









强化学习共同框架
在这个狗狗学习握手的场景中,强化学习的各个要素可以这样理解:
-
状态s(state): 狗狗所处的环境状况,比如主人伸出手掌的姿势、狗狗自身的姿势、周围的环境等。状态s描述了狗狗在特定时刻所感知到的环境信息。
-
动作a(action): 狗狗可以采取的行为,如抬起前爪、将爪子放在主人手上、坐下、站立等。这些是狗狗能够主动执行的所有可能行为。
-
奖励r(reward): 狗狗执行动作后获得的反馈。当狗狗正确抬爪握手时,获得骨头作为正向奖励;不握手则没有奖励;如果咬主人,则会受到负面惩罚。
-
策略π(policy): 狗狗在特定状态下选择动作的行为准则。比如,当主人伸出手时(状态s),狗狗应该抬起前爪放在主人手上(动作a)的概率很高。随着学习的进行,狗狗会优化这个策略,使得在正确的时机做出正确的动作。
-
状态值函数V(s): 表示狗狗处于状态s时,按照当前策略行动能够获得的长期期望奖励。例如,当主人伸手示意时(特定状态s),狗狗预期能获得的总奖励值。如果这个状态通常会引导到获得骨头的结果,那么这个状态的V值就会很高。
-
状态-动作值函数Q(s,a): 表示狗狗在状态s下执行动作a,然后按照当前策略行动所能获得的长期期望奖励。比如,当主人伸手(状态s)时,狗狗选择抬爪(动作a)的Q值会很高,因为这通常能获得骨头奖励;而选择咬人(另一个动作)的Q值会很低,因为会导致惩罚。
Agent(狗子)根据状态选择,并执行最优动作 - 拿最高奖励。
想象一下,我们开始训练一只名叫小黑的狗狗学习握手。
刚开始时,小黑对于什么行为会带来奖励一无所知,它处于初始状态s₀(主人伸出手)。
此时,小黑的策略π还很随机,它可能尝试各种动作a——坐下、转圈、抬爪等。
每种动作a都有其对应的状态-动作值Q(s₀,a),但由于小黑还没有学习经验,这些Q值初始都很低或相近。
当小黑随机尝试抬起前爪放在主人手上这个动作时,主人立即给予骨头奖励r。
通过这次经验,小黑更新了状态s₀的价值V(s₀),认识到这是一个有价值的状态。
同时,它也更新了在状态s₀下执行"抬爪"这个动作a的Q值Q(s₀,抬爪)。
随着训练的继续,小黑会不断调整其策略π,逐渐增加在状态s₀下选择"抬爪"动作的概率,因为这个动作的预期回报很高。
而如果小黑尝试了咬主人这个动作,会受到惩罚,导致这个动作的Q值大幅降低,使得小黑在未来的策略中减少选择这种行为的可能性。
经过多次训练后,小黑学会了最优策略π*:当主人伸手时(状态s),一定要抬爪放在主人手上(动作a),因为这个状态-动作组合有最高的Q值,能带来最大的期望奖励。
此时,小黑已经成功掌握了"握手"这个技能,实现了学习目标。
在整个过程中,小黑并不知道环境(主人的训练规则)是如何运作的,只能通过不断尝试不同动作,观察获得的奖励,进而优化自己的行为策略,这正是强化学习的核心思想。
主要的强化学习算法家族
- 基于值函数的方法
:如Q-learning和SARSA,它们专注于学习Q(s,a)值
- 基于策略的方法
:如策略梯度法,直接优化策略π
- 演员-评论家方法
:结合了以上两种方法的优点
- 基于模型的方法
:尝试学习环境的模型来辅助决策
Q-learning 算法:狗狗学习握手
小黑是一只正在学习握手的狗狗。Q-learning 算法的训练过程是这样的:
-
初始阶段:小黑对于主人伸手这个状态下应该做什么完全不知道。它有一个空白的"记忆表格"(Q表),记录每个状态下每个动作的价值。
-
探索与尝试:小黑开始随机尝试各种动作 - 有时抬爪,有时坐下,有时转圈。
-
更新Q值:当小黑尝试抬爪并获得骨头奖励时,它在Q表中记录:"主人伸手状态下,抬爪动作的Q值很高"。如果咬主人并受到惩罚,则记录这个动作的Q值很低。
-
贪心选择与探索平衡:随着训练进行,小黑大部分时间会选择Q值最高的动作(抬爪),但偶尔也会尝试其他动作,看看是否有更好的选择。
-
收敛到最优策略:最终,小黑的Q表会清晰地显示在主人伸手状态下,抬爪的Q值最高,它就会稳定地选择这个动作。
策略梯度法:狗狗学习握手
同样是小黑学习握手,但策略梯度法不同:
-
直接学习策略:小黑不记录Q值表格,而是直接学习"看到主人伸手→抬爪"这样的策略映射。
-
概率分布:小黑的策略是一个概率分布 - "主人伸手时,80%概率抬爪,15%概率坐下,5%概率转圈"。
-
根据奖励调整概率:当抬爪获得骨头奖励后,小黑提高抬爪的概率;当其他动作没有奖励或受到惩罚时,降低这些动作的概率。
-
梯度上升:小黑按照"如果这个动作带来好结果,就增加它的概率"的原则来调整自己的行为倾向。
-
收敛到最优策略:最终,小黑会形成"主人伸手时,99%概率抬爪"的策略,完成训练目标。
演员-评论家算法:狗狗学习握手
小黑的大脑有两个部分工作:
-
评论家部分:评估状态的价值(V值),告诉小黑"主人伸手这个状态很有价值,可能会得到骨头"。
-
演员部分:决定具体动作,"既然主人伸手是有价值的状态,我应该选择抬爪这个动作"。
-
协同工作:评论家帮助小黑判断自己处于好的还是坏的状态,演员则负责在这些状态下选择合适的动作。
-
同步学习:小黑的评论家部分学习判断状态价值,演员部分学习在有价值的状态下选择最优动作。
-
共同进步:随着训练进行,评论家越来越准确地评估状态价值,演员越来越擅长选择好的动作,最终小黑稳定地在主人伸手时抬爪握手。
这些不同算法虽然侧重点和实现方式不同,但都在处理同样的核心概念 - 状态、动作、奖励、策略等,只是组织和学习这些概念的方式有所不同,就像不同的教学方法可以教会小黑同样的握手技能。
蒙特卡洛
蒙特卡洛方法的核心特点是通过完整经历(整个训练回合)来学习,而不是像其他方法那样逐步更新。
让我们看看这如何应用于训练小黑学习握手:
-
基于完整回合的学习:与Q-learning不同,蒙特卡洛方法要求小黑完成整个训练回合(或"情节"episode)后才会更新它的价值认知。
-
训练回合设计:一个完整回合可能是这样的:
-
开始:主人伸出手(初始状态)
-
小黑做出各种动作(抬爪、坐下等)
-
主人给予相应反馈(奖励或惩罚)
-
结束:主人收回手,训练回合结束
-
-
价值估计方式:蒙特卡洛方法直接通过多次训练回合的实际体验来估计各状态-动作组合的价值:
-
第一天训练:小黑在"主人伸手"状态下尝试"抬爪",最终获得骨头,记录这次体验
-
第二天训练:再次尝试"抬爪",再次获得骨头,记录下来
-
第三天训练:尝试"坐下",没有获得奖励,也记录下来
-
-
平均回报计算:小黑会计算每个状态-动作组合的平均回报:
-
"主人伸手+抬爪"组合在多次训练中平均获得+10的奖励
-
"主人伸手+坐下"组合平均获得0的奖励
-
-
探索与利用平衡:蒙特卡洛方法通常采用ε-贪心策略,即:
-
大部分时间(如90%)小黑选择当前认为最有价值的动作(抬爪)
-
少部分时间(如10%)随机尝试其他动作,确保充分探索所有可能性
-
-
策略改进:随着训练回合的增加,小黑逐渐形成更准确的状态-动作价值估计,并据此改进策略:
-
发现"主人伸手+抬爪"的平均回报最高
-
逐渐增加在"主人伸手"状态下选择"抬爪"的概率
-
-
没有自举(bootstrapping):与动态规划和时序差分方法不同,蒙特卡洛方法不依赖于估计值来更新估计值(不自举),而是完全基于实际经验。小黑不会基于对未来状态的预测来调整当前动作的价值,而是等待看到整个训练回合的实际结果。
实际训练过程可能是这样的:
小黑经历多个完整的训练回合,每个回合都从主人伸手开始,到主人收回手结束。
在每个回合中,小黑尝试不同的动作,并记录下这些动作最终带来的总奖励。
经过许多回合后,小黑会发现在主人伸手时选择抬爪动作,平均能获得最高的回报,于是它的策略会逐渐偏向于在主人伸手时选择抬爪这个动作。
这种方法的优点是概念简单直观,就像小黑凭借完整的训练经验来学习,而不是尝试预测中间步骤的价值。
缺点是需要等待整个回合结束才能学习,可能效率较低,特别是对于较长的训练回合。
时序差分
时序差分方法的核心特点是结合了蒙特卡洛方法的实际体验和动态规划的自举(bootstrapping)特性。
它不等待整个训练回合结束,而是在每一步之后就立即学习。应用于训练小黑学习握手:
-
逐步学习:时序差分方法的关键在于小黑不需要等待整个训练回合结束,而是每完成一个动作并观察到即时奖励和下一个状态后,就可以立即更新它的价值估计。
-
学习过程:训练可能是这样的:
-
主人伸出手(状态s)
-
小黑选择抬爪(动作a)
-
主人给予骨头奖励(奖励r)
-
主人继续维持伸手姿势(新状态s')
-
小黑立即更新它对"主人伸手+抬爪"这个组合的价值估计
-
-
TD误差:小黑会计算TD误差,即实际观察到的结果与预期的差异:
-
预期:小黑当前估计"主人伸手+抬爪"的价值是5分
-
实际观察:得到骨头(10分)和新状态(主人继续伸手)的价值
-
TD误差 = 实际观察 - 预期 = (10 + γ×新状态价值) - 5
-
-
价值更新公式:小黑使用TD误差来更新估计:
-
新估计 = 旧估计 + 学习率×TD误差
-
例如:新估计 = 5 + 0.1×(实际-5)
-
-
SARSA与Q-learning:时序差分家族有多种算法,主要区别在于如何选择和评估下一个动作:
- SARSA(在策略学习)
:小黑考虑它实际会选择的下一个动作来更新当前状态-动作价值
- Q-learning(离策略学习)
:小黑总是考虑下一状态中最优的动作来更新,不管它实际会选什么
- SARSA(在策略学习)
SARSA训练狗狗握手的具体过程:
-
主人伸手(状态s)
-
小黑选择抬爪(动作a),这个选择基于当前的策略(可能是ε-贪心)
-
小黑获得骨头奖励(奖励r)
-
主人继续伸手(新状态s')
-
小黑考虑下一个动作a'(比如继续保持爪子放在主人手上)
-
小黑更新Q值:Q(s,a) ← Q(s,a) + α[r + γQ(s',a') - Q(s,a)]
-
状态s变为s',动作a变为a',进入下一个时间步
Q-learning训练狗狗握手的具体过程:
-
主人伸手(状态s)
-
小黑选择抬爪(动作a)
-
小黑获得骨头奖励(奖励r)
-
主人继续伸手(新状态s')
-
小黑更新Q值:Q(s,a) ← Q(s,a) + α[r + γ max_a' Q(s',a') - Q(s,a)]
-
注意这里使用的是s'状态下最优动作的价值,而不是小黑实际会选的动作
-
-
状态变为s',选择新动作a'(可能基于ε-贪心策略),进入下一个时间步
时序差分方法的优势在于它结合了蒙特卡洛方法和动态规划的优点:既使用实际体验来学习(如蒙特卡洛),又不需要等待整个回合结束就能更新(如动态规划)。
对小黑来说,它可以在每次尝试握手后立即调整自己的策略,而不必等到一天的训练结束,大大提高了学习效率。
在实际应用中,时序差分方法通常比蒙特卡洛方法更受欢迎,因为它能够更快地学习和适应,特别是在环境变化较快或训练回合很长的情况下。
马尔科夫决策模型
假设我们正在训练小黑学习握手,从MDP的角度看这个过程:
1. 状态集合S: 所有可能的状态,如"主人站立伸手"、"主人蹲下伸手"、"主人没有伸手"等。
2. 动作集合A: 小黑可以采取的所有动作,如"抬右前爪"、"抬左前爪"、"坐下"、"站立"等。
3. 转移概率P(s'|s,a): 描述小黑在状态s下执行动作a后转移到新状态s'的概率。例如,小黑在"主人伸手"状态下执行"抬爪"动作后,可能95%的概率停留在"主人伸手"状态(因为主人等待握手完成),5%的概率转换到"主人没有伸手"状态(因为主人收回了手)。
4. 奖励函数R(s,a,s'): 定义小黑从状态s执行动作a并转移到状态s'时获得的奖励。例如:
- 从"主人伸手"→"抬爪"→"主人伸手" 奖励+10(得到骨头)
- 从"主人伸手"→"咬人"→"主人缩手" 奖励-20(受到惩罚)
- 从"主人伸手"→"坐下"→"主人伸手" 奖励0(无反应)
5. 折扣因子γ: 表示小黑对未来奖励的重视程度。例如γ=0.9意味着现在的骨头比未来的骨头重要,但未来的奖励仍然有很大影响。
6. 马尔科夫性质: MDP的关键假设是"无记忆性"—小黑下一个状态只取决于当前状态和动作,而不依赖于过去的历史。这意味着小黑不需要记住"十分钟前主人做了什么",只需要关注当前主人是否伸手。

探索
狗狗训练中的表现:
- 小黑尝试新的、未知的动作,如尝试抬左爪、右爪、坐下、转圈等
- 即使某些动作之前没有获得奖励,小黑依然会偶尔尝试它们
- 主人可能会鼓励狗狗尝试不同动作,增加它的行为多样性
目的:
- 发现可能带来更高奖励的新行为
- 防止狗狗只学会一种简单但不是最优的行为
- 探索环境中所有可能的状态-动作组合
利用(Exploitation)
狗狗训练中的表现:
- 小黑重复选择那些已知能带来骨头奖励的动作,如"主人伸手时抬右爪"
- 狗狗倾向于选择过去经验中证明有效的行为
- 狗狗依赖已有的知识来获取确定的奖励
目的:
- 最大化当前已知的回报
- 巩固和优化已学会的有效行为
- 在训练后期获得稳定表现
探索与利用的平衡
在狗狗训练中的具体例子:
1. ε-贪心策略: 小黑大部分时间(例如90%)选择Q值最高的动作(利用),但偶尔(10%)随机选择一个动作(探索)
- 例如:小黑90%的时间在主人伸手时抬爪,但偶尔也会尝试坐下或转圈
2. 退火探索: 训练初期小黑大量探索(尝试各种动作),随着训练进行逐渐减少探索增加利用
- 例如:刚开始训练时,小黑几乎随机尝试各种行为;训练后期,它主要选择已经学会的"握手"动作
3. 好奇心驱动: 小黑对不确定性高的状态-动作组合更感兴趣
- 例如:如果小黑不确定"主人蹲下伸手"这个新状态下应该做什么,会对这个状态产生"好奇心",主动探索
各算法的探索-利用策略
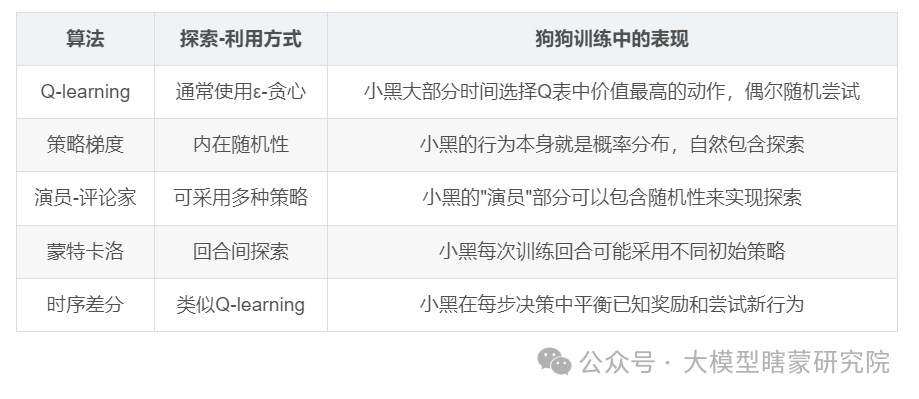
探索与利用的平衡是强化学习成功的关键——如果小黑只探索(总是尝试新动作),它可能永远学不会稳定的技能;
如果只利用(总是重复同一动作),它可能永远找不到最优行为。
好的训练需要在二者之间取得适当平衡,就像好的狗狗训练师会既鼓励狗狗尝试新行为,也强化已学会的正确行为。

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









