







 本文介绍的CCNet是一种语义分割方法,它通过交叉关注模块有效地捕捉全局上下文信息,解决了传统FCN方法的局限。相比PSPNet,CCNet在Cityscapes、ADE20K和COCO等数据集上表现出优越性能。模型结构包含ResNet-101作为backbone,结合两个递归的criss-cross attention modules,实现了高效且全面的contextual information获取。
本文介绍的CCNet是一种语义分割方法,它通过交叉关注模块有效地捕捉全局上下文信息,解决了传统FCN方法的局限。相比PSPNet,CCNet在Cityscapes、ADE20K和COCO等数据集上表现出优越性能。模型结构包含ResNet-101作为backbone,结合两个递归的criss-cross attention modules,实现了高效且全面的contextual information获取。
CCNet: Criss-Cross Attention for Semantic Segmentation
简述:
目前,语义分割的主流方法多为以FCN为基础的网络,它们天生局限于局部接受域和短期上下文信息。由于语境信息的不足,这些限制对基于模糊语言的方法产生了很大的负面影响。随后的带有金字塔池模块的PSPNet来捕获上下文信息同样没有达到预期的效果。本文提出CCNet,利用当前的两个交叉关注模块,实现领先性能的分段基准,包括Cityscapes, ADE20K和MSCOCO。
问题or相关工作:
CCNet有明显的两个优势:1是计算量小,仅(H+W-1)元素
2递归方式用CCNet,对一个像素捕捉到全局的contextual information
模型:
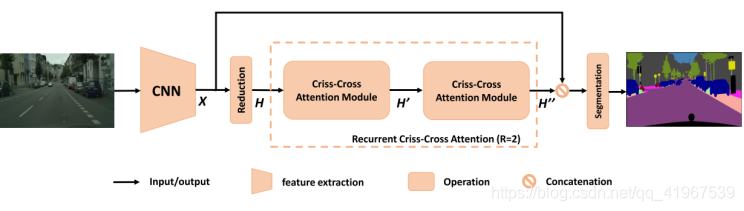
CCNet框架解读:照片输入进网络后,先选用ResNet-101作为backbone,backbone最后两个stage的stride改为1,同时用洞卷积扩大感受野,得到的特征图X是原图的1/8;随后经过1×1卷积降维,得到H;H经过一个criss-cross attention module得到H’,此时H’中的每个位置捕捉到和u在同一行或同一列的context information;H`经过一个相同结构,相同参数的CC module,得到H’’,在H’’中的每个位置,捕捉的是全局性的context information;最后将X与H’’级联,经过分割层得出结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









