







SORT:SIMPLE ONLINE AND REALTIME TRACKING
Alex Bewley†, Zongyuan Ge†, Lionel Ott⋄, Fabio Ramos⋄, Ben Upcroft†
Queensland University of Technology†, University of Sydney⋄
ICIP 2016
0.背景知识
MOT(多人跟踪问题)大多是采用先检测后跟踪的框架,即利用目标检测网络,比如YOLO、FasterRCNN对视频中的每一帧进行检测得到目标检测框,接下来的任务便是如何将帧与帧之间的检测框对应起来。有两种方法:一类是model-free的方法,一类是tracking by detection的方法。前者通过初始化目标,在后续帧中只跟踪已有的目标,这样会导致新出现的物体没办法跟踪。后者是每隔几帧就用检测结果和现有跟踪结果做匹配。
SORT最主要的思想在于对检测出的每个物体建立一个独立于其他物体和相机运动的线性恒速模型,利用卡尔曼滤波法预测当前帧每个物体的状态量(预测值),再利用匈牙利算法与目标检测模型对当前帧的检测状态(观测值)进行数据关联。
0.1匹配问题和匈牙利算法
最大匹配:所含匹配边数最多的匹配;
完美匹配:图中所有的顶点都是匹配点,完美匹配一定是最大匹配;
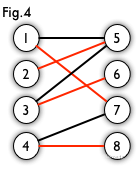
匈牙利算法:核心思想是回溯+贪心
详见:
假如这四个人有如下可以匹配的状态,寻找最大匹配的情况。
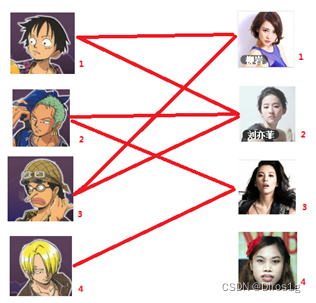
1.先给一号男生找一号女生做预匹配。
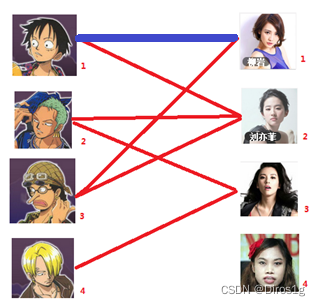
2.同理给二号找二号女生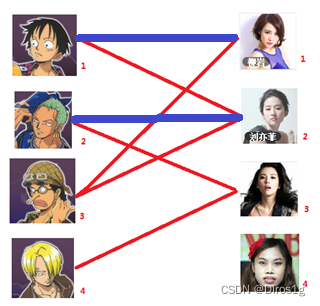
3.但是目前三号男生无法再进行匹配了,但是三号在图中是联通的,所以进行回溯。打断一号原有的匹配状态:
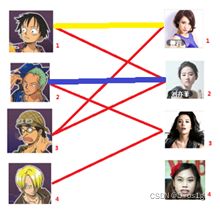
三号可以匹配了但是一号又无法匹配,再回溯
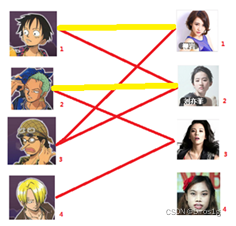
4.最终二号现在和三号相匹配了,在其基础上重新进行匹配:
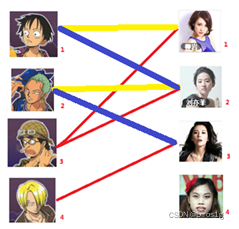
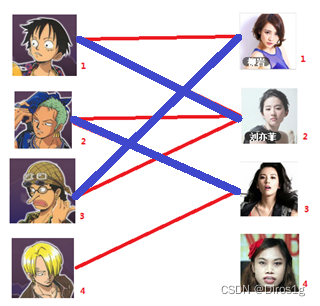
5.最终对于四号不论如何进行回溯,只能维持匹配度为三的解,此时就是最大匹配状态。
bool find(int x){
int i,j;
for (j=1;j<=m;j++){ //扫描每个妹子
if (line[x][j]==true && used[j]==false)
//如果有暧昧并且还没有标记过(这里标记的意思是这次查找曾试图改变过该妹子的归属问题,但是没有成功,所以就不用瞎费工夫了)
{
used[j]=1;
if (girl[j]==0 || find(girl[j])) {
//名花无主或者能腾出个位置来,这里使用递归
girl[j]=x;
return true;
}
}
}
return false;
for (i=1;i<=n;i++)
{
memset(used,0,sizeof(used)); //这个在每一步中清空
if find(i) all+=1;
}
参考:https://blog.csdn.net/dark_scope/article/details/8880547
而MOT问题可以看作是一个数据关联问题,也就是匹配问题。
0.2卡尔曼滤波
卡尔曼滤波考虑的是线性问题,是将多维属性融合后进行预测的一个算法,是在不确定性的不断变化中寻求一个平衡
1.卡尔曼的相关性(先验信息):F状态转移矩阵,B控制矩阵就是对u的一个function,u是控制量,x_hat代表的是预测值(状态、属性)而不是实际值。这个是理想状态(独立同高斯分布)下卡尔曼滤波解决线性问题的公式,但是实际不是这样的。
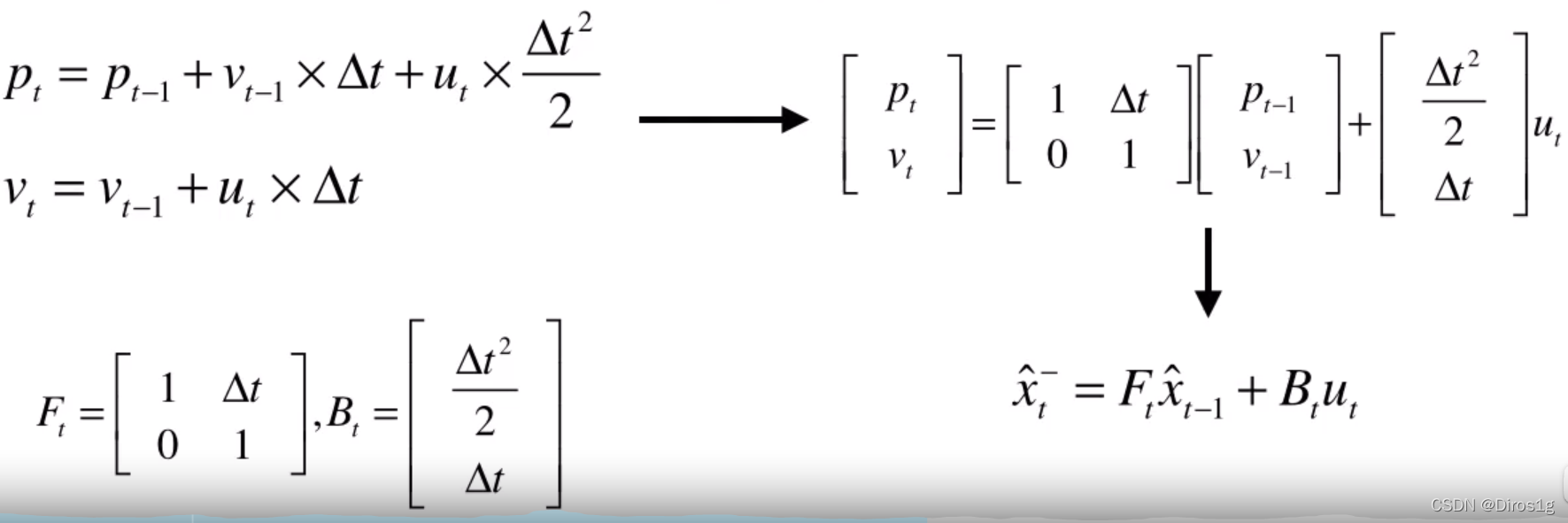
2.卡尔曼的不确定性:
一个二维数据的三种状态,但是其投影都是高斯分布,不能体现出二维的差异性。
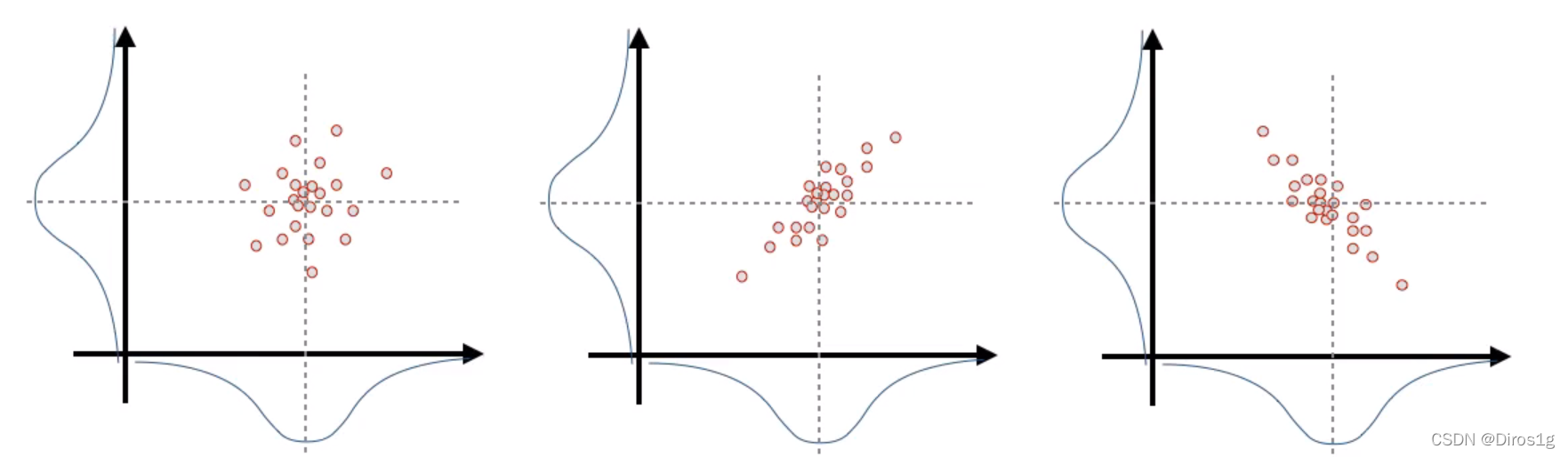
所以需要一个协方差矩阵来体现两个维度的相关性(不确定性,因为我们假设是高斯模型):
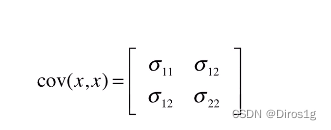
这样也能是的数据的分离度更大,我们用p来表示协方差阵。得到了协防矩阵(不相关度表示矩阵)的迭代公式:

最后再加一个偏置项Q,
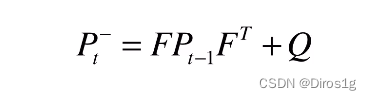
3.观测值(后验信息)
x是状态域信息(属性、feature),z是观察域信息(结果、score),两者不是一个维度的
x是原始属性,H是权重,v是抑制后验噪声的偏执
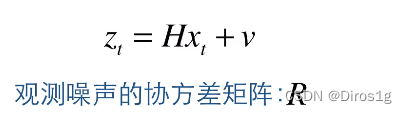
4.状态更新
之前得到的x_hat是带减号的,是不准确的,所以要修正一下:k_t:卡尔曼系数,z_t-H
x
t
x_t
xt_hat是残差。
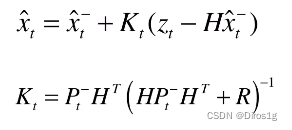
协方差矩阵的更新过程:
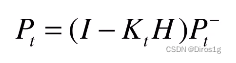
卡尔曼系数可以权衡预测模型和观察模型的权重(通过P和H),k_t越大越偏向观察模型。
其次卡尔曼系数可以把状态域的x和观察域的z这两个不同维度的信息融合在一起
总结:

0.3Tracks和Detections
Tracks: 是指在已经匹配成功的所有目标状态量(预测值),正是通过Tracks才能进行卡尔曼滤波的预测。
Detections: 是通过目标检测器获取的当前帧的检测框(观测值、真实值)
1.方法论
1.0算法流程
1)目标检测
2)将目标状态传递到未来帧中
3)将传入的状态信息与现有检测结果关联
4)迭代
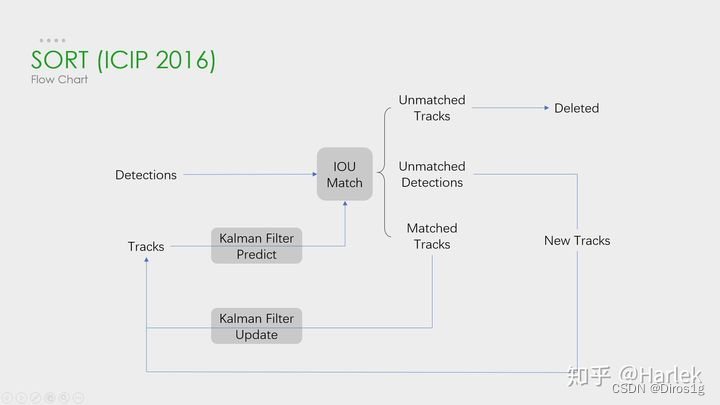
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
1.1检测模型
作者使用的是Faster R-CNN with VGG16
1.2 input
对于目标状态量,在视频中,每个移动的目标可以用一个目标框进行表示,每个目标框可以由以下变量进行表示:
![[公式]](https://img-blog.csdnimg.cn/80aafe38e5044f689f1f4a8aa8b25051.png)
其中u,v表示目标在图中的中心位置坐标,s 表示目标框的面积大小,r表示目标框的长宽比。u_·、v_·、s_·分别表示位置、面积的变化速率。
一般默认长宽比不变,如果没有检测,去掉后验信息,只用预测的状态域信息。
要提前准备两个信息:
1.某一目标i在1:t-1时刻下状态的预测值:
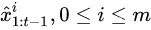
2.当前时刻t,目标检测出n个目标的检测信息:
在目标检测的时候检测不出来趋势信息。
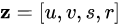
1.3Track和Detection
首先通过,转换矩阵H将状态域的信息转换成检测域的信息,方便度量目标间的距离
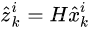
现在我们就有了两组信息:
1.t时刻的预测值:
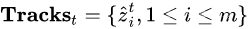
2.t时刻的观测值:
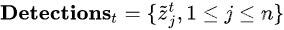
1.4匈牙利算法匹配
利用IOU来评估Tracks与Detections两两目标检测的距离,从而得到 IOU 关联矩阵,再通过使用匈牙利算法得到最佳优化。其中,当检测到的IOU与预测目标物间IOU小于IOUmin阈值时,检测的物体被拒绝分配。现在我们就将预测和观测一一匹配起来了。
1.5Tracks和Detections长度的情况
1.当Tracks.len()<Detections.len()的时候说明
说明有新的目标出现,而Tracks的策略里没有这个目标。对应方案是再新添一个tracks
2.当Tracks.len()=Detections.len()的时候说明
理想情况,两者刚好可以一一对应
3.当Tracks.len()>Detections.len()的时候说明
说明有目标再检测阶段被遮挡住了,对应方案是删掉该tracks。
1.6递归
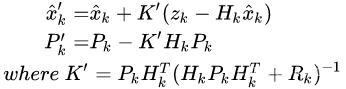
2.总结
本文提出了一种简单的在线跟踪框架,着重于帧到帧的预测和关联。跟踪质量高度依赖于检测性能,通过利用检测方面的最新发展,仅用经典跟踪方法就可以实现最先进的跟踪质量。
作者觉得未来的工作将研究一个检测和跟踪紧密耦合的框架。
参考:
https://zhuanlan.zhihu.com/p/378388675














 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









