







目录
摘要: 番茄作为全球广泛种植的蔬菜作物之一,其生长过程中常受到多种病害的威胁,如晚疫病、白粉病和细菌性斑点病等。这些病害不仅影响番茄的生长速度和产量,还可能对番茄的品质造成严重影响。因此,及早检测和准确识别番茄叶部病害对于提高番茄产量、保障食品安全具有重要意义。基于深度学习的番茄叶检测识别系统,正是为了解决这一问题而设计的。基于YOLOv10/v9/v8深度学习框架,通过700多张番茄叶疾病的相关图片,进行番茄叶疾病目标检测模型训练,可检测7种目标:[0: Bacterial_Spot、1: Early_Blight、2: Healthy、3: Late_blight、4: Leaf_Mold、5: Target_Spot、6: black_spot] 同时对相关模型进行了对比,全面对比分析了YOLOv8、YOLOv9、YOLOv10这3种模型在验证集上的评估性能表现。最后基于训练好的模型制作了一款带UI界面的水面目标物检测识别系统,更便于功能演示,保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件可公众号获取。
一、研究背景
番茄作为全球广泛种植的蔬菜作物之一,其产量和品质对农业生产和食品安全具有重要意义。然而,在番茄的生长过程中,常常会受到各种病害的威胁,如晚疫病、白粉病、细菌性斑点病等。这些病害不仅会导致番茄生长速度减缓、产量下降,还会严重影响番茄的品质和口感。因此,及早发现和准确识别番茄叶部病害,对于提高番茄产量、保障食品安全具有迫切的需求。传统的番茄叶部病害检测方法主要依赖于人工观察和经验判断,这种方法存在诸多局限性。首先,人工检测需要投入大量的人力和时间,效率低下且成本高昂。其次,人工检测的结果容易受到主观因素的影响,存在误判和漏判的风险。此外,随着番茄种植面积的扩大和病害种类的增多,传统的人工检测方法已经难以满足现代农业生产的需要。近年来,深度学习技术在计算机视觉领域取得了显著进展,为番茄叶部病害的自动化检测识别提供了新的解决方案。运用深度学习技术,YOLOV10\YOLOV9\YOLOV8深度学习框架训练河道漂浮物检测模型,系统可以高效、准确的检测番茄叶疾病,番茄叶疾病检测识别将更加智能化、精准化和高效。基于深度学习的番茄叶检测识别系统是一个具有广泛应用前景和重要意义的研究方向。通过不断优化和完善该系统,我们可以为农业生产提供更加精准、高效的病害识别解决方案。
其主要应用场景包括:
1. 农业生产现场监测
实时病害检测:在番茄种植园区内,系统可以实时捕捉番茄叶片的图像,通过深度学习算法快速分析并识别出病害类型,为农民提供即时的病害预警。
精准施药指导:根据病害识别结果,系统可以为农民提供针对性的施药建议,减少农药的滥用,降低环境污染,同时提高病害防治效果。
2. 智慧农业管理平台
远程监控:智慧农业管理平台可以集成基于深度学习的番茄叶疾病检测识别系统,实现对多个种植园区的远程监控和管理。管理人员可以随时随地查看各园区的病害情况,及时采取应对措施。
数据分析与决策支持:系统可以对历史病害数据进行深度分析,为农业生产提供数据支持。通过大数据分析,管理人员可以预测病害发生趋势,制定科学的生产计划和病害防控策略。
3. 农业科研与教学
病害研究:科研人员可以利用该系统收集大量的病害图像数据,用于研究病害的发生发展规律、病害与环境因素的关系等。这些数据有助于揭示病害的生物学特性和传播途径,为病害防控提供理论依据。
教学演示:在教学过程中,教师可以利用该系统展示番茄叶病害的识别过程,帮助学生更好地理解深度学习在农业领域的应用。通过实际操作和案例分析,提高学生的实践能力和学习兴趣。
4. 农业保险理赔
病害评估:在农业保险理赔过程中,系统可以对受损番茄叶片进行病害评估,确定病害类型和严重程度。这有助于保险公司快速、准确地核定损失金额,提高理赔效率。
预防建议:系统还可以根据评估结果提供病害预防建议,帮助农民降低未来病害发生的风险,从而减少保险赔付的可能性。
5. 农业市场与供应链管理
品质控制:在番茄的采摘、包装和运输过程中,系统可以检测番茄叶片的病害情况,确保上市销售的番茄品质优良。这有助于提升农产品的市场竞争力,增加农民收入。
供应链管理:系统可以与农业供应链管理系统集成,实现病害信息的实时共享。供应商、生产商和销售商可以共同关注番茄病害情况,及时调整生产和销售策略,确保供应链的顺畅运行。
综上所述,基于深度学习的番茄叶疾病检测识别系统在农业生产、智慧农业管理平台、农业科研与教学、农业保险理赔以及农业市场与供应链管理等方面都有广泛的应用前景。这些应用场景不仅提高了农业生产的效率和病害防控的精准度,还促进了农业产业的可持续发展。
二、主要工作内容
本文的主要内容包括以下几个方面:
-
搜集与整理数据集:搜集整理实际场景中番茄叶疾病的相关数据图片,并进行相应的数据处理,为模型训练提供训练数据集;
-
训练模型: 基于整理的数据集,根据最前沿的YOLOv10/v9/v8目标检测技术 训练目标检测模型,实现对需要检测的对象进行实时检测功能;
-
模型性能对比: 对训练出的3种模型在验证集上进行了充分的结果评估和对比分析,主要目的是为了揭示每个模型在关键指标(如Precision、Recall、mAP50和mAP50-95等指标)上的优劣势。这不仅帮助我们在实际应用中选择最适合特定需求的模型,还能够指导后续模型优化和调优工作,以期获得更高的检测准确率和速度。最终,通过这种系统化的对比和分析,我们能更好地理解模型的鲁棒性、泛化能力以及在不同类别上的检测表现,为开发更高效的计算机视觉系统提供坚实的基础。
-
可视化系统制作: 基于训练出的目标检测模型,搭配Pyside6制作的UI界面,用python开发了一款界面简洁的水面目标物检测识别系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。这不仅提升了系统的可用性和用户体验,还使得检测过程更加直观透明,便于结果的实时观察和分析。此外,GUI还可以集成其他功能,如检测结果的保存与导出、检测参数的调整,从而为用户提供一个全面、综合的检测工作环境,促进智能检测技术的广泛应用。
软件初始界面:

检测结果如下图:
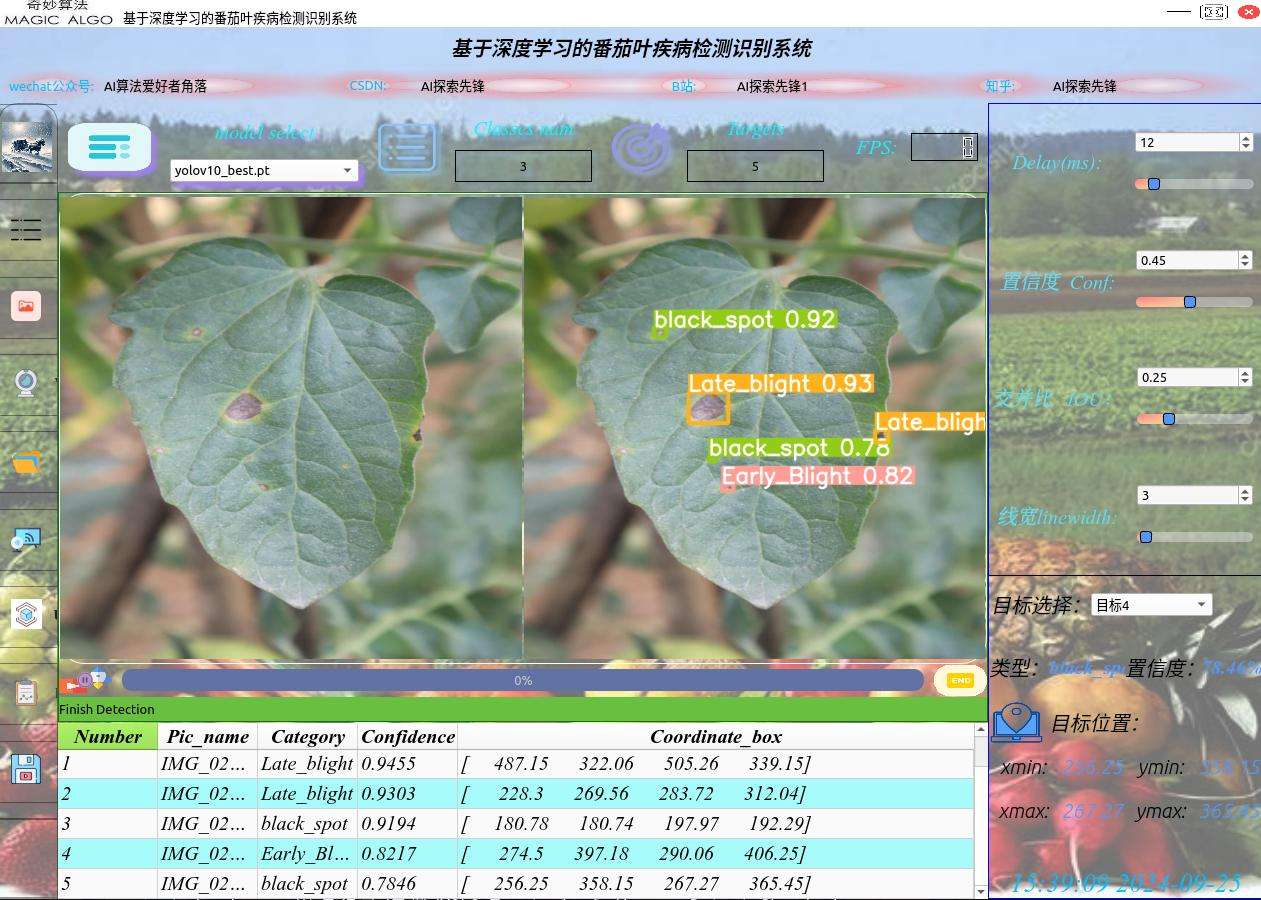
三、软件功能介绍
软件主要功能
-
可用于实际场景中水面目标物检测,分为7类检测类别:0: Bacterial_Spot、1: Early_Blight、2: Healthy、3: Late_blight、4: Leaf_Mold、5: Target_Spot、6: black_spot
-
支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
-
界面可实时显示目标位置、目标总数、置信度、用时等信息;
-
支持图片或者视频的检测结果保存;
界面参数说明
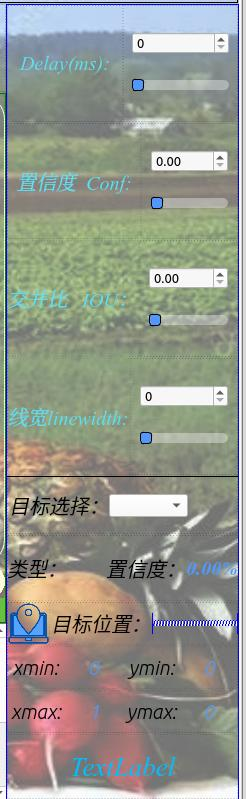
置信度阈值: 也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示;
交并比阈值: 也就是目标检测时的iou参数,只有目标检测框的交并比大于该值,结果才会显示;
线宽: 表示在绘制结果时,绘制框的线宽;
Delay: 代表运行时展示的延长时间;
检测结果说明


标签名称与置信度: 表示检测图片上标签名称与置信度;
总目标数: 表示画面中检测出的目标数目;
目标选择: 可选择单个目标进行位置信息、置信度查看。
目标位置: 表示所选择目标的检测框,左上角与右下角的坐标位置。
主要功能说明
功能视频演示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









