







MapRE: An Effective Semantic Mapping Approach for Low-resource Relation Extraction
1 任务介绍
关系抽取(Relation Extraction, RE)是自然语言处理中的一项基本任务,它旨在发现一个句子中两个实体之间的正确关系。
RE问题通常被视为在大规模标注数据上的有监督分类问题。它的缺点是随着关系实例数量的减少,模型性能急剧下降。
RE问题经常存在数据不足问题,以往的方法是远程监督(distant supervision)将已有的知识库对应到丰富的非结构化文本数据中,从而生成大量的训练数据,以便训练出一个效果不错的关系抽取器。可是数据存在大量噪声的缺点,当两个实体有多种关系或在某个文本中没有关系时,会对关系抽取器产生影响。
1.1 Few-shot RE
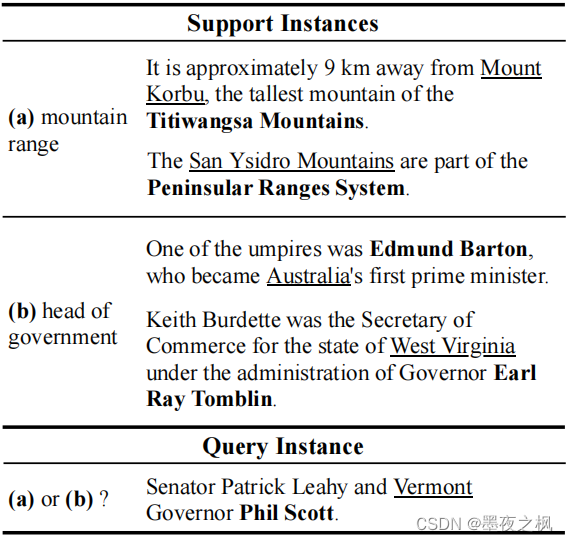
少样本关系抽取任务是一种专注于通过学习少量带注释的实例来识别新的实例。上图是一个2路2 shot关系抽取任务,其中2路表示支持实例中一共有两种关系类型,而2 shot表示每种关系均有两个样例作为支撑。对于N-way K-shot问题,Support实例包含N个关系,每个关系有K个样本,查询集包含Q个样本,每个样本属于 N 个关系之一。
支持实例中(a)中的关系类型是山脉,它的头尾实体也是围绕着山脉展开的,第一个样例中的头实体科尔布山是尾实体蒂迪旺沙山脉的一部分,同理第二个样例中头实体圣伊西德罗山也是尾实体半岛山脉系统的一部分。然后,(b)中关系类型是政府首脑,第一个样例{其中一个裁判是埃德蒙·巴顿,他成为了澳大利亚的第一任首相。},它的头实体是澳大利亚,尾实体是埃德蒙巴顿;第二个样例{基思·伯德特是厄尔·雷·汤布林州长管理下的西弗吉尼亚州的商务部长},头实体为西弗吉尼亚州,尾实体厄尔雷汤布林。
而查询实例{参议员帕特里克·莱希和佛蒙特州州长菲尔·斯科特。},它的头尾实体分别是佛蒙特州和菲尔斯科特,实验目的是给出这样一个两路两样本的支持实例训练一个能识别关系选自支持实例的模型。
1.2 Zero-shot Learning
少样本学习的一个极端条件是零样本学习,没有对候选的关系标签提供实例。
- 方法:将输入(Query实例)与预定义的标签(关系标签)矢量匹配,其中假设标签向量与support实例的representation起着同样的作用。
- 标签向量通常通过预训练的word embedding获得,并将直接用于预测。

1.3 MapRE: label-agnostic & label-aware models
针对少样本和零样本关系抽取问题,作者提出了MapRE模型,结合标签不可知和标签感知这两个模型。
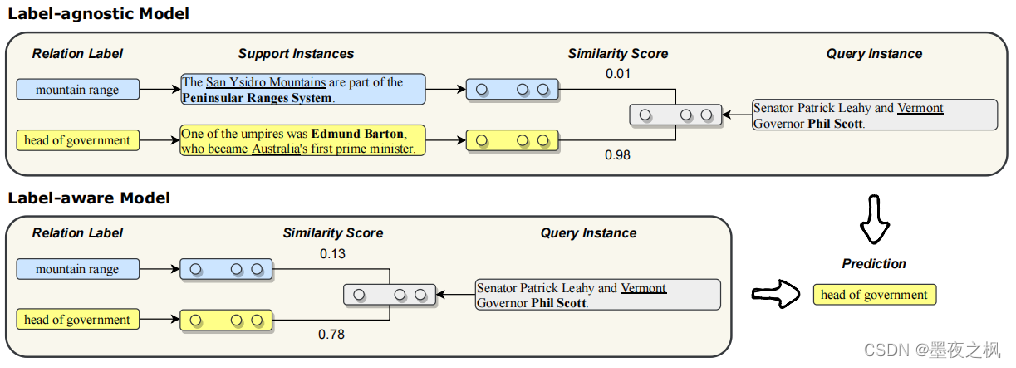
label-agnostic标签不可知模型,主要是比较在嵌入空间中的Support实例和Qurey实例之间的相似性,对于每一种关系类型它至少需要一个支持实例,也就是说标签不可知模型不适用于零样本场景。图中所示,每种关系标签都需要计算它的支持实例的表示,同时计算查询实例的表示,最后计算它的相似性分数。
label-aware标签感知模型,直接计算关系标签的表示,使其与查询实例的表示直接计算相似性分数。标签感知模型可以从关系语义知识中获取更多的提示进行预测,相比于标签不可知模型优势在于,随着关系数量的增加和支持实例的减少,它能得到更多的语义信息,在极低资源的情况下label-aware更有价值。
作者提出的语义映射框架MapRE,同时利用label-agnostic和label-aware进行关系抽取,然后得到最终的预测结构。标签不可知模型使得具有相同关系的实例在语义空间中接近,而标签感知模型使得实例在标签向量中接近它首尾实体的关系。
2 语义映射预训练
2.1 预训练低资源RE
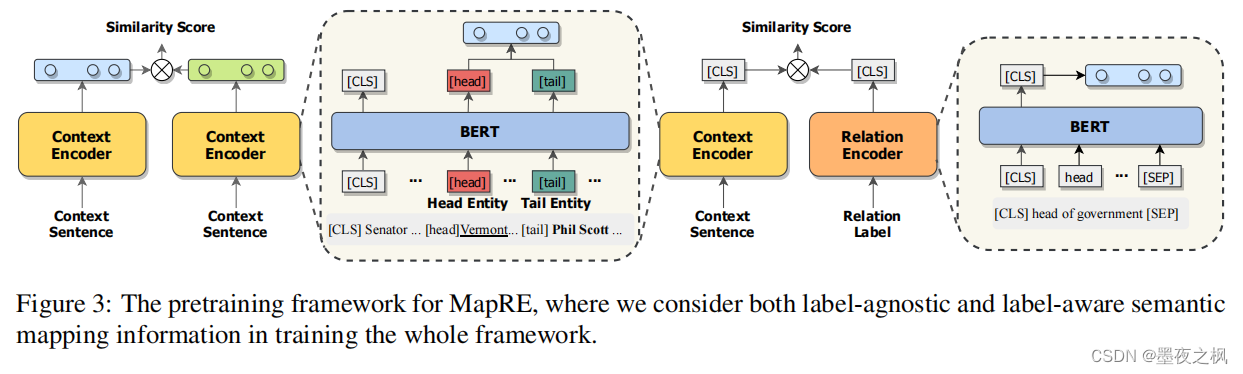
对于低资源RE问题,需要计算两种类型的匹配在语义空间中接近:首先是label-agnostic标签不可知模型,对于具有相同关系的上下文语句应该就有相似的表示;然后是label-aware标签感知模型,上下文语句和对应的关系标签在语义空间中应该更加接近。
2.2 pretraining MapRE:label-agnostic
输入x=(c,pℎ,pt),其中c=[c0,…,cm],头实体pℎ,尾实体pt。设xA,xB是具有相同关系的上下文语句,fCON表示句子Context Encoder
- 目标:求具有相同关系的上下文语句之间的语义差距d(fCON(x_A),fCON(x_B))
2.3 pretraining MapRE:label-aware
对于一个输入x=(c,pℎ,pt),其首尾实体关系表示为r。fREL表示为Relation Encoder
- 目标:求上下文语句与其关系标签之间的语义差距d(fCON(x),fREL®)
2.4 pretraining MapRE
最后是这两个模型的损失函数:
- u=fCON(x)[[ℎead],[tail]] 为标签不可知模型的表示,这里的[head]和[tail]指的是在标签不可知模型中主要是学习头尾实体的表示;
- w=fCON(x)[CLS] 为标签感知的表示,[CLS]指的是此处主要学习原始文本的表示;
- v=fREL®[CLS] 指的是学习关系的表示。
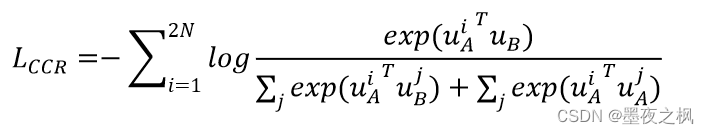
L_CCR指的是样本表示之间的损失,分子上是一对具有相同关系的上下文语句的乘积,也称之为是正例;分母上则是所有负例乘积的总和。

L_CRR指的是样本表示和标签之间的损失,同理分子上是上下文语句表示和它对应的关系标签表示之间的乘积,而分母上则是上下文语句表示和所有不是它对应的关系标签表示之间的乘积。
3 监督性关系抽取
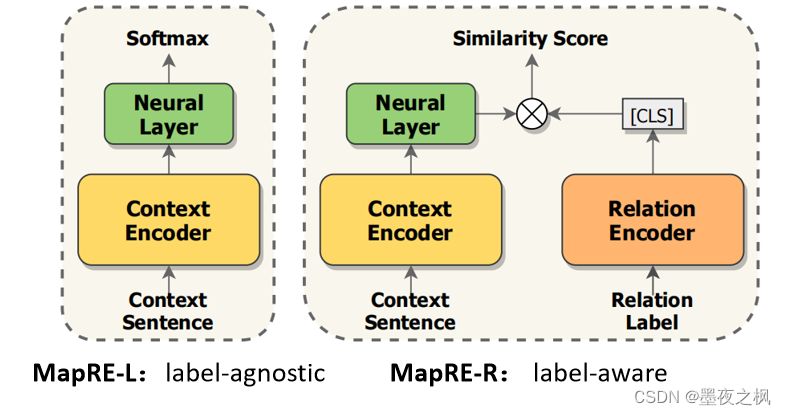
- MapRE-L:使用全连通层来预测所有关系上的概率分布
- MapRE-R:从Context Encoder和Relation Encoder中获得的上下文representation和relation representation计算相似性。
监督性关系抽取的一种方法是,输入的上下文语句在经过预训练之后得到一个上下文表示,然后使用全连通层来预测所有关系上的概率分布;另一种方法是上下文语句和关系标签之间计算相似性。(图绿色部分)这个全连接层的目的是调整维度,方便计算用的。
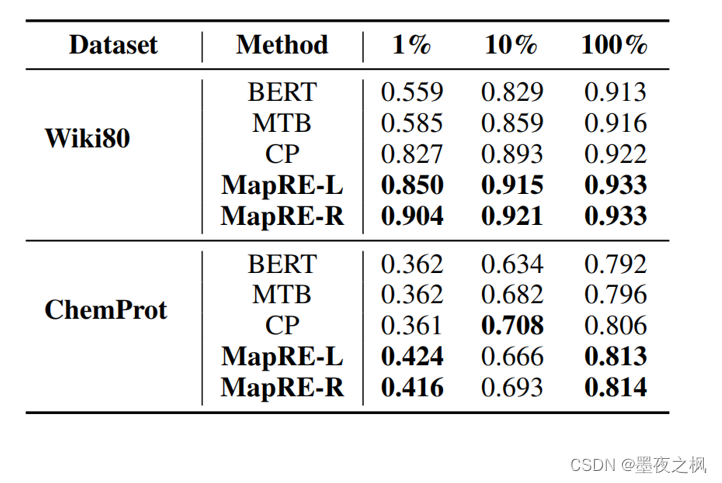
表中显示出了提出的两种监督性关系抽取实验结果,与三种baseline相比,MapRE有很强的性能,尤其是在低资源的情况下。而且在预训练和微调中使用标签感知信息有助于提高低资源监督RE任务的模型性能。
4 Few & Zero-shot关系抽取
最后是少样本、零样本情况下的关系抽取。通过比较label-agnostic映射信息(查询上下文表示和支持上下文表示之间的相似性)和label-aware映射信息(查询label-aware表示和关系标签表示之间的语义差距)对查询实例进行预测。其实就是将两个模型融合到一起使用。
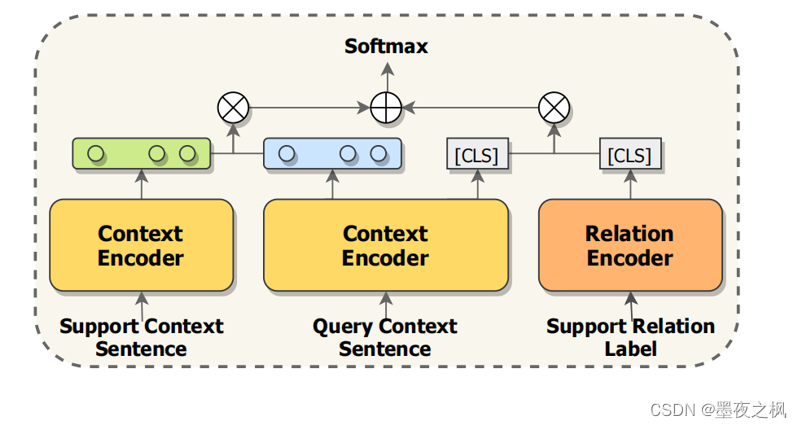
在两个数据集上评估提出的方法:FewRel和NYT-25。

在所有的实验设置下,由于在预训练和微调中均考虑了support样本句子和关系标签信息,提供了稳定的性能表现,并大幅优于一系列baseline方法。结果证明了MapRE框架的有效性,并表明了关系抽取中关系标签语义映射信息的重要性。
5 总结
提出了一种同时考虑标签信息和样本信息的关系抽取模型——MapRE。
实验结果表明,MapRE模型对监督性关系抽取、少样本关系抽取和零样本关系抽取任务中展示了出色的表现。
















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











