中。
值得注意的是,在具有挑战性的视网膜图像库上的表现,突显了 EyeCLIP 在管理多样化检查的罕见眼部疾病方面的潜力。
EyeCLIP 的另一个主要优势是其整合了视觉-语言预训练。
与先前主要专注于从丰富图像数据中提取有意义模式的基础模型不同, EyeCLIP 利用医疗专业人员创建的文本描述来提炼分层上下文信息。
通过采用文本-图像对比学习, EyeCLIP 最大化了所有可用标记眼科数据的使用,学习了疾病表现的丰富语义特征。
这种对齐提供了零样本能力,显著减少了对大量训练数据标注的需求。
这一特性在资源有限的环境和偏远地区特别有价值,因为这些地方获得专业医疗服务的机会受限。
对于罕见疾病的诊断也同样适用。
此外,零样本视觉问答(VQA)能力为在临床环境中自动化解释任务提供了独特机会,只需最小的模型调整。
EyeCLIP 能够以最少的训练数据运作并适应新任务的能力,使其成为广泛扩展优质眼科护理覆盖范围的宝贵工具。
眼科图像由于其易获取性,越来越多地用于指示系统性疾病。
这是基础模型可能发挥重要作用的领域,因为与健康人群相比,疾病事件数据相对稀缺。
值得注意的是, EyeCLIP 显著改善了系统性疾病预测,在中风、痴呆、帕金森病和心肌梗塞等疾病的预测中超越了先前的医学领域基础模型,如 BioMedCLIP 和眼科领域的 RETFound 。
这种改进可能归因于不同检查数据的共享表示。
例如,血管造影提供了更清晰的视网膜血管和病变可视化,这些特征可以被模型共同学习。
经过进一步优化, EyeCLIP 有望成为早期检测和监测系统性疾病的强大工具,从而增强超越眼科范畴的患者护理。
这项研究为其他处理不完整或未对齐数据的医学领域提供了宝贵的见解。
在实际临床实践中,数据集通常包含多模态信息,如图像和文本,这些信息在每个样本中并不完全对齐。
我们通过采用结合单一模态内的掩码图像重建自监督学习和可用时跨对齐多模态数据的对比学习策略来解决这一挑战。
这种方法最大化了实践中积累的多样化临床数据的效用,为在其他存在不完整多模态数据的领域开发医学基础模型提供了潜在框架。
我们的研究也存在一些局限性。
首先, EyeCLIP 的性能依赖于训练数据的质量和多样性。
使用更全面的临床和人口统计数据集进行额外训练,并增加更多文本标签,可能会改善其在不同人群中的预测性能和实用性。
其次,整合视觉和语言数据带来了挑战。
语言描述的质量和一致性因医疗专业人员的专业知识和文档实践而异。
开发标准化协议以生成和注释眼科学中的文本数据,并实施结构化报告模板以确保一致性,预计将缓解这一问题并增强模型从多模态数据中的学习能力。
第三,在实际临床环境中部署 EyeCLIP 需要仔细考虑实际和伦理问题。
模型的预测需要可解释和透明,以获得医疗提供者和患者的信任,确保在临床实践中成功实施。
总之,我们开发的 EyeCLIP 是一个具有共享多模态表示特征的视觉-语言基础模型,能够执行广泛的下游任务。
这种创新的训练策略与真实世界数据特征高度吻合,可能为一般医学领域基础模型的开发提供重要启示。
EyeCLIP 在眼部和系统性疾病方面的出色性能和广泛适用性,使其成为一个极具前景的工具,有望显著提高眼科临床实践和研究中人工智能的准确性、效率和可及性。
方法
伦理声明
本研究遵循《赫尔辛基宣言》进行,并获得了香港理工大学伦理委员会的批准。
由于研究对象是匿名的眼科图像和公开数据集,委员会免除了知情同意的要求。
预训练数据的收集和预处理
我们从中国 227 家医院收集了近 280 万张来自 12.8 万多名患者的未标记眼科图像。
这些图像涵盖了各种眼部疾病,包括 11 种不同的成像方式,如彩色眼底照相、眼底荧光血管造影等。
为确保数据质量,我们通过分析血管结构,剔除了低质量图像。语言训练数据来自 1.1 万多份血管造影报告。
我们开发了专门的算法,将报告中的医学知识转化为涵盖眼科疾病、解剖结构和诊断指标等方面的关键词集。
这一过程为后续的图像-文本对齐和预训练提供了重要的语义信息。
所有数据在使用前都经过了匿名化处理。
为促进多模态对齐,我们匹配了同一患者的不同检查图像,使模型能够更好地学习跨检查方式的特征。
我们还使用专门的词典清理了医疗报告,生成了分层的关键词文本标签。
下游验证数据的收集和预处理
我们使用了 14 个数据集进行下游任务验证,涵盖眼部疾病诊断、系统性疾病预测、多模态疾病分类和视觉问答任务。
这些数据集包括:
-
9 个公开的单模态眼科疾病分类数据集,来自不同国家和地区。
-
2 个多模态、多标签数据集:AngioReport 和 Retina Image Bank。
-
OphthalVQA 数据集,用于视觉问答任务。
-
UK Biobank 数据集,用于系统性慢性疾病预测。
模型设计和训练细节
我们以 CLIP 为基础框架,并进行了创新性扩展。主要改进包括:
-
添加图像解码器,实现掩码图像重建。
-
修改损失函数,包含图像-文本对比、图像-图像对比和图像重建损失。
-
所有图像共享同一编码器,确保跨模态的一致特征提取。
训练过程中,我们采用了学习率预热和余弦退火等技巧,在高性能 GPU 上训练了约四周。
比较模型
我们选择了 PubMedCLIP、BioMedCLIP 和 RETFound 作为比较基准。这些模型分别代表了医学领域、生物医学领域和眼科领域的先进水平。
下游任务评估
我们评估了 EyeCLIP 在以下任务中的表现:
-
零样本分类
-
全数据微调分类
-
少样本分类
-
跨模态检索
-
视觉问答
对于每项任务,我们采用了特定的评估方法和指标,如 AUROC、Recall@K 等,以全面衡量模型的性能。
总的来说,这种方法设计旨在充分利用多模态医学数据,提高模型在眼科领域的泛化能力和实际应用价值。
评估指标
我们主要使用 AUROC (受试者工作特征曲线下面积)和 AUPR (精确率-召回率曲线下面积)来评估分类任务的性能。
这两个指标能有效衡量模型在不同阈值下的分类效果。
对于眼部疾病诊断等二元分类任务,我们直接计算这两个指标。
而对于多类分类任务,如分级糖尿病视网膜病变和多种疾病诊断,我们先对每个类别单独计算这两个指标,然后取平均值作为整体性能指标。
在视觉问答(VQA)任务中,我们采用了多种评估指标,包括精确匹配分数、F1 分数、精确率、召回率,以及用于评估生成文本质量的 BLEU 分数。
对于检索任务,我们使用了 Recall@K 指标,即在检索结果的前 K 个样本中,正确结果所占的比例。
统计分析
我们计算了平均性能和 95% 置信区间,并使用双侧 t 检验来比较 EyeCLIP 与其他先进模型(如 CLIP 、 BioMedCLIP 、 PubMedCLIP 和 RETFound )的性能差异,以确定统计显著性。
数据和代码可用性
由于隐私和版权原因,我们无法公开用于开发 EyeCLIP 的原始数据集。
但下游任务使用的公开数据集可以通过原始论文获取。
我们的代码已在 GitHub 上公开,可供研究社区使用和验证。
致谢与作者贡献
我们感谢美国视网膜专科医师学会提供的 Retina Image Bank 数据集。
本研究由多位作者共同完成,包括研究构思、模型构建、实验进行、数据解释和论文撰写等各个环节。
所有作者都参与了论文的修改工作。
利益声明与资金支持
作者声明没有任何利益冲突。
本研究得到了香港特别行政区政府的资金支持,包括全球 STEM 教授计划和战略性招聘计划下的启动基金。
资助方在研究的设计和实施过程中没有任何影响。

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









