







论文:REASONING EFFORT AND PROBLEM COMPLEXITY: A SCALING ANALYSIS IN LLMS
- 核心目标是什么?
问 1:这篇研究最核心的目标是什么?它想解决什么问题?
答 1:研究者想探究当 Tents Puzzle 的网格规模不断变大时,大模型的推理努力(例如生成多少推理 token)和成功率是如何随之变化的。
- 为什么选择 Tents Puzzle 作为研究对象?
问 2:研究者为什么选用 Tents Puzzle 这种谜题来研究?
答 2:因为 Tents Puzzle:
-
可以“无限扩大”网格尺寸,便于测试不同规模的难度;
-
有已知的线性时间算法,因此理论上不会因为问题本身是 NP 难度而导致无法衡量;
-
规则清晰,能集中考验模型的逻辑推理和可扩展性。
- Tents Puzzle 具体的规则是怎样的?
网站:https://www.chiark.greenend.org.uk/~sgtatham/puzzles/js/tents.html
问 3:Tents Puzzle 的关键规则可以简单概括吗?
答 3:主要规则包括:
-
网格里有一些树,必须放置与树等量的帐篷;
-
每个帐篷要与一棵树相邻(上下左右相邻,不含对角);
-
两个帐篷彼此之间不得相邻(包括对角);
-
每行、每列最终有多少帐篷都要符合给定的数字限制。
- 推理努力(Reasoning Effort)指的是什么?怎么衡量?
问 4:文中说的“推理努力”具体指什么,如何量化?
答 4:他们用 LLM 输出的“token 总数”来衡量。
问题规模越大,若模型要保持高成功率,通常需要生成更多推理步骤或更长的思考语句。
- 为什么要观察推理努力的“线性增长”?
问 5:他们为什么关心推理努力是否线性增长,而不是别的类型(比如指数级)?
答 5:Tents Puzzle 本身有线性时间解法,按理说随着网格面积增大,人工或算法的逻辑推理步骤可能也呈线性或接近线性增长。
如果发现 LLM 的推理努力在问题变大时无规律地暴增或直接崩溃,就说明它的推理过程在复杂度扩大时存在不足或局限。
- 结果显示了什么?(例如出现了什么转折或瓶颈?)
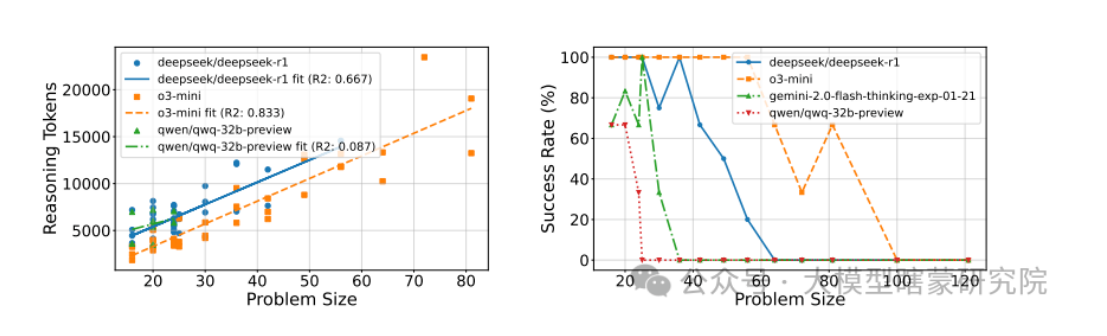
问 6:他们的实验结果体现出哪些有趣现象?
答 6:对一些模型,当问题规模变大时,确实推理 token 呈线性上升;
但是当超过某个临界大小后,模型可能“失败”或“思考量”突然下降,说明模型在复杂度很高时失去合理的推理能力;
不同模型在能成功解决的最大网格规模上有差异:有的模型在 10×10 或 20×20 还能解,有的在 25×25 就失败。
- 哪些模型表现最好?为什么?
问 7:根据上文,哪个模型在大规模 Tents Puzzle 上表现最好?简单分析原因。
答 7:
-
o3-mini 成功率最高,一定程度上能解决更大规模的谜题;
-
DeepSeek R1 次之;
-
Qwen/QwQ-32B-Preview 在大规模上性能明显下降;
之所以 o3-mini 更好,可能和其训练策略(在推理阶段有更多思考token分配,或有更好的链式思考/树式思考等方法)有关。
思维链 不是正途,推理成本太高 + 推理努力有天花板 + 过多干扰反而倒退。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









