







 该博客是《Grokking DRL》第11 - 12章笔记。第11章介绍了Policy Gradient和Actor - Critic等on - policy算法,分析了算法优缺点及改进方法。第12章解决复杂环境RL问题,介绍DDPG、TD3、SAC、PPO等算法,阐述其原理、改进点和特点。
该博客是《Grokking DRL》第11 - 12章笔记。第11章介绍了Policy Gradient和Actor - Critic等on - policy算法,分析了算法优缺点及改进方法。第12章解决复杂环境RL问题,介绍DDPG、TD3、SAC、PPO等算法,阐述其原理、改进点和特点。
《Grokking DRL》笔记(Chapter 11-12)
Chapter 11
主要内容:介绍了几种经典的on-policy的策略梯度算法和actor-critic算法。
Policy Gradient算法
Policy gradient V.S Value-based Methods
首先是目标函数上的区别,在value-based方法中, 最重要的目的就是评估策略,即计算Value function,评估时的损失函数就是targets(可以通过bootstrapped方法也可以是Monte Carlo Return)与预测值之间的MSE误差。除此之外,策略是给定的,一般情况下是epsilon greedy策略。而PG算法中,目标函数是最大化参数化策略(策略作为一个函数)的表现,一般选择用expected total discounted reward (from initial state) 作为策略表现的衡量指标。

PG算法的优点:Policy是可以学得的,是learnable的,相比于值函数更加直接的解决问题(精确的值函数并不是所有问题都需要的);其也可以处理高维的动作空间,尤其是连续动作空间。另外在PG这类算法中,可以通过学得stochastic policy来更好地处理partial observability. 而且在stochastic policy中,由于策略本身就具有探索属性,在训练的过程中可以慢慢收敛到deterministic policy,相比于基于值函数的方法其收敛性更好(因为基于值的方法中,value-function space中的一些细小变化足以在action space上发生直接的变化,因此会带来完全不同的trajectories,从而带来不稳定性).
推导Policy gradient

对上述结论进行如下解释:计算策略梯度可以不知道环境的转移方程。如果某条轨迹的return越大,那么该轨迹下所选取的所有动作的概率都会增加。

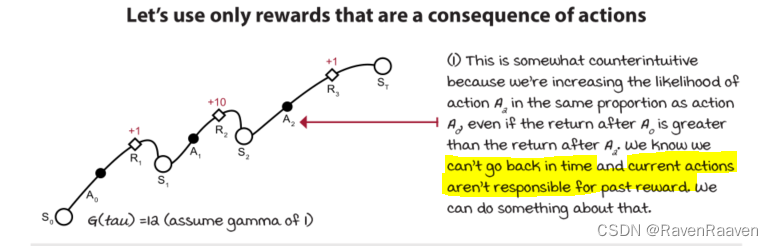
REINFORCE: Outcome-based policy learning

式子中多了一个discount。
REINFORCE存在的问题是:采用的是Monte Carlo的方式进行采样,所以算法的方差较大。
VPG: Learning a value function (Vanilla policy gradient or REINFORCE with baseline)
为了解决REINFORCE中方差较大的问题(不只是初始状态,状态转移是随机的,而且策略也是随机的);一种办法是只是用Partial returns,但是return和action log probability的关系是:return越大,对应的actions log probabilities越大。所以对return进行改进不是一个好的选择。
参考Policy gradient的公式,另外一种选择就是对动作相关的变量进行处理,可以考虑分辨同一个状态下的动作值,即advantage function

Learning a value function
按照上述公式,构造两个网络,一个用于Policy,一个用于value function.
Encouraging exploration
VPG的另一个改进是向损失函数中加入了entropy term,增加了智能体的探索,即尽量均匀分布的动作。

部分代码如下所示:

Actor-Critic算法
如何分辨一个算法是Policy gradient还是actor-critic? Sutton的说法是:直接计算Policy gradient,即便在算法中对value function进行估计但不涉及bootstrapping的方法都是属于policy gradient;其他的使用Policy gradient,并使用了bootstrapping对值函数进行估算的时候是actor-critic算法(因为bootstrapping的方式引入了bias,因此引入了biased target的算法被归类于actor-critic算法)。一般来说,经常会通过加入bias来减少方差。
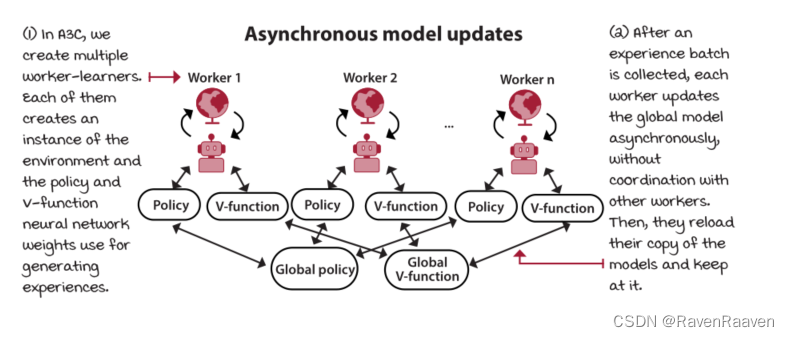
A3C: Parallel policy updates
asynchronous advantage actor-critic (A3C)是一种on-policy的算法,其进一步降低了方差。第一,使用n-steps return with bootstrapping学习策略和值函数;第二,使用并行的actors生成大量的experience sample.
在on-policy算法中,不适合使用replay buffer, 因为用过的数据在策略更新之后就失效了。一种利用on-policy算法还可以产生大量样本的策略是同时使用多个agent workers与环境交互并产生数据(减少了样本数据之间的相关性),并以异步的方式更新策略和值函数。
Using actor-workers
Using n-step estimates
在实现N-step return的时候,可以把Reward和next state value合在一起。N-step return的公式的计算需要n-steps reward和n+1 state的bootstrap值。

actor和critic分别的损失函数如下:

Non-blocking model updates
A3C最重要的部分是网络更新是异步的,并且是Lock-free的。 由于是shared model (包括shared policy and shared value function),一种直接的思考是设计一种死锁机制预防worker 覆盖了其他更新。A3C使用的update style是Hogwild!,该机制能够实现近似于最优的收敛速度,并且优于交替更新。
GAE: Robust advantage estimation
另一种比n-steps return更加Robust是 λ \lambda λ-target. Generalized advantage estimation (GAE) 与TD( λ \lambda λ)相似,但是用于advantages的计算。GAE为任意actor-critic方法提供了一种估算targets for advantage function的方式。

GAE公式:

使用GAE的时候value targets为如下:

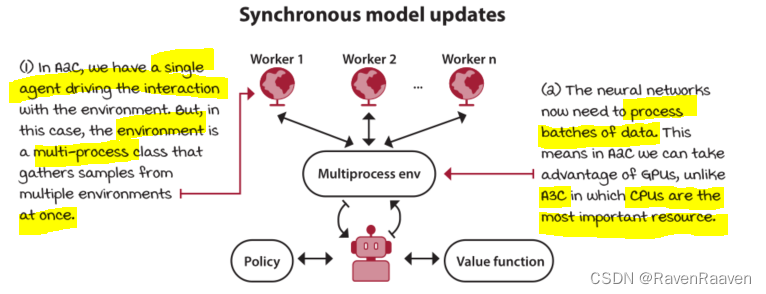
A2C: Synchronous policy updates
A2C是synchronous version of A3C,做了如下改进:
Weight-sharing model
使用一个网络同时表示policy和value function, 但需要主要这种共享可能更适合于图片作为输入。

Restoring order in policy updates
A3C中使用死锁机制会降低A3C的表现。而A2C中使用多个actors和一个single learner. A3C中性能瓶颈在于CPU,A2C可以让神经网络处理更多批量数据,可以利用GPU来加速计算。A2C中使用Multiprocess环境一次性收集一定数量的样本。
Chapter 12
主要内容:解决更加复杂环境中的RL问题,首先是解决deterministic policies的问题,并对其进行改进得到SOTA结果。之后介绍actor-critic方法,直接将entropy作为值函数而不是作为损失函数。
DDPG:Approximating a deterministic policy
deep deterministic policy gradient (DDPG)可以看作用于连续动作空间的DQN算法。DDPG用了很多DQN中的tricks。与DQN对估算出的Q value取argmax不同,DDPG直接利用估算出的Q values更新policy function,最终学得一个最优策略。
DDPG值函数的损失函数:

策略网络目标函数

DDPG中的探索:并不是on-policy的(因为给定一个相同的状态,Policy network总会给出一个相同的action),因此探索是off-policy的。所以在DDPG中我们向actions中加入高斯噪声。

DDPG解决的环境是pendulum-v0,由于是连续动作空间的任务,所以该任务没有terminal state.
TD3: SOTA improvements over DDPG
对DDPG做了3种改进,第一,加入了double learning with ‘twin’ network architecture. 第二,向target actions种也加入了噪声,使得policy network更加对近似误差鲁棒。最后,延迟Policy network,target policy network的更新。
Double learning in DDPG
Q-funtion network with 2 separate streams, 两个对state-action pair的不同估计,属于两个不同的网络。如果任务的输入是图像数据,则可以共享一部分网络。两者唯一共享的是一个优化器(该优化器的参数由这两个网络的参数组成)

每一个twin network都有一个对应的target network, twin network的损失是两个网络的损失之和。
Smoothing the targets used for policy updates
不仅向用于与环境交互的action中加入噪声,还向用于计算targets的actions中加入噪声。noisy targets可以被看成是regularizer,因为网络要处理更多的similar actions.

上述公式在上文的TWIN target的基础上将 μ ( s ′ , ϕ − ) \mu(s',\phi^{-}) μ(s′,ϕ−)替换为 a ′ , s m o o t h = clamp ( μ ( s ′ ; ϕ − ) + clamp ( ϵ , ϵ l , ϵ h ) , a l , a h ) a^{',smooth}=\text{clamp}(\mu(s';\phi^-)+\text{clamp}(\epsilon,\epsilon_l, \epsilon_h),a_l, a_h) a′,smooth=clamp(μ(s′;ϕ−)+clamp(ϵ,ϵl,ϵh),al,ah)(原文的公式有误),存在两个clip操作,第一个是对生成的噪声进行clip操作,第二个是对加上噪声之后的action进行clip操作。
Delaying updates
TD3对Policy network和对应的target policy network的更新进行了延迟。critic网络的更新要比actor网络的更新快。优点在于训练的前期Q function更新的次要多于policy,因此policy update的时候可以使用更为精准的Q value.
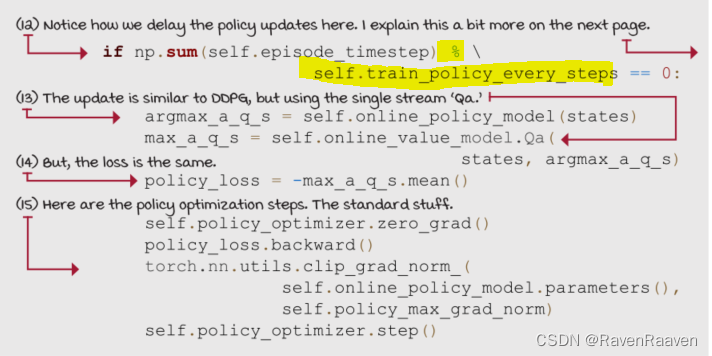
policy updates的过程中使用了online value model的其中一个stream,即 Q a Q_a Qa。
SAC: Maximizing the expected return and entropy
SAC是off-policy,但与REINFORCE, A3C, GAE相同的是,其训练的是stochastic policy而不是deterministic。
SAC最大的特点之一就是将entropy of the stochastic policy加入到了值函数中,能够鼓励智能体有更加diverse的行为。

Learning the action-value function
与TD3类似,SAC也使用两个网络估算Q-function,并且在计算的时候选取一个最小的值,但在优化的时候,分别对这两个网络进行更新。第二点,向targets中加入entropy term. SAC中critic的targets见下图:
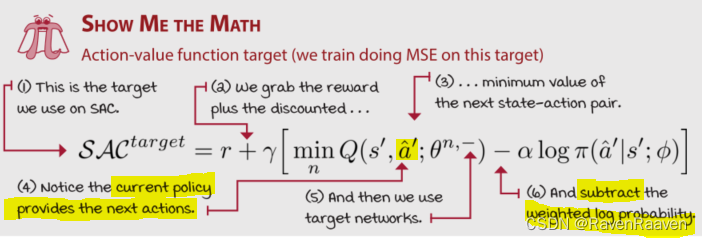
Learning the policy
SAC学的是stochastic policy, 实现的过程中使用的是Squashed Gaussian policy (前向的时候输出高斯分布的均值和方差,采样之后经过一个tanh函数将其rescale到环境所需要的动作范围). 训练策略的时候使用reparameterization tricks,将随机性转移到输入中。policy network的目标函数如下:

Automatically tuning the entropy coefficient
自动调整entropy coefficient α \alpha α,使用基于梯度的优化方法,将 α \alpha α优化到一个heuristic expected entropy. 该值基于action space,the negative of the vector product of the action shape.

PPO: Restricting optimization steps
PPO与A2C有着相同的结构,算是A2C的一个改进版本,可以复用A2C相关的代码。PPO中最重要的创新是使用了一个surrogate objective function,能够允许以On-policy的方式在同一个mini-batch数据上进行多步的gradient-based optimization step。而A2C尽管是一个on-policy算法, 但是并不能在Optimization阶段reuse experiences(因为on-policy之所以称之为on-policy是在于使用完相关经验对策略进行gradient step之后就要立即舍弃)。因此PPO更加的sample-efficient.
PPO引入了一个clipped objective function,该函数的目的是能够防止Policy每一个optimization step之后变得过于不同,优势在于不仅可以降低on-policy policy gradient method的高方差问题,也可以对Mini-batch data进行复用。PPO特点有以下三点:
Batching experiences
Clipping the policy updates
传统的policy gradient的问题在于parameter space中的微小改变也会导致性能上的巨大变化。
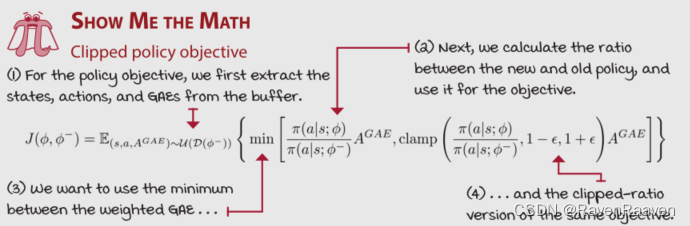
Clipping the value function updates


















 3992
3992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









