







1.概述
工业缺陷检测是工业自动化和质量控制中的一个重要环节,其目的是在生产过程中识别和分类产品或组件中的缺陷,以确保最终产品的质量满足既定标准。这项技术的应用可以显著提高生产效率,降低成本,并减少由于缺陷产品导致的潜在安全风险。
1.1 工业异常检测的关键点:
- 质量控制:通过检测产品制造过程中的缺陷,确保产品质量符合标准。
- 过程监控:实时监控生产过程,及时发现并纠正可能导致质量问题的因素。
- 预测性维护:通过分析设备状态,预测潜在的故障,从而在问题发生前进行维护。
- 自动化:减少人工检查的需求,提高检测速度和准确性。
- 数据驱动:利用从传感器、摄像头等收集的数据进行分析,以识别异常模式。
常用的工业异常检测方法:
- 统计过程控制(SPC):使用统计方法监控和控制生产过程,以减少变异。
- 机器学习:应用各种机器学习算法,如支持向量机(SVM)、随机森林、神经网络等,来识别异常。
- 深度学习:使用深度神经网络,尤其是卷积神经网络(CNN)来处理视觉数据,检测图像中的异常。
- 时间序列分析:分析传感器数据的时间序列,以识别设备运行中的异常模式。
- 视觉-语言模型:结合视觉和语言信息,提高对异常的识别能力。
1.2 工业异常检测的挑战:
- 数据获取:收集足够的、标注良好的训练数据可能很困难,尤其是在高度专业化的工业环境中。
- 实时性:在快速的生产线上实时检测异常是一个技术挑战。
- 泛化能力:模型需要能够泛化到不同类型的异常和不同的生产条件下。
- 解释性:在工业应用中,模型的决策过程需要足够透明,以便工程师能够理解并信任系统的输出。
- 集成:将异常检测系统与现有的生产线和IT基础设施集成可能需要克服技术和操作上的障碍。
1.3 工业异常检测的应用:
- 半导体制造:检测晶片上的微小缺陷。
- 汽车工业:检查装配线上的零部件。
- 包装行业:确保包装完整性和标签正确。
- 机械制造:监测机床状态,预防设备故障。
2. LLM与工业缺陷检测结合应用
随着大语言模型(LLMs)的兴起,它们在工业缺陷检测领域的应用变得越来越多样化和深入。以下是大语言模型与工业缺陷检测结合的几个关键方面:
自动化标注:LLMs可以自动生成或辅助生成训练数据的标注,减少人工标注的需求。通过理解缺陷的描述性语言,模型能够识别图像中的缺陷并标注。
缺陷识别:LLMs可以被训练来识别图像或传感器数据中的缺陷模式。它们可以从大量未标记的数据中学习,并通过迁移学习适应特定的工业应用。
多模态检测:结合视觉和语言信息,LLMs可以进行多模态学习,提高缺陷检测的准确性。例如,模型可以同时处理图像数据和相关的技术文档,以更好地理解和识别缺陷。
上下文理解:LLMs能够理解复杂的上下文信息,包括产品规格、制造过程和历史缺陷数据,这有助于提高缺陷检测的相关性和准确性。
预测性维护:LLMs可以分析历史维护记录和实时传感器数据,预测设备可能出现的故障,从而实现预测性维护。
交互式检测:LLMs可以提供交互式的缺陷检测体验,允许操作员通过自然语言查询来获得关于缺陷的详细信息和建议。
持续学习:LLMs可以不断地从新的数据中学习,自动更新其知识库,以适应生产过程中的变化。
报告和文档:LLMs可以自动生成关于缺陷检测结果的详细报告,包括缺陷的类型、位置、严重程度和可能的原因。
模型解释性:尽管LLMs通常被认为是“黑盒”模型,但它们可以提供一定程度的解释性,帮助理解缺陷检测的决策过程。
跨领域应用:LLMs的通用性使得它们可以跨不同的工业领域应用,从汽车制造到半导体生产,再到食品加工等。
然而,将LLMs应用于工业缺陷检测也面临一些挑战,包括但不限于:
- 数据隐私和安全性:工业数据往往涉及敏感信息,需要确保在处理和分析数据时遵守数据保护法规。
- 模型泛化能力:需要确保模型不仅在训练数据上表现良好,也能泛化到新的、未见过的数据。
- 实时性能:工业环境要求缺陷检测系统具有高实时性,这可能对模型的复杂性和计算资源提出挑战。
- 集成和兼容性:将LLMs集成到现有的工业系统中可能需要解决技术和操作上的兼容性问题。
3. AnomalyGPT
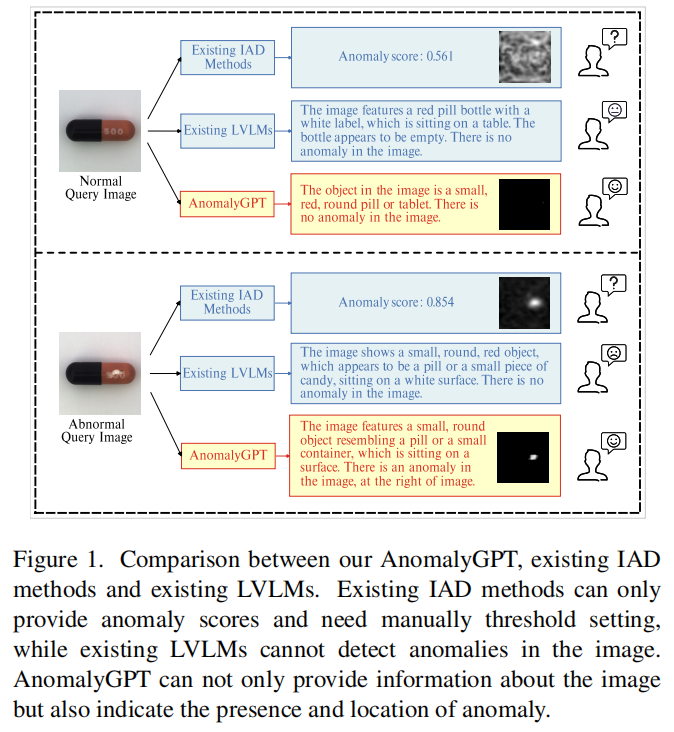
AnomalyGPT是第一个基于大型视觉-语言模型(LVLM)的工业异常检测(IAD)方法,可以在不需要手动指定阈值的情况下检测工业图像中的异常。现有的IAD方法只能提供异常评分并需要手动设置阈值,而现有的LVLMs无法检测图像中的异常。AnomalyGPT不仅可以显示异常的存在和位置,还可以提供图像的相关信息。
项目地址:https://anomalygpt.github.io/
论文地址:https://arxiv.org/pdf/2308.15366.pdf
Github地址:https://github.com/CASIA-IVA-Lab/AnomalyGPT
3.1 AnomalyGPT概述
本文提出了一种基于大型视觉语言模型的工业异常检测方法AnomalyGPT。该方法通过模拟异常图像并生成相应的文本描述来生成训练数据,并使用图像解码器提供细粒度语义。AnomalyGPT消除了手动阈值调整的需要,直接评估异常的存在和位置。此外,AnomalyGPT支持多轮对话,并展现了令人印象深刻的少样本上下文学习能力。在MVTec-AD数据集上,AnomalyGPT实现了86.1%的准确率,94.1%的图像级AUC和95.3%的像素级AUC的最新性能。
IAD任务旨在检测和定位异常。目前工业产品图像异常检测方法通常只提供测试样本的异常分数,并需要手动设置阈值来区分正常和异常实例,这在实际生产环境中不适用。
AnomalyGPT是一种基于LVLM的新型IAD方法,可以检测异常的存在和位置,无需手动设置阈值。此外,该方法可以提供图像信息和交互式参与,允许用户根据需要提出后续问题。AnomalyGPT还可以在少量正常样本的情况下进行上下文学习,快速适应以前未见过的对象。

工业产品图像异常检测(IAD)任务的目标是检测和定位异常。目前的工业产品图像异常检测方法通常只提供测试样本的异常分数,并需要手动设置阈值来区分正常和异常实例,这在实际生产环境中并不适用。
AnomalyGPT是一种基于LVLM的新型IAD方法,可以检测异常的存在和位置,无需手动设置阈值。此外,该方法可以提供图像信息和交互式参与,允许用户根据需要提出后续问题。AnomalyGPT还可以在少量正常样本的情况下进行上下文学习,快速适应以前未见过的对象。


本文提出了一种使用合成的异常视觉-文本数据来微调LVLM模型的方法,并将IAD知识集成到模型中。由于IAD数据稀缺,我们使用提示嵌入来微调LVLM,而不是参数微调。我们还提出了一种轻量级的视觉-文本特征匹配解码器,用于生成像素级异常定位结果,并将其与原始测试图像一起通过提示嵌入引入LVLM,从而提高其判断准确性。
我们在MVTec-AD和VisA数据集上进行了大量实验。在MVTec-AD数据集上进行无监督训练时,我们实现了93.3%的准确率,97.4%的图像级AUC和93.1%的像素级AUC。当将模型迁移到VisA数据集时,我们实现了77.4%的准确率,87.4%的图像级AUC和96.2%的像素级AUC。相反,在VisA数据集上进行无监督训练后,将模型迁移到MVTec-AD数据集上,我们实现了86.1%的准确率,94.1%的图像级AUC和95.3%的像素级AUC。
我们的贡献如下:
- 首次将LVLM应用于工业异常检测领域,实现了自动检测和定位异常,并支持多轮对话。
- 通过轻量级的视觉-文本特征匹配解码器,解决了LLM在细粒度语义辨别上的局限性,并减轻了LLM仅能生成文本输出的限制。
- 使用提示嵌入进行微调,并与LVLM预训练数据同时训练,从而保留了LVLM的固有能力,并实现了多轮对话。
- 本方法具有强大的迁移能力,在新数据集上能够进行上下文少样本学习,并取得了出色的性能。
4.相关工作
4.1 工业异常检测
工业异常检测方法主要可分为基于重构和基于特征嵌入的两种类型。
-
基于重构的方法旨在将异常样本重构为其对应的正常样本,并通过计算重构误差来检测异常。RIAD、SCADN、InTra和AnoDDPM采用不同的重构网络架构,包括自编码器、生成对抗网络、Transformer和扩散模型。
-
特征嵌入方法通过建模正常样本的特征嵌入来检测异常。这些方法包括PatchSVDD、Cflow-AD、PyramidFlow、PatchCore和CFA等。它们的实现方式包括寻找紧密包围正常样本的超球体、使用正态流将正常样本投影到高斯分布上、建立正常样本的嵌入存储库并通过测量测试样本嵌入与存储库中最近的正常嵌入之间的距离来检测异常。
传统的方法需要大量的正常样本来学习每个对象类的分布,因此对于新的对象类和动态生产环境来说并不实用。相比之下,我们的方法可以为新的对象类进行上下文学习,只需要少量的正常样本就可以进行推理。
4.2 少样本/零样本工业异常检测
最近的工作集中在利用少量正常样本来进行工业异常检测。PatchCore构建了一个只使用少量正常样本的存储库,导致性能下降。RegAD训练了一个图像配准网络来对齐测试图像和正常样本,然后计算对应补丁的相似度。WinCLIP利用CLIP计算图像和文本描述之间的相似度,区分正常和异常语义,但这些方法只能在推理过程中为测试样本提供异常分数。与之相反,我们的方法可以直接评估测试样本中是否存在异常并确定其位置,具有更强的实用性。
**大视觉-语言模型。**LLMs在视觉任务中得到了探索,BLIP-2、MiniGPT-4和PandaGPT等模型将视觉特征与语言模型相结合,进行了多模态输入和两阶段微调等操作。这些方法展示了LLMs在视觉任务中的潜力。
AnomalyGPT是一种新方法,通过利用模拟异常数据、图像解码器和提示嵌入,实现了IAD任务,无需手动指定阈值,同时也实现了少量上下文学习。与现有方法相比,AnomalyGPT在各种功能上具有更好的表现。
5.算法架构
AnomalyGPT是一种新颖的对话式IAD视觉-语言模型,主要用于检测工业制品图像中的异常并确定其位置。我们利用预训练的图像编码器和LLM通过模拟异常数据来对齐IAD图像和对应的文本描述。我们引入了解码器模块和提示学习模块,以提高IAD性能并实现像素级定位输出。使用提示调整和与预训练数据的交替训练可以保持LLM的可转移性并防止灾难性遗忘。我们的方法具有强大的少样本迁移能力,仅需提供一个正常样本即可检测和定位以前未见过的物品的异常。
5.1 模型架构
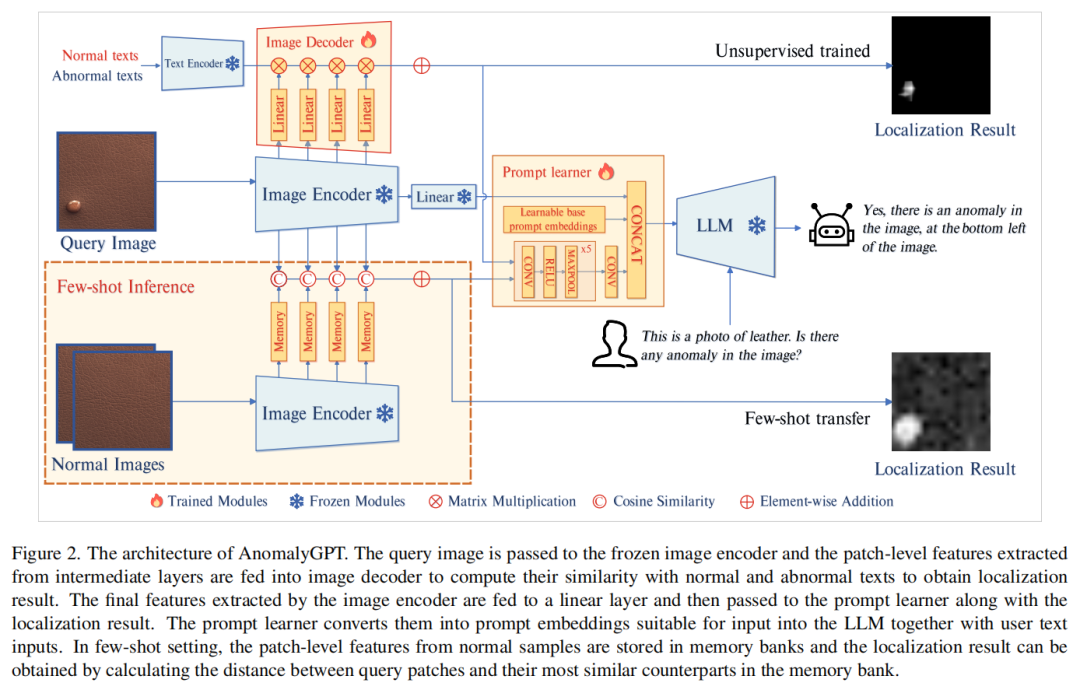
AnomalyGPT模型架构包括图像编码器、线性层、局部线性模型、解码器、记忆库和提示学习器。在无监督学习中,模型使用中间层的补丁级特征和文本特征生成像素级异常定位结果。在少样本学习中,正常样本的补丁级特征存储在记忆库中,查询补丁与记忆库中最相似的补丁进行比较,从而得到异常定位结果。LLM利用图像输入、提示嵌入和用户提供的文本输入来检测异常并确定其位置,为用户生成响应。
5.3 解码器和提示学习器
**解码器。**为了实现像素级别的异常检测,我们采用了一种轻量级的基于特征匹配的图像解码器,支持无监督IAD和少样本IAD。该解码器的设计主要受到PatchCore、WinCLIP和APRIL-GAN的启发。
本文将图像编码器分为四个阶段,提取每个阶段的中间补丁级特征,并使用线性层将其投影到文本特征上,以对齐正常和异常语义。通过这种方法,可以得到本地化结果。
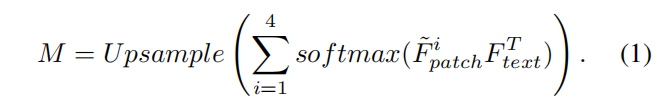
在few-shot IAD中,我们使用相同的图像编码器从正常样本中提取中间的补丁级特征,并将其存储在内存库中。这些特征用于不同阶段的处理。通过计算每个补丁与记忆库中最相似的补丁之间的距离,可以得到本地化结果M。
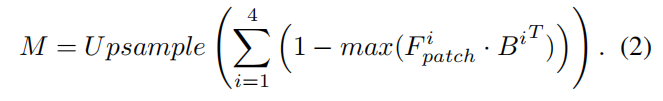
**提示学习器。**为了利用图像的细粒度语义并保持LLM和解码器输出之间的语义一致性,我们引入了一个提示学习器,将定位结果转换为提示嵌入。此外,可学习的基本提示嵌入被纳入提示学习器中,为IAD任务提供额外信息。最后,这些嵌入以及原始图像信息被馈入LLM。
这个模型包括可学习的基础提示嵌入和卷积神经网络。网络将定位结果转换为提示嵌入,与图像嵌入结合成为LLM。
图像-文本对齐数据
**异常模拟。**主要采用NSA提出的方法,该方法结合了Cut-paste和Poisson image editing技术,可以有效地生成模拟异常样本。Cut-paste技术是一种常见的IAD领域的技术,但会导致明显的不连续性。Poisson editing方法可以无缝地将一个对象从一个图像克隆到另一个图像。

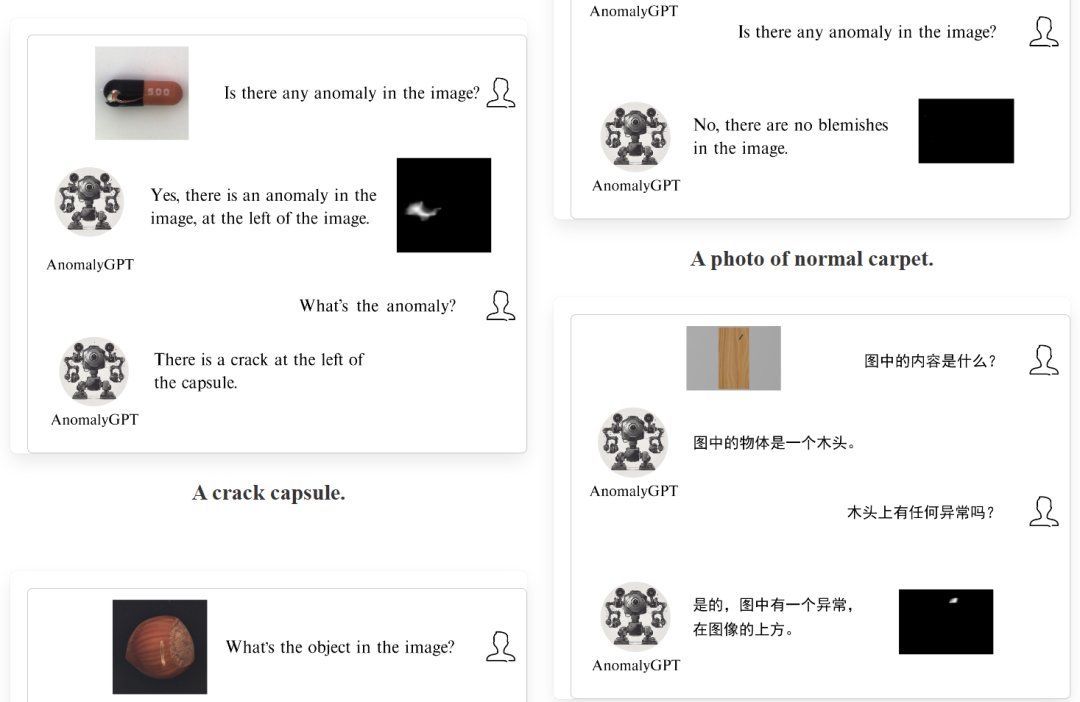
**问答内容。**为了进行LVLM的快速调整,我们根据模拟的异常图像生成相应的文本查询。每个查询由两个部分组成。第一部分是关于输入图像的描述,提供有关图像中存在的对象及其预期属性的信息,例如“这是一张皮革的照片,应该是棕色的,没有任何损坏、瑕疵、缺陷、划痕、洞或破损部分”。第二部分查询对象中是否存在异常,即“图像中是否有异常?”LVLM首先回答是否存在异常。如果检测到异常,模型将继续指定异常区域的数量和位置,例如“是的,图像中有一个异常,在图像的左下方”或“不,图像中没有异常”。我们将图像分成一个3×3的网格,以便LVLM能够口头指示异常的位置。图像的描述内容为LVLM提供了关于输入图像的基础知识,有助于模型更好地理解图像内容。然而,在实际应用中,用户可以选择省略这个描述性输入,模型仍然可以正常工作。任务要求模型仅通过提供的图像输入执行IAD任务,详细说明了每个类别。附录C提供了详细描述。


损失函数
训练解码器和提示学习器主要使用了三种损失函数:交叉熵损失、焦点损失和Dice损失。后两种主要用于提高解码器的像素级定位精度。
**Cross-entropy Loss。**交叉熵损失常用于训练语言模型,用于衡量模型生成的文本序列与目标文本序列之间的差异。公式如下:
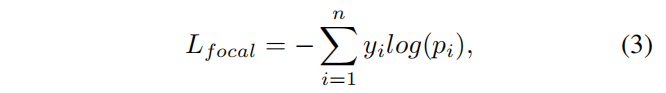
根据每个标记的真实标签和预测概率,计算标记级别的交叉熵损失。
Focal Loss是用于解决类别不平衡问题的一种损失函数,常用于目标检测和语义分割。在IAD任务中,使用Focal Loss可以缓解类别不平衡问题。其计算方式可以通过公式(4)得出。
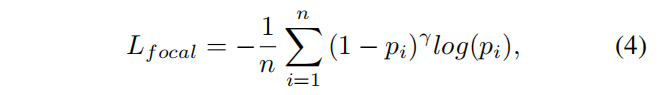
n表示像素总数,pi表示正类的预测概率,γ是一个可调参数,用于调整难分类样本的权重。在实现中,我们将γ设置为2。
Dice Loss是语义分割任务中常用的损失函数,基于Dice系数计算。
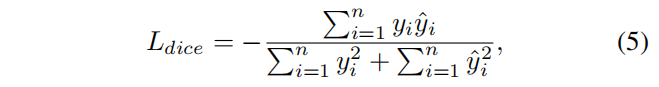
n为像素总数,yi为解码器输出,yˆi为真实值。
最终损失函数如下:
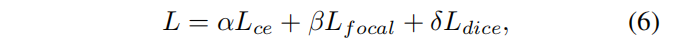
三个损失函数的系数默认为1,用于平衡损失函数。
6. 实验
**数据集。**本文主要在MVTec-AD和VisA数据集上进行实验,这两个数据集都是IAD领域常用的数据集。MVTec-AD数据集包含15个类别的3629张训练图像和1725张测试图像,VisA数据集包含12个类别的9621张正常图像和1200张异常图像。我们只使用这些数据集中的正常数据进行训练。
**评估指标。**本文采用现有的IAD方法,使用接收器操作特征曲线下面积(AUC)作为评估指标,分别评估异常检测和异常定位的性能。此外,我们的方法还可以在不需要手动设置阈值的情况下确定异常的存在,因此我们还使用图像级别的准确性来评估我们的方法的性能。
**实验细节。**使用ImageBind-Huge作为图像编码器,Vicuna-7B作为推理LLM,并通过线性层连接。模型初始化使用PandaGPT的预训练参数。图像分辨率设置为224×224。使用ImageBind-Huge的图像编码器的第8、16、24和32层的输出作为图像解码器的输入。训练在两个RTX-3090 GPU上进行,共进行50个epoch,学习率为1e-3,批量大小为16。应用线性预热和一周期余弦学习率衰减策略。我们使用PandaGPT的预训练数据和异常图像-文本数据进行交替训练。只有解码器和提示学习器进行参数更新,其余参数都保持冻结状态。
定量结果
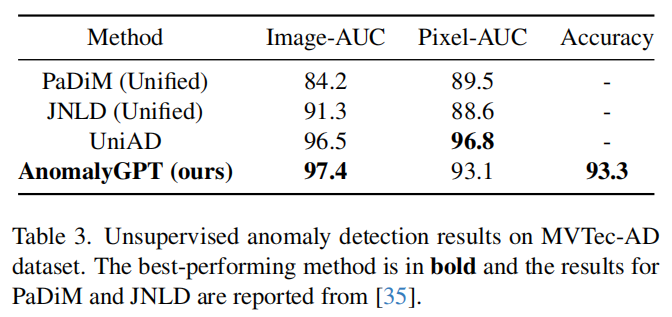
**少样本工业异常检测。**我们的方法在工业异常检测中表现优于之前的方法,包括SPADE、PaDiM、PatchCore和WinCLIP。我们的方法在图像级AUC方面表现出色,并且在像素级AUC和准确率方面也具有竞争力。

**无监督工业异常检测。**MAD-GAN使用生成对抗网络(GAN)来学习正常样本的分布,并使用重构误差来检测异常。与其他方法相比,MAD-GAN在MVTec-AD数据集上表现出更好的性能。
定性样例


本模型能够进行无监督异常检测和1-shot上下文学习,并能指示异常的存在、定位异常位置并提供像素级定位结果。用户可以进行与异常相关的多轮对话。1-shot in-context learning是一种新的学习方式,相比无监督学习,其模型的定位性能稍微差一些。
消融分析
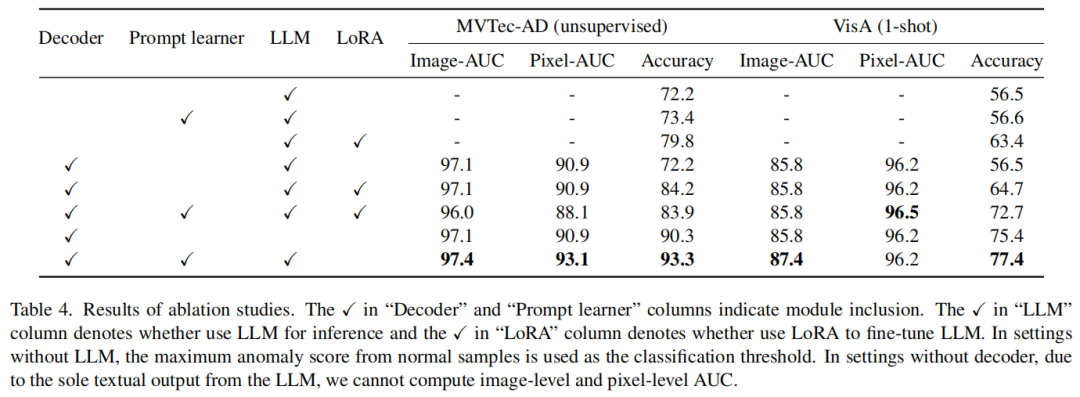
通过对MVTec-AD和VisA数据集进行广泛的消融实验,证明了所提出的模块的有效性。主要关注四个方面:解码器、提示学习器、LLM用于推理和使用LoRA微调LLM。实验结果表明,解码器表现出令人印象深刻的像素级异常定位性能,LLM在推理准确性和功能方面优于手动设置阈值,提示调整在准确性和可转移性方面优于LoRA。
8.环境配置
当然!这里是一些润色后的文本:
2.1 下载环境
首先,将项目克隆到本地:
git clone https://github.com/CASIA-IVA-Lab/AnomalyGPT.git
接着,安装所需的软件包:
pip install -r requirements.txt
2.2 准备ImageBind检查点
您可以通过以下链接下载预先训练的图像绑定(ImageBind)模型。下载完成后,请将文件(imagebind_huge.pth)放置在路径[./pretrained_ckpt/imagebind_ckpt/]下。
2.3 准备Vicuna检查点
要准备预先训练的Vicuna模型,请按照以下说明操作:
2.4 准备AnomalyGPT的Delta权重文件
我们使用PandaGPT的预训练参数来初始化我们的模型。您可以在下表中获得不同策略下的PandaGPT的权重。在实验和在线演示中,由于计算资源的限制,我们建议使用vicuna-7b和pandagpt_7b_max_len_1024。如果切换到Vicuna-13b,预计会获得更好的结果。
将已下载的7B delta权重文件放置在以下路径:
./pretrained_ckpt/pandagpt_ckpt/7b/
如果是13B delta权重文件,将其放置在以下路径:
./pretrained_ckpt/pandagpt_ckpt/13b/
接下来,下载AnomalyGPT的模型权重文件。下载完成后,将其放置在项目路径下的 ./code/ckpt/ 中。在官方项目的在线演示中,默认使用了监督设置作为模型的默认配置,以提升用户体验。您也可以在本地尝试其他权重。
2.5 运行演示
完成上述步骤后,您可以运行以下命令,在本地启动演示Demo:
cd ./code/
python web_demo.py
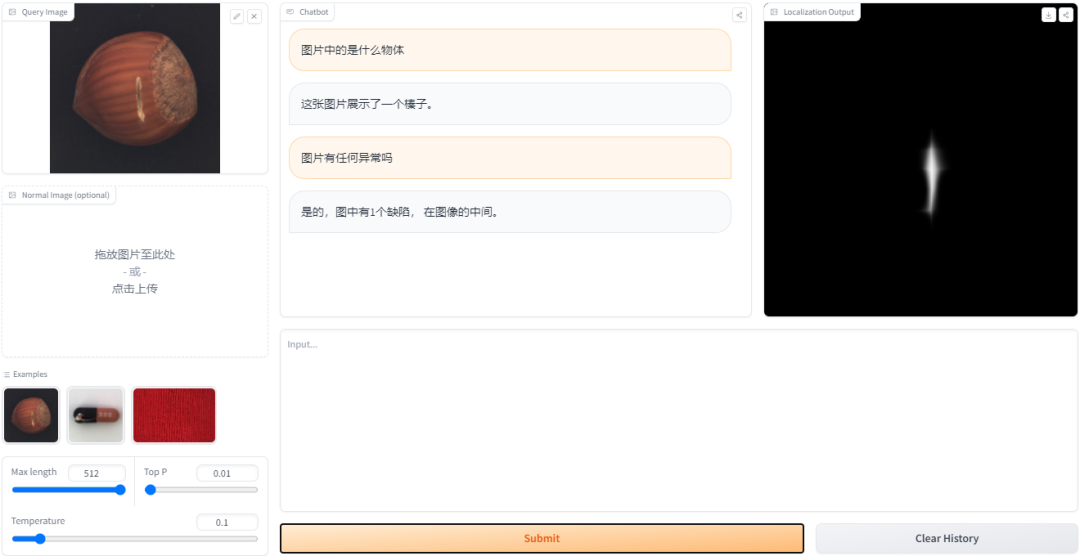
在用了Hugging Face上的AnomalyGPT Demo,虽然需要2-3分钟的运行时间,但模型的异常检测能力值得肯定!



8.总结
AnomalyGPT是一种新型的对话式图像异常检测模型,利用了LVLM的强大能力。它可以确定图像是否包含异常,并指出其位置,无需手动指定阈值。此外,AnomalyGPT还能够进行多轮对话,展现出在少量数据下的上下文学习能力。该模型在两个常见数据集上的有效性得到验证,为工业异常检测领域提供了新的思路和可能性。



















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











