







严肃声明
严格禁止未经本人允许转载本文工作成果(包括引言、证明、代码分析等),一经发现被用于学术或商业用途,将予以法律警告。欢迎和笔者深度合作,探讨学术话题。
本人发现部分网站(如https://it.cha138.com/等野鸡网站)未经本人允许私自将本人博客内容转发公开,本人严禁杜绝此类行为,一经发现将投诉举报相关行为并追究违法责任!!!
写在前面
深知新手在接触毫米波雷达板硬件时需要花费的沉没成本,因此在行将告别毫米波雷达之际,总结这两年以来在毫米波雷达上的一些经验和教训。
本文档用于为实现基于AWR1243BOOST等单板毫米波雷达开发提供参考指南与解决方案,主要包括硬件配置、基础参数、信号模型、应用DEMO开发以及可深入研究方向思考等;为更好地匹配后续级联雷达应用的学习路线,在本手册中会尽可能同化单板雷达和级联雷达中的相关表述。
本指南作者信息:Xl,联系方式:xxxxx@zju.edu.cn。未经本人允许,请勿用于商业和学术用途。
本文原文:江湖再见:毫米波雷达开发手册之行为识别应用,原文可以更好地阅读相关图片细节。
希望后者在使用本指南时可以考虑引用作者在毫米波雷达旅途中的相关工作,如下所列:
[1] X. Yu, Z. Cao, Z. Wu, C. Song, J. Zhu and Z. Xu, “A Novel Potential Drowning Detection System Based on Millimeter-Wave Radar,” 2022 17th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, Singapore, 2022, pp. 659-664, doi: 10.1109/ICARCV57592.2022.10004245.
[2] X. Yu, Z. Cao, Z. Wu, C. Song and Z. Xu, “Sample Intercorrelation-Based Multidomain Fusion Network for Aquatic Human Activity Recognition Using Millimeter-Wave Radar,” in IEEE Geoscience and Remote Sensing Letters, vol. 20, pp. 1-5, 2023, Art no. 3505205, doi: 10.1109/LGRS.2023.3284395.
[3] Z. Wu, Z. Cao, X. Yu, C. Song, J. Zhu and Z. Xu, “A Novel Multi-Person Activity Recognition Algorithm Based on Point Clouds Measured by Millimeter-Wave MIMO Radar”, in IEEE Sensor Journal.
本章节为应用DEMO开发,主要讨论笔者在研究生阶段的毫米波雷达水上行为识别工作,包括本领域的研究进展剖析概述、工作成果展示等。
欢迎各位读者通过邮件形式与笔者交流讨论,本章节完整程序请私信笔者,希望使用本代码时能够提供一份引用和Star,以表示对笔者工作的尊重,谢谢!在后续将定时维护更新。
https://github.com/DingdongD/aquatic-activity-dataset 【水上数据集AHAR-I/AHAR-II】
https://github.com/DingdongD/SIMFNet 【TSFNet/SIMFNet】
往期内容:
厚积薄发:毫米波雷达开发手册之大话恒虚警率检测
一统江湖:毫米波雷达开发手册之大话线谱估计
炉火纯青:毫米波雷达开发手册之大话空间谱估计
登堂入室:毫米波雷达开发手册之信号模型
初出茅庐:毫米波雷达开发手册之基础参数
扬帆起航:毫米波雷达开发手册之硬件配置
眼观四海:自动驾驶&4D成像毫米波雷达 如今几何?
雷达人体行为识别领域研究概述
现前的研究中,雷达人体目标识别可以归纳为:目标定位与目标理解。目标定位是基于毫米波雷达传感器对人体进行定位,获取人体目标的运动速度、方位、轨迹等信息;目标理解是基于经验模型或智能算法学习雷达信号与人体行为或状态的映射关系,实现人体行为的深层语义理解与分析。两者是相互反馈与作用的,目标定位通过感知环境中目标的存在,为目标理解提供可靠的信号输入;目标理解通过从雷达信号中抽象出高级表征,反馈于目标定位环节以验证目标存在的真实性。
根据人体不同部位的运动形式分析,人体运动可以认为是宏运动、微运动、生命体征运动的叠加。宏运动是指目标躯体相对雷达视距上的位移运动,微运动是指目标肢体等部位引起的微小运动,生命体征运动是指目标因呼吸、心跳引起的胸腔位移。对应地,目标理解可以细分为手势识别、步态识别、动作识别、生命体征识别等子任务。其中,手势识别是指通过雷达信号的细粒度分析以理解目标手部运动的语义信息,这种任务对雷达工作分辨率要求较高;步态识别是通过提取雷达信号中不同的步态特征,关联目标身份与步态特征,以实现不同目标的身份识别、异常检测;生命体征识别是通过提取目标相位信号解析出心跳、呼吸等特征实现生命健康监测;动作识别是指通过分析雷达信号中多种叠加的特征或模式,以匹配目标最相关的运动状态或类型。综上任务,动作识别(状态检测)任务适配本文所研究的溺水检测课题,因此,在下述讨论中将侧重关注雷达人体动作检测在传统机器学习与深度学习方法方向的研究成果。

传统机器学习是通过支持向量器、多层感知机、最近邻算法及主成分分析等方法来学习输入数据的浅层特征以实现分类任务,这种复杂度较低,可满足实时性要求,但依赖于手工提取的数据特征质量,手工特征提取成本较高,可维护性和泛化性较差,不适合复杂动作识别任务场景。早期,Young Kim等人使用多普勒雷达收集了12名受试者进行7种不同活动的测量数据[1],并从生成的时变多普勒图像中提取出了6类特征,这些特征输入在ANN与SVM上可实现近90%的检测准确率。Zhang等人使用X波段雷达收集了5种不同人体活动的数据[2],并从经短时傅里叶变换后的时频图像中提取了4种特征作为KNN分类器的输入,最终实现了85%的检测准确率。
相较前者,深度学习方法更关注于数据的深层特征,旨在通过学习输入数据与标签信息的映射或输入数据的分布,使模型能够有效预测输出。近年来,不同的深度学习方法被提出用于雷达人体动作识别,并都实现了可观的效果。从深度学习模型类别的观点分析,深度学习包括不同的网络模型(深度卷积神经网络、循环神经网络、Transformer、及图卷积神经网络等)与学习范式(对比学习、迁移学习及元学习等)。从雷达信号信息利用率的观点分析,深度学习可分为单域模型和多域融合模型,单域模型通常指仅将1种具有特定分布信息的谱图(如微多普勒谱图)作为输入所设计的网络模型,多域融合模型则是指利用2种或以上谱图(包括距离-方位、距离-多普勒、节奏速度等谱图)作为输入所设计的融合模型。
Jokanovic等人在基于雷达跌倒检测任务中采用了由2个堆栈自动编码器和Softmax回归分类器构成的DNN模型[3],实验结果证实DNN方法优于传统方法。Li等人提出了1种基于雷达微多普勒、数据增强和深度神经网络(8层CNN结构)的人体活动检测方法[4],这种方法可以实现99%以上的分类精度。He等人基于MOCAP仿真人体活动数据集设计了1种合适的CNN架构[5],通过讨论表明了增加网络层的深度并不总是有助于提高分类精度,应尽可能增加特征图的数目并使其大小保持中等尺寸。深度卷积神经网络具有较强的空间特征提取能力,能够从不同人体动作对应的微多普勒谱图中提取出可区分性表征,但是这种深度模型复杂度较高,在小规模数据集上易发生过拟合。因此,Hao等人在MOCAP数据集上应用基于ImageNet数据集迁移的残差网络来实现不同人体动作的分类[6],相较常规CNN方案平均识别准确率提升了6%。Seyfioğlu等人指出由雷达谱图相关数据预训练得到的模型比传统随机初始化或使用无关的光学图像数据训练的模型参数初始化等范式具有更为有效的效果,所提出的基于MOCAP数据预训练和实测数据微调的DivNet在7分类和11分类人体动作识别上均可取得优异效果[7]。迁移学习有效地降低了模型对数据的需求,提高了训练准确率和收敛速度,但这种方法难以保证模型学习到源输入的细节特征。为了使模型更好地学习到源输入的语义信息,自动编码器被用于提取输入微多普勒谱图的深层特征[8],这种模型通常以最小化重建损失的形式联合有监督分类任务进行训练,有效地提升了模型的泛化性能,并降低了模型过拟合风险。上述方法是基于“雷达微多普勒谱图可视为传统图像”的出发点所提出的,实际上微多普勒谱图可认为是多通道一维时间序列,富含丰富的时序相关性信息。基于此,Aman Shrestha等人将微多普勒谱图或距离-时间谱图视为连续时间序列图像数据[9],提出了递归LSTM和双向LSTM网络结构用于连续活动检测和识别,实现了流行为的实时预测输出,经优化后的Bi-LSTM网络结构在45个不同活动序列中的分类准确率可达到90%以上,证明了双向LSTM可以有效地提取序列数据中前向与后向的时序相关性。Wang等人提出了带有LSTM单元的堆栈式RNN模型从雷达微多普勒谱图中自动提取序列特征[10],最终以92.65%的分类准确率实现了6种不同人体活动的识别。
事实上,单纯依靠时序相关性实现不同人体活动的分类是较为困难的:一方面,人体动作的前后转换存在相似性与干扰行为,动作累积时间短,以致模型难以捕捉到特定表征;另一方面,时序网络自身存在收敛慢、易振荡。为了弥补特定网络提取微多普勒特征的缺陷,时序网络可配合卷积神经网络以更深地提取出微多普勒谱图中的时空特征,Chen等人在IET Radar Challenge中提出了一种基于卷积编码器和残差LSTM组合的时空网络结构[11],利用编码器结构有效地保证了模型学习到微多普勒谱图中的语义信息,并且用LSTM结构提取了时序相关性,最终在6分类任务集上实现了93.8%的SOTA效果。Zhu等人首次提出了“雷达微多普勒谱图可视为多通道时间序列”的观点[12],通过用1DCNN和LSTM的级联结构来提取谱图中的时空信息,在7分类人体活动数据集上实现了98.28%的效果,并且比深度卷积神经网络的性能更为优越。
随着人体行为的多元化和复杂化,不同行为对应的雷达微多普勒谱图可能会高度相似、混淆,因此,现有的依赖微多普勒谱图作为数据输入的单域模型,恐难以在复杂人体活动识别中保持高检测性能。为此,雷达多维信息的利用是新场景下提高人体活动识别性能的关键切入,Ding等人提出了首个雷达多域数据融合网络(MDFRadar Net)[13],这种网络考虑了距离-多普勒、微多普勒及近距离-时间谱图信息的充分利用,使用了1DCNN和LSTM的级联模型来提取微多普勒和距离-时间谱图中的时空特征,并用2DCNN来提取距离-多普勒谱图中的空间特征,再将从3个分支得到的特征向量根据可学习加权策略进行融合,最后输出分类结果;相比单域模型,这种方法充分地利用了雷达信号的丰富语义特征,进而提升了分类性能。MDFRadar Net虽充分利用了雷达不同域的语义信息,但忽略了不同域数据间的关联与交互,因此,Wang等人将距离-时间、多普勒-时间、距离-多普勒谱图视为三个节点,这3个节点满足“全连通”关系,经CNN提取每个域谱图的特征向量作为节点特征,基于节点和邻接矩阵关系构建“图”,利用图卷积神经网络的信息聚合能力来学习域间关联和域内信息,最终在11类人体活动识别上可实现97.37%的分类准确率。Tang等人则是提出了混合卷积神经网络架构从雷达的3种时频图(短时傅里叶变换、汉宁核减少干扰分布和平滑伪魏格纳分布谱图)中提取特征[14],其中2DCNNs用于提取每种谱图中的特定特征,3DCNN则用于提取不同谱图间的相关性特征,这两种特征融合后可有效提升识别准确率;需要注意的是,这3种时频谱图在时序上是对齐的,3DCNN结构更适合提取时序相关性而难以充分捕获频域上的不变性,因此这种方法的有效性有待进步评估。
至此,上述所提的深度学习模型多可归纳为有监督学习,有监督学习的诟病在于:一方面,“模型的通用化依赖于大量有标签数据集”,收集和注释大量雷达数据集是耗时、耗力的,甚至在某些情况下不可行;另一方面,有监督学习通常基于“训练域数据和测试域数据共享同一种概率分布”这一“伪”假设。“伪”:一方面是用户个体差异、环境差异、目标相对雷达视角等变量均会导致同一类行为上采集的雷达信号“有偏”;另一方面是数据分布无法访问,独立同分布特性无从验证,因此在传统的有监督分类任务中,我们往往坚持这种“伪”假设而忽略数据中的差异分布,试图让模型“强制”学习数据域到标签域的这种映射关系。这种有监督模型虽可实现SOTA的人体活动分类效果,但对于新任务的适应能力却很弱。有鉴于此,领域自适应方法成为了雷达人体活动识别的新热点,其通过学习不同域间的共性特征,将在源域上训练完成的模型应用于无监督的目标域,能够有效地解决雷达人体活动数据集上存在的域迁移问题。Lang等人提出了基于特征的域自适应方法[15],通过CNN从源域和目标域中提取出的域不变特征、微多普勒特征、统计特征等3种特征来实现源域和目标域的特征对齐,并用KNN作为分类器实现人体活动识别,这种方法相比TCA、JDA、CORAL等无监督域适应方法具有更优的识别效果,但是所提取的特征过于“浅层”,难以很好地测量数据集上泛化。为了使源域和目标域特征分布在深层适配,Hao等人提出了基于微多普勒的无监督对抗域自适应(ADA)方法[16],这种方法考虑到MOCAP仿真数据集与实测数据集间的差异,引入了域鉴别器与CNN特征提取器对抗,以使特征提取器学习到源域和目标域共享的特征,实验证明了这种域对抗方法可使模型在具有更好的泛化性能。Li等人在前者基础上改进了多层域鉴别器[17],这种结构允许源域和目标域能够在深层次特征上对齐,以学习到域不变特征表示,与仅用ADA相比,在5类实测人体活动目标域数据集上性能提升了2.5%。对抗域迁移模块能以无监督形式提取域不变特征表述,但是却忽略了源域和目标域间的语义关系,因此,Li等人在先前工作基础上提出了语义迁移模块联合对抗域迁移模块的半监督域适应方法[18],通过最小化源域模型训练输出的软标签和目标域模型输出的类别概率向量的信息熵,以实现类相关性从源域至目标域的迁移。Cao等人考虑到不同电磁环境对雷达信号的影响[19],构建了一种用于跨环境雷达人体活动检测的环境自适应机制,这种机制利用了基于邻域聚集和基于聚类的两种自监督伪标签生成方法的加权组合,来为目标域数据生成可靠的伪标签,以提供更强的监督,引导目标特征提取器的学习、实现不同人体活动在跨环境中的泛化。Yang等人提出了一种双阶段域自适应检测方法[20],在第一阶段中域转换网络将MOCAP仿真谱图“翻译”为伪测量谱图,第二阶段中伪测量谱图可用于训练分类器以实现较好的人体活动识别。Chen等人提出了2种域适配网络(JS-DAN和MMD-DAN)来分别学习不同方位采集的微多普勒谱图中的角度不变性和可区分特征[21],以消除目标与雷达相对角度变化引起的差异,一定程度上解决了由角度变量引起的域迁移问题。

除了上述以谱图为输入主体的方法外,雷达点云可以重建人体每个部位的散射体,可视化人体对象的空间物理特征,以用于人体活动识别。Yu等人提供了一个雷达三维点云人体活动分类基准数据集[22],其中使用了DBSCAN方法聚类和LSTM时序网络对点云簇进行分类识别,在4类基准测试集上实现了95%以上的准确率。Young Kim等人使用四级联MIMO雷达获取了7种人体活动的高分辨点云成像[23],并使用深度卷积-循环神经网络对不同活动的点云图像序列提取时空特征以进行分类,这种方法有效解决了目标运动方向与雷达径向时微多普勒谱图等特征提取不明显的状况。Li等人提出了一种基于距离-多普勒-时间点云数据的分层PointNet方法[24],这种方法先将人体后向散射回波通过距离多普勒处理沿时间轴变换为3D点云集,然后根据检测点强度信息对最远点迭代采样来聚合特征,最后通过分层PointNet来学习动态人体运动轮廓以实现人体活动识别,实验证明这种方法在分类精度、点云噪声鲁棒性和异常检测方面具有优异的性能。Gong等人提出了一种适合处理毫米波雷达点云数据的MMPoint-GNN模型[25],通过利用雷达点云的空间坐标、速度、多普勒频率、角度、强度和距离等特征来沿时间轴构建全连接图集,然后使用具有时间分布的MMPoint-GNN和双向LSTM来聚合图节点的特征与学习图前后向关联信息,最终实现人体活动分类。点云的成像质量取决于雷达系统的空间分辨率,现有毫米波雷达多以3发4收为主,角分辨率较低,难以应用于高精度点云人体活动识别。相较而言,联合点云和目标谱图实现行为识别是更合适的方案。Huang等人提出了一种双阶段分离多目标微多普勒信号的方法[26],首先基于点云实现多目标轨迹跟踪、利用轨迹差异实现单目标微多普勒信号的粗分离,其次设计了多任务网络来对混叠微多普勒进行精分离,最后实现每个目标的行为识别。Pegoraro等人提出了可在线的多人连续跟踪与识别系统[27],系统通过在距离-多普勒维或距离-多普勒-角度维上对不同目标点云进行聚类与簇分离,联合使用卡尔曼滤波器与DCNN分类器实现了用户追踪和识别,其中卡尔曼滤波器输出会影响用户分离微多普勒的可靠性,分类器决策信息会反馈于卡尔曼滤波的轨迹分配。
总结分析,以微多普勒为代表的谱图是雷达人体活动识别的主流方案,这种方案允许我们在二维层面分析人体不同行为在距离、多普勒、方位等特征的变化,允许我们根据不同的任务场景、选择合适的谱图组合来区分不同人体行为。但谱图方案存在2个主要的弊端:其一,当目标运动方向与雷达视距正交时,身体不同部位在径向速度上的投影分量较小,这可能会导致谱图上的目标散射特征体现不明显。其二,多目标场景下不同目标的雷达散射回波信号会混叠,这可能会导致不同单目标的信号的解析、分离困难。而3维雷达点云成像则可弥补这种谱图方案的缺陷,其可从空间上区分开不同目标的距离、方位,并可捕获每个目标的物理结构与运动特征。需要注意的是,毫米波雷达点云较为稀疏,高精度的成像依赖于雷达天线的空间分辨率,对系统成本要求较高。

上述总结源于笔者的毕业设计中期答辩的文献综述(截止2022年5月的相关文献),那么在这过去的一年中,雷达人体行为识别领域出现了另一种潮流(以BIT-YXP教授团队的研究[28],[29]为主要代表):稀疏低秩信号恢复与谱图的结合(这是一种高级的玩法,但是应该不是第一次出现,在笔者印象中,NTU-JT教授团队的曾将稀疏重构应用于谱图-点云的映射中)。稀疏低秩信号恢复在雷达线谱估计领域的应用(如目标检测CFAR、目标定位DOA等)相对较多,应用于微多普勒等特征域谱图确实会有点给人以焕新的感觉,但是其实这里需要思考一个问题是:如何将基于稀疏重构(或空间分解)思想分层从特征域谱图中所解析出的噪声信号、背景信号、目标特征信号和下游任务的评估解耦是值得令人深思的地方?为了进一步理解这句话,我将其抽象为以下几层:
1、稀疏重构方法能够有效地将目标特征域谱图理想地分解为噪声空间、目标特征空间、背景空间,甚至干扰空间吗?不同空间不存在耦合吗?噪声/干扰/背景空间对目标特征的识别一定是负作用吗?
2、不稀疏重构的谱图作为网络输入与稀疏重构的信号谱图作为网络输入对最终模型的泛化性能影响会显著吗?
3、将稀疏信号重构和下游任务分离处理恐难以严格地判定方法的可行性,构建信号输入到下游识别的端到端任务仍是关键所在。
4、此外,稀疏重构在一定程度上能够缓解背景环境对目标特征信号的影响,但并没有完全上去解决当前雷达人体行为识别领域面临的多特征域泛化难点(角度、环境、用户差异等协变量偏移引起的泛化性能下降问题),我认为这是当前雷达人体行为识别领域应重点着力去思考解决的地方,甚至是能否建立一套统一的框架去处理各种情况。
以上观点并不意味着稀疏重构对雷达人体行为识别领域的无意义性,新的学科融合必然会带来新的思考;在这里,我想提供一点新的思考:结合稀疏重构信号模型和学习驱动范式来构建深度展开网络,并在深度展开网络的基础上增加下游任务如识别模型,开展多任务处理或许会是一个新的海洋。
水上行为识别数据集


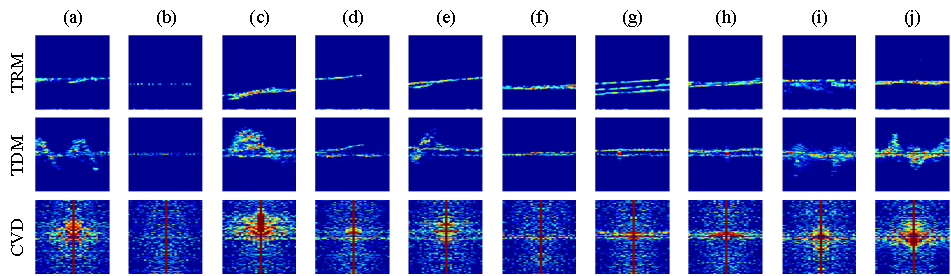
基于雷达多域谱图融合的单人溺水检测方法研究
人体目标作为典型的非刚体,雷达回波信号中包含丰富的人体自身运动信息,这些信息包括宏观运动信息(宏多普勒)、微观运动信息(微多普勒)以及生命体征信息。通过雷达信号解析与信号处理,我们可以将原始雷达数据转换为一维回波序列、二维谱图或三维点云。一维回波序列是将距离-多普勒-方位-时间信息投影到距离维,这会导致较多信息损失;三维点云需要消耗较高的算力,相较而言,二维谱图的处理效率更高,保留的信息较丰富,通常包括距离-多普勒、距离-时间、多普勒-时间、距离-方位、方位-时间、节奏速度等谱图。
现有研究多数基于单域微多普勒谱图,微多普勒图虽能较好地反映不同人体行为的散射特点,但所利用的信息局限于速度-时间分布情况,难以全貌地体现每种行为的完整运动模式。因此,本课题希望通过多域谱图融合的方法来为水上人体行为识别补充其他维度的信息,增强检测识别的可靠性与有效性。

多域谱图融合的输入形式主要有以下2种思路:1、如上图(a)所示,不同的谱图以“通道”形式堆栈后输入模型,模型可学习不同通道间的特征,并利用这些特征区分不同的人体行为;这种输入形式有效降低了输入参数量,但限于小规模数据集和谱图的语义不一致性的因素,模型难以充分学习到这些谱图的内在特征。2、如上图(b)所示,不同的谱图分别作为每个分支的输入,由特定的网络学习每种谱图的特征,最后通过加权聚合、向量拼接等策略对分支特征进行融合,利用融合特征以实现不同人体行为的识别。这种方法能够使网络有效地学习到每种谱图的语义特征,并通过合适的策略融合特征使语义融合匹配、对齐;这种方法的后级网络具有更强的灵活性。因此,本研究中将以第2种多域谱图融合的输入形式作为研究,构建1种双阶段多域融合网络框架,如下图所示。
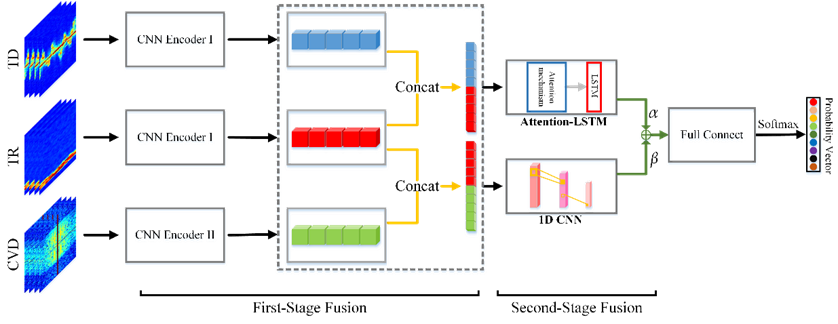
在双阶段多域融合网络框架中,我们以距离-时间、多普勒-时间、节奏速度谱图作为三分支输入。首先,采用卷积编码器架构分别对每个谱图自动编码,在保留原始谱图最相关语义信息及不改变原始谱图时空排列顺序的基础上对谱图进行降维。其次,考虑到距离-时间谱图和多普勒-时间谱图具有时空属性,节奏速度谱图具有丰富的空间属性,这些谱图存在相似的维度可进行语义匹配;因此,这3种谱图的编码特征可以在时间或空间维度上进行第1级融合,以得到时序融合特征向量与空间融合特征向量。再次,我们采用具有注意力机制的LSTM和一维CNN网络来分别处理前级融合向量,以促进不同域谱图深层特征的交互、关联学习;其中,注意力机制能够有效促进网络对每种行为在时序上的特征学习,聚合不同时间节点的分布式特征以增强对全局时序特征的学习;一维CNN用于处理空间融合向量,能够使其有效学习全局空间特征。最后,使用可训练参数α和β对全局融合向量进行加权平均,增强主要特征对分类性能的主导,削弱劣质特征对分类性能的影响。
具体内容请见TSFNet
基于领域自适应/领域泛化的单人溺水检测方法研究
基于“训练集和测试集分布一致性”的假设,传统有监督学习方法,包括所提出的双阶段多域融合网络在水上人体行为识别中具有较好的识别性能,但实际上目标用户差异、目标相对雷达的纵横角、环境干扰等变量可能会影响雷达人体行为数据集的分布发生偏移,进而影响模型的泛化性能。为解决此问题,有相关学者提出了领域自适应的方法,其通过在训练集和测试集间执行实例重加权或特征变换以学习域不变表示,能够有效地减小分布差异。但不幸的是,领域自适应需要访问目标域数据,这在实际应用是不现实的,很难获得测试数据。因此,我们希望能够利用来自不同领域的知识来构建一个模型,这类模型可以很好地推广到未知领域。
我们希望构建1种自适应活动识别框架,这种框架能够学习不同源域的域特定表示和域不变表示,并在统一的深度学习神经网络中动态融合这些特征。在本课题中,我们考虑了用户差异、纵横角差异、环境差异等协变量的影响,这些协变量会引起数据模式的变化;不同于图像数据集给人以“直观、清晰”的特点,雷达信号数据集的语义和多样性难以评估,但我们认为“域迁移”方法能够学习到数据集中的用户不变性、环境不变性、旋转不变性,并且保持数据的多样性以实现泛化。为了学习到这些表征,我们可以学习将每个数据表示为现有训练域的加权集合,并通过正则化模型来学习不同源域的域不变特征以促进知识迁移。

由于浅水区与深水区存在环境差异,深水区有非合作目标(护栏)干扰,如图3.8所示,其主要影响为目标信号的距离-时间谱图上表现带状干扰分布,这可能会增加检测器判别的难度。

如下图所示,雷达相对目标角度的差异主要影响的是目标全速度在雷达径向的投影分量,尤其是当目标运动方向与雷达视距垂直时,目标径向多普勒采样衰减最严重,多普勒-时间谱图的模式会发生较大改变。
“域”是“数据集”的一般概念,通常1个数据集可以分成1个或多个域。在领域泛化中,我们假设有若干可用的训练(源)域,即不同但相关的的训练域 D t r = { D 1 , D 2 , … , D K } D^{tr}=\{D^1,D^2,…,D^K\} Dtr={D1,D2,…,DK},其中 D k = ( x i k , y i k ) ( i = 1 ) ( n k ) D^k={(x_i^k,y_i^k )}_{(i=1)}^{(n_k )} Dk=(xik,yik)(i=1)(nk)表示第k个训练域中有n_k个样本。我们的目标则是在K个训练域上学习一个通用模型以使其能在不可见目标域测试集 D t e = ( x i , y i ) ( i = 1 ) ( n t e ) D^{te}={(x_i,y_i )}_{(i=1)}^{(n_{te} )} Dte=(xi,yi)(i=1)(nte)上实现最小误差。
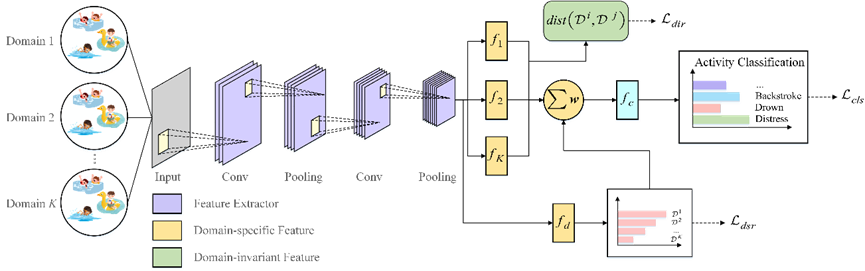
域特定特征的特征学习鼓励模型学习每个域的特定信息,但由于其表现形式的多样性,特征分布差异也可能扩大。因此,域不变特征学习模块被设计用于最小化每个域Di和Dj间的分布差异从训练域中获取一般、可迁移的特征,以寻求与域特定特征表述学习的平衡。为了不同域特征自适应,可以减小每个域对Di和Dj间的分布差异,这种差异度量可以采用MMD Loss,如下式所示:
L
d
i
r
=
2
K
(
K
−
1
)
∑
i
,
j
L
d
i
r
i
j
,
L
d
i
r
i
j
=
∥
1
n
i
∑
x
∈
D
i
ϕ
(
x
)
−
1
n
j
∑
x
∈
D
j
ϕ
(
x
)
∥
H
2
L_{d i r}=\frac{2}{\mathrm{~K}(\mathrm{~K}-1)} \sum_{i, j} L_{d i r}^{i j}, L_{d i r}^{i j}=\left\|\frac{1}{n_i} \sum_{x \in D^i} \phi(x)-\frac{1}{n_j} \sum_{x \in D^j} \phi(x)\right\|_H^2
Ldir= K( K−1)2i,j∑Ldirij,Ldirij=
ni1x∈Di∑ϕ(x)−nj1x∈Dj∑ϕ(x)
H2
最后,活动分类器可以将域特定特征和域不变特征融合输出分类决策,以实现活动识别和溺水检测,该过程的学习目标可以表述为下式所示:
L
=
L
c
t
s
+
λ
L
d
s
r
+
β
L
d
i
r
L
c
l
s
=
−
1
N
∑
i
=
1
N
y
i
log
P
(
y
i
∣
x
i
)
L=L_{c t s}+\lambda L_{d s r}+\beta L_{d i r}\\ L_{c l s}=-\frac{1}{\mathrm{~N}} \sum_{i=1}^N y_i \log P\left(y_i \mid x_i\right)
L=Lcts+λLdsr+βLdirLcls=− N1i=1∑NyilogP(yi∣xi)
由于相关原因,本项工作的主干网络部分可以参加笔者的工作SIMFNET,具体域泛化部分可以和笔者交流探讨。
联合毫米波雷达点云与谱图的多人溺水检测方法研究
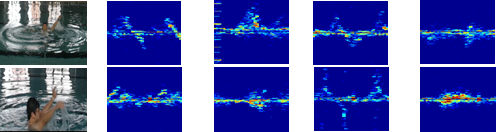
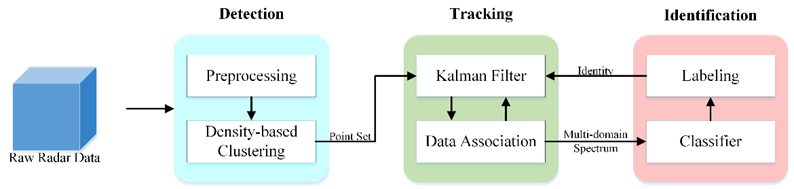
雷达点云可以重建人体每个部位的散射体,在三维空间中全貌地反映人体目标对象的结构特征,用以人体活动识别。如下图所示,联合点云与谱图的多目标溺水检测框架包括检测、追踪和识别,检测环节是点云生成、聚类与分离的过程,追踪环节是将目标历史点云与当前点云簇匹配的过程,识别环节是根据每个目标的点云时序序列生成相应谱图并完成行为识别的过程。
在检测环节中,我们首先通过对距离多普勒谱图进行恒虚警率检测,滤除静态目标和水杂波的反射点,受限于人体部分部位被水环境电磁掩蔽的因素,目标点云较为稀疏。因此,我们通过多帧点云累积,将历史时刻的点云对齐至当前时刻坐标,提升雷达点云的密度;其次,联合点云的三维空间坐标、多普勒速度、强度等信息,我们可以使用DBSCAN聚类算法实现目标点云聚类,进一步滤除无关噪声点;最后,我们通过同一目标簇内点云的强度值加权归一化来计算质心
z
d
z_d
zd表征目标,如下式所示,
r
i
,
v
i
,
θ
i
r_i,v_i,θ_i
ri,vi,θi分布用于表示目标的距离、速度、角度归一化值,
P
R
X
(
p
i
)
P_{RX} (p_i )
PRX(pi)则表示点云的强度值。
z
d
=
∑
p
i
∈
C
d
p
i
P
R
X
(
p
i
)
∑
p
j
∈
c
d
P
R
X
(
p
j
)
,
p
i
=
[
r
i
,
v
i
,
θ
i
]
∈
[
0
,
1
]
z_d=\frac{\sum_{p_i \in C_d} p_i P_{R X}\left(p_i\right)}{\sum_{p_j \in c_d} P_{R X}\left(p_j\right)}, p_i=\left[r_i, v_i, \theta_i\right] \in[0,1]
zd=∑pj∈cdPRX(pj)∑pi∈CdpiPRX(pi),pi=[ri,vi,θi]∈[0,1]
在追踪环节中,离散卡尔曼滤波器可对由质心
z
0
,
z
1
,
…
,
z
D
t
−
1
z_0, z_1, \ldots, z_{D_t-1}
z0,z1,…,zDt−1构成的目标历史位置与当前帧位置进行匹配。卡尔曼滤波器会将目标的距离和速度
x
t
=
[
r
t
,
v
t
]
x_t=[r_t,v_t ]
xt=[rt,vt]与质心
z
t
z_t
zt相关联,通过转换矩阵F和测量矩阵H定义运动模型。转换矩阵F可以将当前状态
x
t
x_t
xt与历史状态
x
(
t
−
1
)
x_{(t-1)}
x(t−1)联系,测量矩阵H则可以将质心状态
z
t
z_t
zt与当前状态
x
t
x_t
xt联系,实际上系统存在过程噪声
u
t
u_t
ut和观测噪声
r
t
r_t
rt,过程噪声
u
t
u_t
ut是由服从标准高斯分布的随机加速度
a
t
a_t
at引起的,其协方差为Q;观测噪声的协方差为R。据此,卡尔曼滤波系统动态模型可以表示为如下:
u
t
=
g
a
t
,
g
=
[
1
2
Δ
t
2
Δ
t
]
Q
=
E
[
u
t
u
t
T
]
=
σ
a
2
g
g
T
R
=
E
[
r
t
t
t
T
]
=
[
σ
r
2
0
0
σ
r
2
]
x
t
=
F
x
t
−
1
+
u
t
,
F
=
[
1
Δ
t
0
1
]
z
t
=
H
x
t
+
r
t
,
H
=
[
1
0
0
1
]
\begin{equation} \begin{gathered} u_t=g a_t, g=\left[\begin{array}{c} \frac{1}{2} \Delta t^2 \\ \Delta t \end{array}\right] \\ Q=E\left[u_t u_t^T\right]=\sigma_a^2 g g^T \\ R=E\left[r_t t_t^T\right]=\left[\begin{array}{cc} \sigma_r^2 & 0 \\ 0 & \sigma_r^2 \end{array}\right] \\ x_t=F x_{t-1}+u_t, F=\left[\begin{array}{cc} 1 & \Delta t \\ 0 & 1 \end{array}\right] \\ z_t=H x_t+r_t, H=\left[\begin{array}{ll} 1 & 0 \\ 0 & 1 \end{array}\right] \end{gathered} \end{equation}
ut=gat,g=[21Δt2Δt]Q=E[ututT]=σa2ggTR=E[rtttT]=[σr200σr2]xt=Fxt−1+ut,F=[10Δt1]zt=Hxt+rt,H=[1001]
在每帧处理后的点云䇹中, 为每个检测到的初始化新的卡尔曼滤波模型; 在连续帧中, 通过卡尔曼预测更新状态、计算出状态估计会和状态协方差矩阵
P
^
t
\hat{P}_t
P^t 。为了每帧中的轨迹与与簇匹配, 我们需要先计算
K
t
−
1
×
D
t
K_{t-1} \times D_t
Kt−1×Dt 的代价矩阵
J
cos
t
(
J
i
j
J_{\cos t}\left(J_{i j}\right.
Jcost(Jij 表示轨迹
i
i
i 与检测簇点
j
j
j 的关联成本), 再根据匈牙利算法对代价矩阵进行数据互联, 将
D
t
D_t
Dt 个检测到的新簇与
K
t
−
1
K_{t-1}
Kt−1 个先前轨迹关联。在 完成目标簇与轨迹匹配后, 我们可以根据不同目标的点云时序流(包括了坐标、多普勒速度、 能量强度等) 来生成相应的多域谱图。
在识别环节中, 我们通过先前所设计的网络模型对多域谱图进行识别、分类, 判断目标是否发生溺水。需要注意的是, 多目标场景下不同用户存在某个时间点相交时点云 笶会发生混叠, 这可能会造成两个层面问题: 1、轨迹分配错误; 2、生成的多域谱图出现混 叠, 难以区分。因此, 我们希望用分类器输出的分类向量反馈到数据互联中的代价矩阵, 调 整用户轨迹分配, 提高用户分离的可靠性。其中, 分类器输出
K
t
K_t
Kt 个
U
U
U 维向量用以表示每个轨 迹归属
U
U
U 个用户的概率, 通过堆栈可得到与代价矩阵
J
J
J 相似的矩阵
Γ
t
\Gamma_t
Γt, 在所得矩阵
Γ
t
\Gamma_t
Γt 上利用 DS 判据来进步分配准确的轨迹, 为谱图生成提供可靠的点云流。
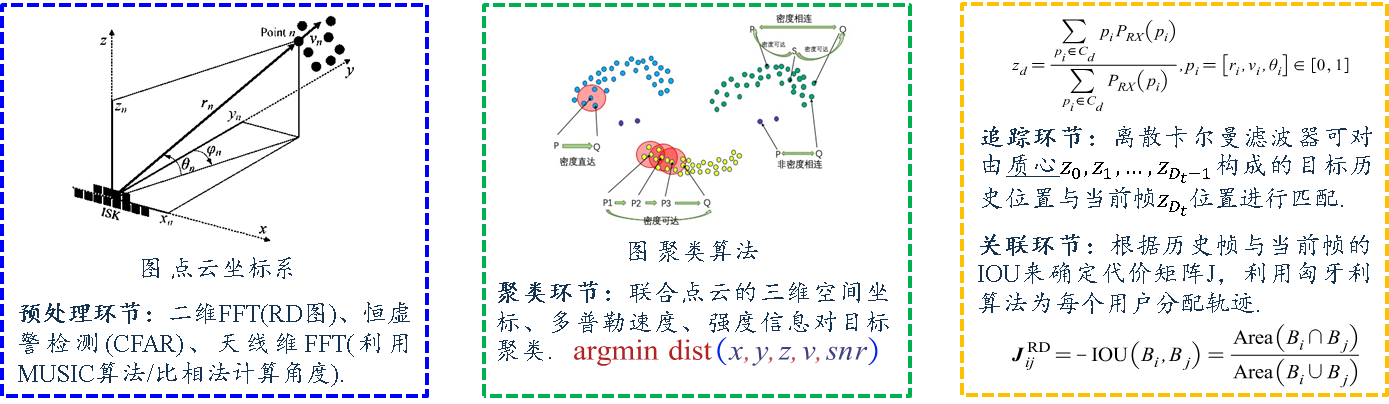
我们分析了多目标溺水场景下的点云分布特征,主要可归纳为以下几点:1、水面杂波和相邻强目标可能会对溺水目标检测形成掩蔽,这是由于溺水目标点云成像稀疏、不连续所致;2、在目标同距或目标相遇时,两目标的点云簇会紧凑、难以分离,进而影响目标状态的判别。
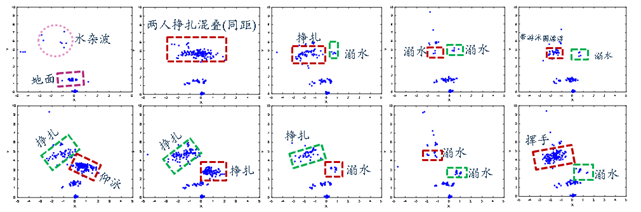
参考文献
[1] Zhang Z, Zhang R, Sheng W, et al. Feature extraction and classification of human motions with LFMCW radar[C]. 2016 IEEE International Workshop on Electromagnetics: Applications and Student Innovation Competition (iWEM). IEEE, 2016: 1-3.
[2] Jokanovic B, Amin M, Ahmad F. Radar fall motion detection using deep learning[C]. 2016 IEEE radar conference (RadarConf). IEEE, 2016: 1-6.
[3] Li J, Chen X, Yu G, et al. High-precision human activity classification via radar micro-doppler signatures based on deep neural network[C]. IET International Radar Conference (IET IRC 2020). IET, 2020, 2020: 1124-1129.
[4] He Y, Yang Y, Lang Y, et al. Deep learning based human activity classification in radar micro-Doppler image[C]. 2018 15th European Radar Conference (EuRAD). IEEE, 2018: 230-233.
[5] Du H, Jin T, Song Y, et al. Efficient human activity classification via sparsity‐driven transfer learning[J]. IET Radar, Sonar & Navigation, 2019, 13(10): 1741-1746.
[6] Seyfioglu M S, Erol B, Gurbuz S Z, et al. DNN transfer learning from diversified micro-Doppler for motion classification[J]. IEEE Transactions on Aerospace and Electronic Systems, 2018, 55(5): 2164-2180.
[7] Seyfioğlu M S, Gürbüz S Z. Deep neural network initialization methods for micro-Doppler classification with low training sample support[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(12): 2462-2466.
[8] Shrestha A, Li H, Le Kernec J, et al. Continuous human activity classification from FMCW radar with Bi-LSTM networks[J]. IEEE Sensors Journal, 2020, 20(22): 13607-13619.
[9] Wang M, Zhang Y D, Cui G. Human motion recognition exploiting radar with stacked recurrent neural network[J]. Digital Signal Processing, 2019, 87: 125-131.
[10] Chen Z, Li G. Human activity classification with neural network using radar micro-doppler and range signatures[J]. 2021.
[11] Zhu J, Chen H, Ye W. A hybrid CNN–LSTM network for the classification of human activities based on micro-Doppler radar[J]. IEEE Access, 2020, 8: 24713-24720.
[12] Ding W, Guo X, Wang G. Radar-based human activity recognition using hybrid neural network model with multidomain fusion[J]. IEEE Transactions on Aerospace and Electronic Systems, 2021, 57(5): 2889-2898.
[13] Wang X, Guo S, Chen J, et al. GCN-Enhanced Multi-domain Fusion Network for Through-wall Human Activity Recognition[J]. IEEE Geoscience and Remote Sensing Letters, 2022.
[14] Tang L, Jia Y, Qian Y, et al. Human Activity Recognition Based on Mixed CNN With Radar Multi-Spectrogram[J]. IEEE Sensors Journal, 2021, 21(22): 25950-25962.
[15] Lang Y, Wang Q, Yang Y, et al. Unsupervised domain adaptation for micro-Doppler human motion classification via feature fusion[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 16(3): 392-396.
[16] Du H, Jin T, Song Y, et al. Unsupervised adversarial domain adaptation for micro-Doppler based human activity classification[J]. IEEE geoscience and remote sensing letters, 2019, 17(1): 62-66.
[17] Li X, Jing X, He Y. Unsupervised domain adaptation for human activity recognition in radar[C]. 2020 IEEE Radar Conference (RadarConf20). IEEE, 2020: 1-5.
[18] Li X, He Y, Fioranelli F, et al. Semisupervised human activity recognition with radar micro-Doppler signatures[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 1-12.
[19] Cao Z, Li Z, Guo X, et al. Towards Cross-Environment Human Activity Recognition Based on Radar Without Source Data[J]. IEEE Transactions on Vehicular Technology, 2021, 70(11): 11843-11854.
[20] Yang Y, Zhang Y, Ji H, et al. Radar-Based Human Activity Recognition Under the Limited Measurement Data Support Using Domain Translation[J]. IEEE Signal Processing Letters, 2022.
[21] Chen Q, Liu Y, Fioranelli F, et al. Eliminate aspect angle variations for human activity recognition using unsupervised deep adaptation network[C]. 2019 IEEE Radar Conference (RadarConf). IEEE, 2019: 1-6.
[22] Yu Z, Taha A, Taylor W, et al. A Radar-based Human Activity Recognition Using a Novel 3D point cloud classifier[J]. IEEE Sensors Journal, 2022.
[23] Kim Y, Alnujaim I, Oh D. Human activity classification based on point clouds measured by millimeter wave MIMO radar with deep recurrent neural networks[J]. IEEE Sensors Journal, 2021, 21(12): 13522-13529.
[24] Li M, Chen T, Du H. Human behavior recognition using range-velocity-time points[J]. IEEE Access, 2020, 8: 37914-37925.
[25] Gong P, Wang C, Zhang L. Mmpoint-GNN: graph neural network with dynamic edges for human activity recognition through a millimeter-wave radar[C]. 2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021: 1-7.
[26] Huang X, Ding J, Liang D, et al. Multi-person recognition using separated micro-Doppler signatures[J]. IEEE Sensors Journal, 2020, 20(12): 6605-6611.
[27] Pegoraro J, Meneghello F, Rossi M. Multiperson continuous tracking and identification from mm-wave micro-Doppler signatures[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 59(4): 2994-3009.
[28] X. Qu, W. Gao, H. Meng, Y. Zhao and X. Yang, “Indoor Human Behavior Recognition Method Based on Wavelet Scattering Network and Conditional Random Field Model,” in IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1-15, 2023, Art no. 5104815, doi: 10.1109/TGRS.2023.3276023.
[29] W. Gao, X. Yang, X. Qu and T. Lan, “TWR-MCAE: A Data Augmentation Method for Through-the-Wall Radar Human Motion Recognition,” in IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1-17, 2022, Art no. 5118617, doi: 10.1109/TGRS.2022.3213748.















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









