







从池化的角度看GNN(包含PR-GNN,EdgePool等7篇论文)中篇
前言
这里承接上篇笔记【从池化的角度看GNN(包含PR-GNN,EdgePool等7篇论文)上篇】继续后面几篇论文的笔记:

- 论文EdgePool:《Edge Contraction Pooling for Graph Neural Networks》
- 论文HaarPooling:《Haar Graph Pooling》
- 论文GSAPool:《Structure-Feature based Graph Self-adaptive Pooling》
这里为了方便大家阅读,我把总结部分同步到每一篇笔记中
原创笔记,未经同意请勿转载
一些总结
现有图池化操作主要可以分为全局池化(如SortPool)、分层池化,分层池化中还可以分为基于聚类(如DiffPool,StructPool)和基于重要性排序(如TopK Poolig,SAGPool,GSAPool等)的池化操作,同时也可以衍生出基于频谱上处理的池化操作(如EigenPool,LaPool,HaarPool等)。
- 改进1:为更加有效地利用图中边所带来的信息,还又EdgePool的池化操作,使得图在池化过程中也可以关注到对应的边缘特征。
- 改进2:如何更加有效地利用节点对之间关联关系所包含的特征信息,如PR-GNN
- 改进3:如何改进基于重要性排序的图池化操作?——》所面对的问题:丢弃不重要节点所带来的特征信息重要缺失问题 ——-》解决方法:① 拉大节点之间差距,如PR-GNN ② 在丢弃前聚类节点特征,如GSAPool ③ 多特征融合与子图学习机制辅助,如HCP-SL
- 改进4:如何改进基于聚类的图池化操作?——-》所面对的问题:聚类之后的模型可解释性差,聚类之间的关联关系少 ——》解决方法:① 聚类信息中融入关联关系与图结构信息,如StructPool ② 簇内外注意力机制加持与局部关注,如ASAP
- 改进5:如何更有效地保留图层次及子图结构信息?——》所面对的问题:在空间域上处理的池化操作不利于图结构信息的保留 ——》解决方法:频谱上的处理:① 拉普拉斯变换,如LaPool ② 图傅里叶变换,如EigenPool ③ Haar变换,如HaarPool
一些早期论文的简要介绍
下篇再放最后三篇。
2️⃣论文EdgePool:《Edge Contraction Pooling for Graph Neural Networks》
- 来源: NeurIPS 2019 【Most Disruptive Idea】
- 原文链接: https://arxiv.org/abs/1905.10990
- 代码链接: https://github.com/rusty1s/pytorch_geometric/tree/master/benchmark/kernel
- 数据及任务:
(1)数据特点:有向图,节点有特征、边无特征
(2)面向任务:图分类、节点分类
(3)所采用的数据集:
① 图分类数据集(主要采用蛋白质数据集【判断是否为酶】、在线用户交流网络数据集【判断是否为subreddit】、科研人员合作关系网络数据集【判断为哪种研究领域】)
② 节点分类数据集(主要采用论文引用网络数据集【对每个文档中的字段进行分类/类文档模板分析】、亚马逊共同购买关系图标【预测产品类别】)

- 主要的出发点: 之前的池化试基于节点的选择,容易破环丢失图结构本身的属性(如TopK Pooling会丢掉一些节点,丢失了一些图节点信息;基于聚类的Pooling容易忽略图的结构)。因此,EdgePool通过基于边的选择于汇集连接节点来实现。这样子既可以避免节点的丢失,又可以简单的考虑到图的结构。
- 亮点: 提出了一种基于边收缩的池化机制EdgePool(能够学习一个局部和稀疏的硬池化变换,考虑图的结构,确保不会完全删除节点)【易于集成】
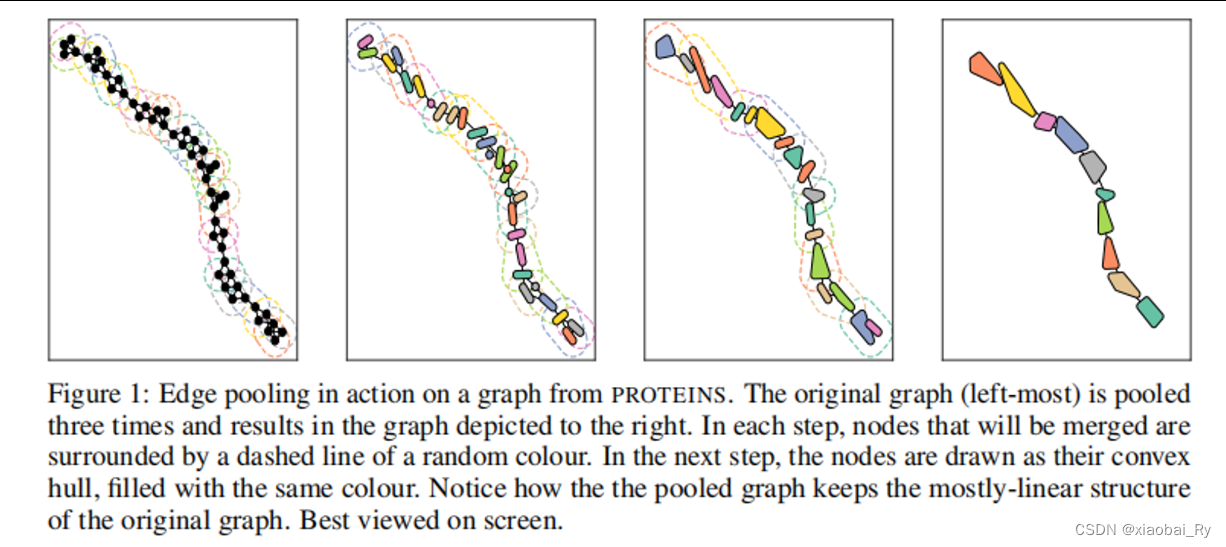
- 主要做法:
- 定义边地收缩机制: 通过引入新的节点(更深层的节点)ve与新的边(如上图所示)来进行简单的池化,使ve与所有vi或vj相邻的节点都相邻,vi,vj及其所有边都从图中删除。即Edge contraction选择一条边合并它的节点至一个新节点,然后,这个新节点连接到合并节点已经连接到的所有节点。
- 边地更新: 计算每条边的得分来选择边,然后为得分最高的边(注:Edge contraction得到的新边并不参与其中)进行Edge contraction。边的分数由其节点对及边的特征拼接起来并经过线性变换得到:

在EdgePool中,为了不同边之间的分数比较容易地比较,利用softmax来归一化边的分数(即使所有和节点j相连的节点以节点j为中心的边的分数和为1)

**(3)新节点的生成:**边的更新得到新的图结构,合并对应的节点之后,新的节点(超节点)的特征由两个节点特征加权,同时把边的分数也考虑进去。
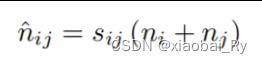
注:在EdgePool论文中,新的节点特征由两个不同的节点及边的分数来表示,因此EdgePool每次只保留50%的节点。
**(4)节点层级之间的映射:**边EdgePool所面对的任务的节点分类任务,因此在进行池化时,需要将上一层图的每个节点映射到当前层的图节点上。又图的结构已在第2步中确定,所以只需要对新生成的节点特征进行还原即可:
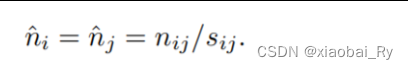
注:这一步虽然看起来很简单,但从论文的实验结果来看的话,这一步起了比较有用的作用。
实验结果:
(1)EdgePool集成到现有经典的图模型中:
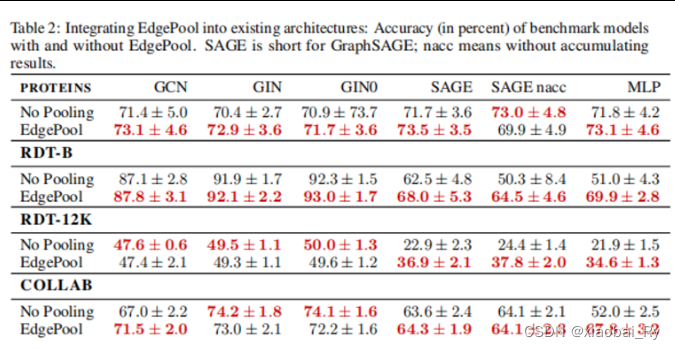 (2)EdgePool在图分类上的效果:
(2)EdgePool在图分类上的效果:
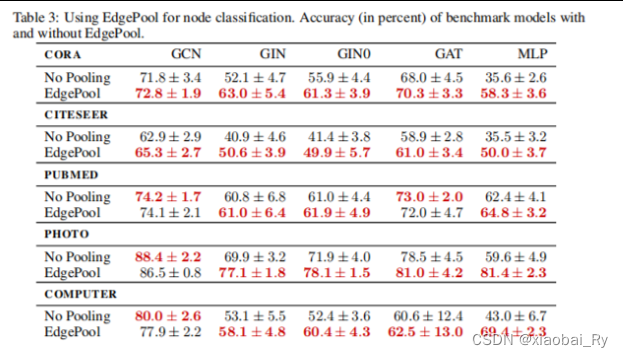
 (3)EdgePool节点分类任务效果
(3)EdgePool节点分类任务效果
3️⃣论文HaarPooling:《Haar Graph Pooling》
- 来源: ICML2020
- 原文链接: https://arxiv.org/pdf/1909.11580.pdf
- 代码链接: https://www.dropbox.com/sh/33s71980xnde0m1/AADyiIYXON6pFFWcWChO3_B0a?dl=0
- 视频链接: https://slideslive.com/38927848/haar-graph-pooling?ref=speaker-17049-latest&locale=en
- 在线阅读链接: https://deepai.org/publication/haarpooling-graph-pooling-with-compressive-haar-basis
- 数据及任务:
(1)面向任务:图分类及回归任务
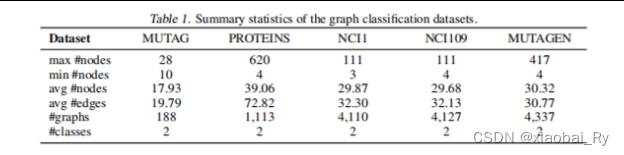
(2)所采用的数据:
- 主要的出发点:怎么在有效利用特征信息的同时保留好图结构信息,同时使计算效率高?
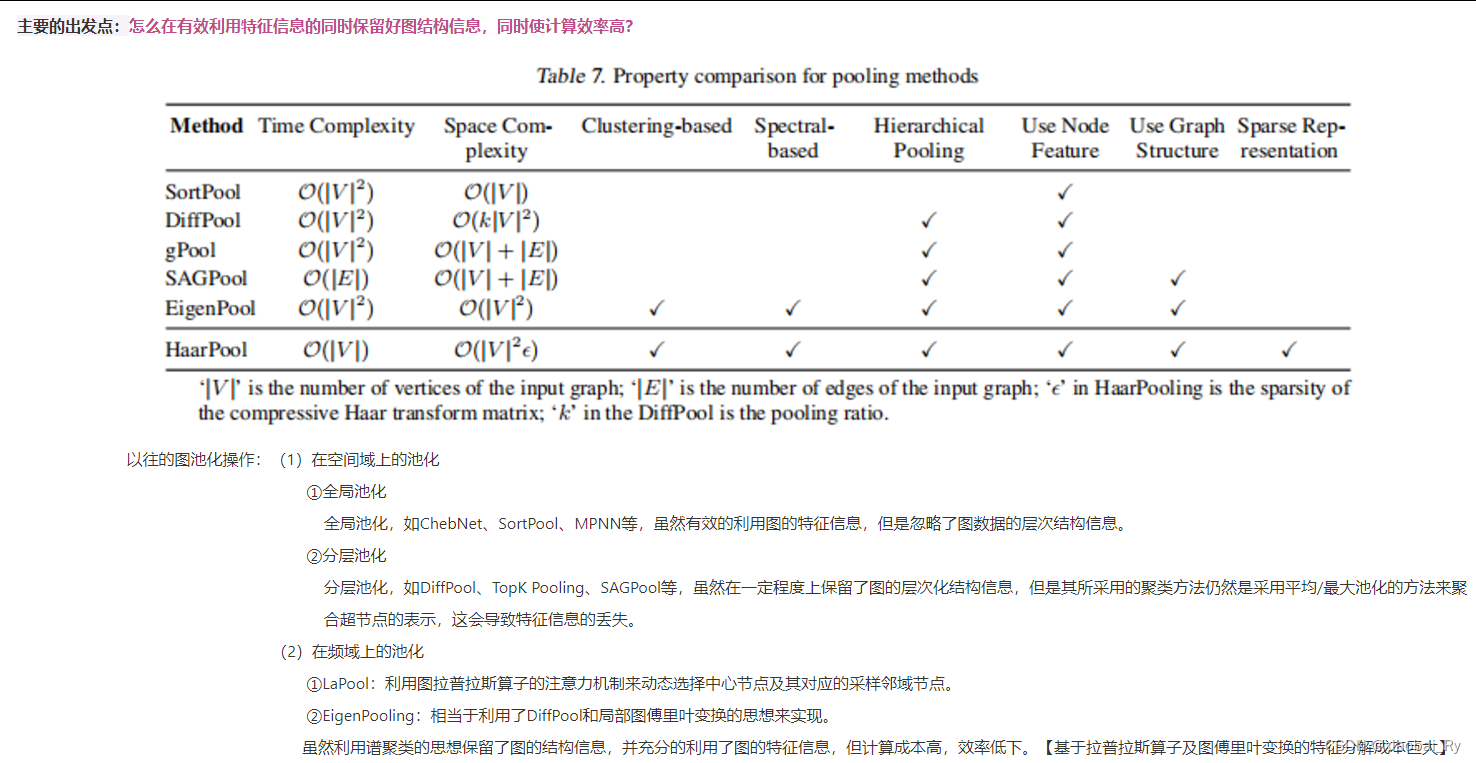 以往的图池化操作:
以往的图池化操作:
- 在空间域上的池化
① 全局池化
全局池化,如ChebNet、SortPool、MPNN等,虽然有效地利用图的特征信息,但是忽略了图数据的层次结构信息。
②分层池化
分层池化,如DiffPool、TopK Pooling、SAGPool等,虽然在一定程度上保留了图的层次化结构信息,但是其所采用的聚类方法仍然是采用平均/最大池化的方法来聚合超节点的表示,这会导致特征信息的丢失。 - 在频域上的池化
① LaPool:利用图拉普拉斯算子的注意力机制来动态选择中心节点及其对应的采样邻域节点。
②EigenPooling:相当于利用了DiffPool和局部图傅里叶变换的思想来实现。
虽然利用谱聚类的思想保留了图的结构信息,并充分的利用了图的特征信息,但计算成本高,效率低下。【基于拉普拉斯算子及图傅里叶变换的特征分解成本巨大】
-
亮点: 提出了一种基于Haar变换的图池化操作HaarPooling【输入与输出图的特征维度数一致,节点数目减少】(从流程图上来看,HaarPooling是一种分层池化的操作,处理流程跟DiffPool、EigenPooling类似),属于频域上分层池化的图池化操作。
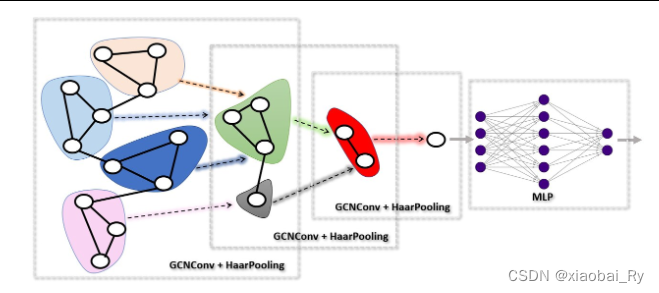
-
内容: Haar 基通过频域中的低频和高频 Haar 系数表示图形结构数据。低频系数包含原始数据的粗略信息,而高频系数包含精细细节。在 HaarPooing 中,通过丢弃精细的细节信息来汇集(或压缩)数据。在压缩 Haar 变换中保留了 Haar 小波分解的近似部分,因此池化中的信息损失很小。
-
流程:构造Haar基 ——》 基于Haar基进行Graph Haar变换【图频域变换原理】 ——》 基于Haar空间进行图池化操作

-
实验结果: 与基于重要性排序的池化操作相比如TopK Pooling相比,HaarPooling对节点数目的选择不敏感,更具鲁棒性和泛化性

4️⃣论文GSAPool:《Structure-Feature based Graph Self-adaptive Pooling》
-
来源: WWW2020
-
数据任务: 数据集:
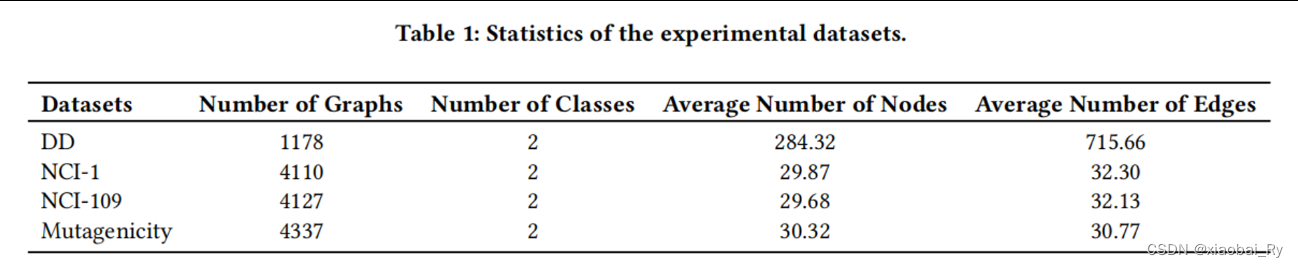
-
主要的出发点:主要就是在SAGPool的基础上考虑了节点的属性特征(即在丢弃前采用MLP对节点的特征信息进行聚合),属于基于重要性排序的分层池化操作
- 问题:现有的基于top-k的图池化方法存在两个问题:
① 在生成粗化图时没有同时考虑到图结构特征与节点特征,仅从单个角度评估节点的重要性,过于简单和客观。
② 在池化过程中,未选择节点的特征信息直接丢失,不可避免地导致大量图特征信息丢失。 - 思路:
①为了构建合理的池化图拓扑,同时考虑了图的结构和特征信息,在节点选择上提供了更高的准确性和客观性;
②为了使合并的节点包含足够有效的图信息,在丢弃不重要节点之前对节点特征信息进行聚合;因此,被选中的节点包含来自邻居节点的信息,可以增强未被选中节点特征的使用。
- 问题:现有的基于top-k的图池化方法存在两个问题:
-
亮点: 提出了一种图自适应池化操作GSAPool,解决了TopK Pooling中丢弃所带来的信息缺失问题。
-
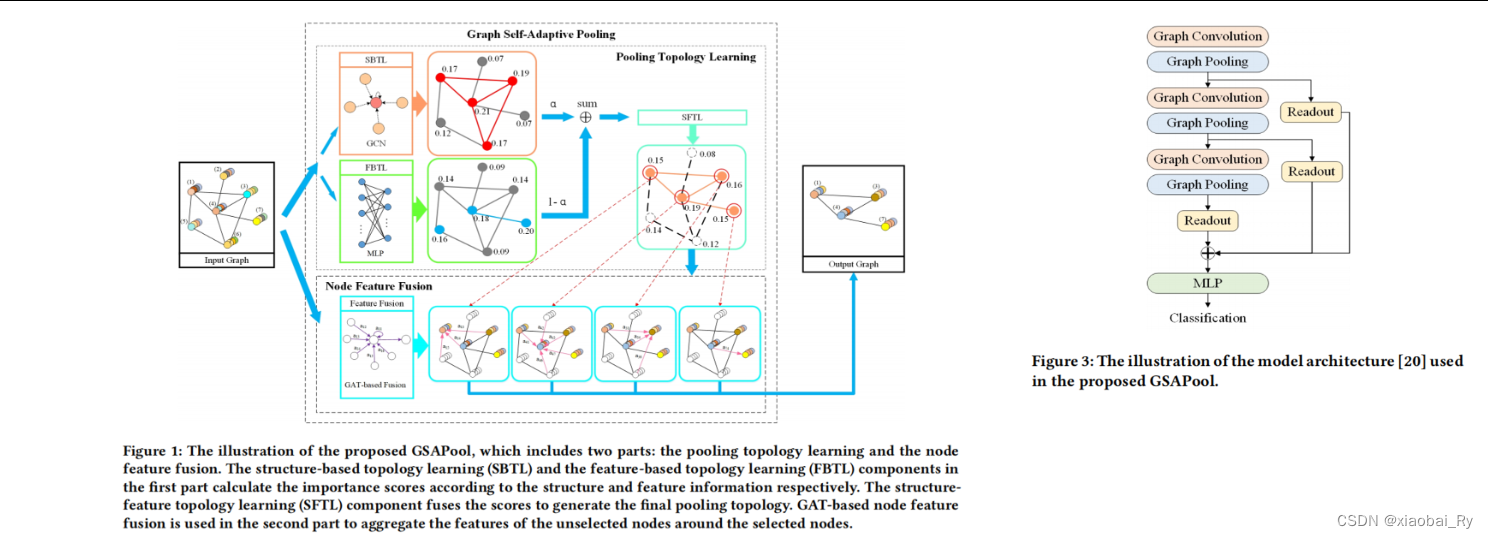
内容: 为从论文框架图来看,GSAPool主要包含三个部分的学习【基于结构的拓扑学习(SBTL)、基于特征的拓扑学习(FBTL)和基于结构特征的拓扑学习(SFTL)】和节点特征的融合。其中:
-
SBTL采用GCNConv来计算节点的结构信息重要性【当然也可以采用ChebConv、GraphSAGE、GAT等来评价节点的结构信息重要性】

-
FBTL采用MLP来计算系欸点特征信息的重要性

-
SFTL组件融合得分,生成最终的池拓扑。

-
节点特征融合采用GAT方法来将未选节点(丢弃的节点)的特征融合到所选节点周围。
在top-k选择池方法中,仅选择部分节点作为池结果。要使用未选中节点的信息,必须在丢弃节点之前聚合节点的特征。充分利用节点的特征信息,使最终的图嵌入向量更具代表性。
 不同的节点特征融合策略:
不同的节点特征融合策略:
(a.)合并后的节点只保留自己的特征,
(b.)合并后的节点在1跳邻居节点内的聚集特征,
(c.)合并后的节点在n跳邻居节点内的聚集特征
带箭头的边缘表示融合过程中特征信息流动的方向。
-
-
实验结果: 与DiffPool和特征池相比,GSAPool同时利用了结构和特征信息。因此,GSAPool可以使用额外的图信息来构造图池化。GSAPool综合考虑了节点的信息,采用特征融合机制,使得融合后的图能够合理、准确地表示原始图,因而优于gPool和SAGPool。因此,GSAPool可以获得更好的性能。
下一篇章笔记链接
下面笔记链接:
从池化的角度看GNN(包含PR-GNN,EdgePool等7篇论文)下篇笔记
包括:
- 论文StructPool:《StructPool: Structured Graph Pooling via Conditional Random Fields》
- 论文ASAP:《ASAP: Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations》
- 论文HCP-SL:《Hierarchical Graph Pooling with Structure Learning》

















 4331
4331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











