







前言
近期导师让做的总结报告,将看的该思想方法的论文做了回顾,顺道上传了(ps:涉及到的Nomalizing Flow的知识主要来自参考的前两篇博客)。
1.异常检测的概述
1.1相关背景
工业缺陷的检测与定位一直是工程实践的热点,快速准确的检测、定位能对产品设计的考量、生产线的实时调整以及生产完成后的评价分析带来较高的性能提升。但随着工艺流程的不断优化,工艺设备等的不断升级,工业产品上缺陷出现的频率越来越小,导致缺陷数据的搜集有了一定困难,即使是搜集到的缺陷样本,缺陷的细微性、缺陷样本与正常样本的相似性以及正常样本存在的噪声都会干扰到缺陷的检测、定位。
异常检测是计算视觉里新兴的研究领域,它包含检测和定位两种功能,检测是图像的分类,区分正常异常样本,定位是图像像素的分割,定位异常区域。而针对缺陷样本的难以获得,难以检测,异常检测的发展又为此提供了解决方案,即采用半监督的方式对网络只输入正常图像进行训练,测试阶段再同时出现正常和异常图像以评价网络性能。
1.2应用方法
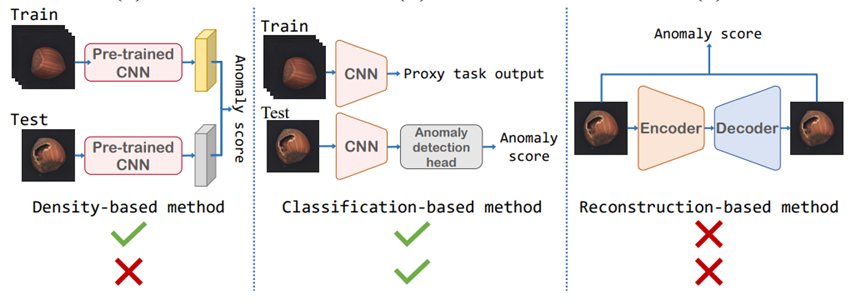
图1-1三类方法结构图
现有主流的异常检测方法主要分为基于分类的、基于重建的、基于密度表示的(Liang et al., 2022),三类模型的结构框架如上图1-1所示。其中,基于分类的方法里,利用自监督学习的网络是主要思想,主要采用代理任务,通过代理任务与异常之间的差异判断、定位。基于重建的方法是基于网络在图像边缘及纹理区域有较高的重建误差,训练时的网络经过大量正常图像的输入能够很好的重建正常图像,而对异常图输入时,网络并不敏感,从而产生较大的重构误差,达到对图像的检测,对区域的定位效果。基于密度表示的方法主要用到了预训练网络来提取有用的特征向量,训练时通过正常图像形成正常分布,推理时通过计算异常分布与正常分布之间的距离来区分定位异常。近两年采用这种思想的网络都实现的较为领先的结果。
在基于密度表示的方法里,标准化流模型是其中的佼佼者,后续的章节将对其在异常检测领域的应用及有关原理做相应介绍。
2.标准化流模型
2.1异常检测领域内的应用概述
在近一两年发表的论文里,DifferNet网络(Marco Rudolph, Wandt, & Rosenhahn, 2021)是基于深度学习的图像特征密度估计方法,将标准化流引入异常检测领域,但该网络由于只利用生成的最后特征层,缺少重要的上下文信息和语义信息,通过数据增强的方法解决缺失的问题,但只能用于图像级检测,而无法进行像素级定位。相比于DifferNet网络,CS-Flow网络(M. Rudolph, Wehrbein, Rosenhahn, & Wandt, 2021)则是引入完全卷积,利用了多尺度的特征,对检测和定位都能实现较好的效果,Fastflow(Yu et al., 2021)网络将卷积核(3*3)与卷积核(1*1)交替引入,并且能够契合不同的特征提取器(CNN,ViT)以作为嵌入模块使用,提高网络模型适用范围。
可以看出,异常检测领域内,基于标准化流模型的升级方向是提高检测与定位性能的同时,又使其计算成本更低,适用范围更广泛。要在领域内发展利用好该思想,还是要对其构成原理,优势不足做一定的理解。
2.2模型的搭建
2.2.1 基本思路
标准化流(Normalizing Flow)是一种生成模型,与对抗生成模型GAN,自编码器模型VAE可以归为一类,而生成模型的本质是用一个已知的概率模型来拟合所给的数据样本形成概率分布,这个分布是带参数θ的分布 qθ(x)。神经网络更像是“万能函数拟合器”。由于概率分布有“非负”和“归一化”的要求,神经网络能拟合的只有离散型的分布和连续型的高斯分布。图像属于离散型的分布,将图像用离散型的分布描述是自回归流PixelRNN的思路,由于离散型的分布计算时无法并行,导致计算量特别大,所以将图像描述转化为拟合连续型的高斯分布是另一种标准化流Normalizing Flow的研究思路。
各分量独立的连续型高斯分布是不够用的,需要通过积分构建更多的分布,构建的公式如下:
![]()
其中,q(x)是标准高斯分布,q(x|z)是条件高斯分布或狄拉克分布。分布有了,优化靠的是最大似然,如下式所示:
![]()
表达分布的问题在于q(x)是积分形式的,这是不确定的因素,可能算不出来。VAE模型选择的是优化一个更强的上界,但只能得到一个近似模型;GAN模型则通过一个交替训练方法绕开困难,保持模型精确性,但也存在瑕疵;Flow提供另外的一种思路:直接将积分算出来。
Flow模型选择 q(x|z) 为狄拉克分布 δ(x−g(z)),而且 g(z) 必须是可逆的,以保证Flow模型的双向映射性,即:
![]()
狄拉克分布的公式为:
![]()
将z分布转化为x分布不只需要将z替换为f(x),还需要的是雅克比矩阵绝对值,如下:
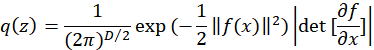
对f的要求有两个,可逆且对应的雅克比矩阵易计算。这样一旦训练完成,我们就通过逆得到了生成模型:
![]()
2.2.2典型模型
通过flow模型的基本思路,针对其特点难点,三种典型模型涵盖了其搭建的主流架构,即:NICE(Dinh, Krueger, & Bengio, 2014)、RealNVP(Dinh, Sohl-Dickstein, & Bengio, 2016)、Glow(Kingma & Dhariwal, 2018),其中流型学习的开山之作为NICE模型,RealNVP和Glow为该模型的改进升级。
让矩阵易于计算用到的方法是将雅克比矩阵转换为三角阵,将D维向量分为两部分x1,x2,如下式所示:
![]()
![]()
其中 x1,x2 是 x 的某种划分,m 是 x1 的任意函数。h为转化完成后的向量,将 x转化为h的层称为加性耦合层,而将x分为x1,x2的层称为分块耦合层。这种由分块耦合层到加性耦合层的方式既满足计算简化,又满足可逆的要求,将多个模块组合到一起,也就是Flow的由来,构成如下图2-1所示结构:

图2-1Flow流块的连续耦合
由公式可以看出,h1和x1之间仍是恒等变换,为增加非线性表达能力,使信息充分混合,使用交叉耦合,结构如下图所示。
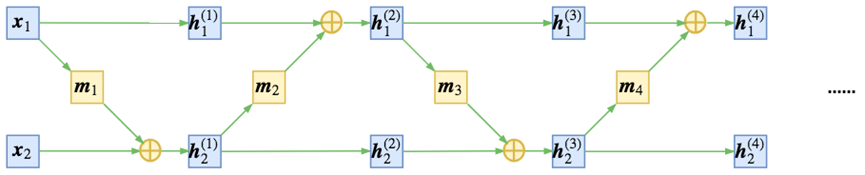
图2-2Flow流块的交叉耦合
当一些维度并不是很需要的时候,NICE模型还加入了尺度变换层,将先验分布方差作为训练参数,给维度分配权重,以实现降维。
NICE模型全称为:Non-linear Independent Components Estimation,也就是非线性独立成分估计,其中独立是也就是经由NICE模型形成的特征是解耦的,独立的,这也是该模型生成特征的最大特点。
RealNVP模型将耦合层及尺度变换层加以改进,同时还能提供强大的正则效果使生成质量进一步提升,耦合层的改进中,模型将耦合层引入了卷积层。
在耦合层的改进里,公式体现如下,这里除了NICE模型的加性耦合,还加入乘性耦合。一起形成一个仿射耦合层。
![]()
![]()
RealNVP全称:real-valued non-volume preserving,即实值非体积保持,加性耦合层的行列式值为1,体积是保持住的(行列式值=体积),而RealNVP行列式值是变化的,所以名称由此得来。除了耦合层的升级,模型对流块的信息混合也做了改进,结构如图2-2所示,是将每个流块的结束处h1,h2的向量做了随机排序。

图2-3Flow流块的随机耦合
模型还引入卷积块,减小参数,增加并行量,但卷积操作由于只在通道轴上进行操作,并不会破坏像素间相关性,所以s/t函数可以用卷积。RealNVP模型还进行通道对半分,棋盘分以及squeeze增加维度等方法,可以使信息充分混合。
当然,尺度变化层也有了修改,但提出的新结构改变了特征不同分量的地位,使得信息地位不对等,即原NICE模型是标准的正态分布,而新结构变成了组合式的条件分布,这个改变是值得商榷的地方。
RealNVP的模型发表使得Flow的一般框架以此形成。Glow模型沿用RealNVP框架,对部分内容进行了修改,比如引入了可逆1x1卷积来代替排序层,还做了尺度变化层的升级。
3.总结
标准化流(Normalizing Flow)原用于表达一维数据的分布,随着卷积块结构的引入,使得二维空间位置信息在提取过程中得以保存,模型逐渐成为异常检测领域使用密度估计方法的代表,其出色的分布表达能力,信息保存以及训练过程中的双向映射能力都使得以该思想为基础的模型取得不错的检测定位效果。
但该思想应用的过程中,还是会用到预训练网络以及存在模型可解释性不足的问题,使用预训练网络会导致对真实场景的实用性不足,而可解释的不足也会让图片中某一异常区域无法定位到,并且由于维度降低有限性,也会导致模型运算速度受到限制。所以如何充分利用标准化流的优势,改进其劣势是搭建模型时要考虑的问题,这样也得以保证该思想在领域内不断焕发新的活力。
参考文献
Dinh, L., Krueger, D., & Bengio, Y. (2014). Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516.
Dinh, L., Sohl-Dickstein, J., & Bengio, S. (2016). Density estimation using real nvp. arXiv preprint arXiv:1605.08803.
Kingma, D. P., & Dhariwal, P. (2018). Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31.
Liang, Y., Zhang, J., Zhao, S., Wu, R., Liu, Y., & Pan, S. (2022). Omni-frequency Channel-selection Representations for Unsupervised Anomaly Detection.
Rudolph, M., Wandt, B., & Rosenhahn, B. (2021). Same same but differnet: Semi-supervised defect detection with normalizing flows. Paper presented at the Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision.
Rudolph, M., Wehrbein, T., Rosenhahn, B., & Wandt, B. (2021). Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection.
Yu, J., Zheng, Y., Wang, X., Li, W., Wu, Y., Zhao, R., & Wu, L. (2021). FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows. arXiv preprint arXiv:2111.07677.
参考
NICE:细水长flow之NICE:流模型的基本概念与实现_PaperWeekly的博客-CSDN博客
RealNVP/Glow:RealNVP与Glow:流模型的传承与升华_PaperWeekly的博客-CSDN博客
细水长flow之RealNVP与Glow:流模型的传承与升华 - 科学空间|Scientific Spaces

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









