






模型介绍
Attention U-Net的结构类似于U-Net,由编码器和解码器组成。编码器通过卷积和池化操作逐渐降低特征图的分辨率,提取图像的高层次特征。解码器则通过上采样和跳跃连接操作将特征图恢复到原始分辨率,并生成与输入图像相同大小的分割结果。
不同之处在于Attention U-Net在解码器中加入了注意力机制。注意力机制可以让模型在生成分割结果时更加关注图像中的重要区域,从而提高分割效果。具体来说,Attention U-Net使用了SE(Squeeze-and-Excitation)模块,该模块可以自适应地学习每个通道的重要性权重,并将这些权重应用于特征图中的每个位置。
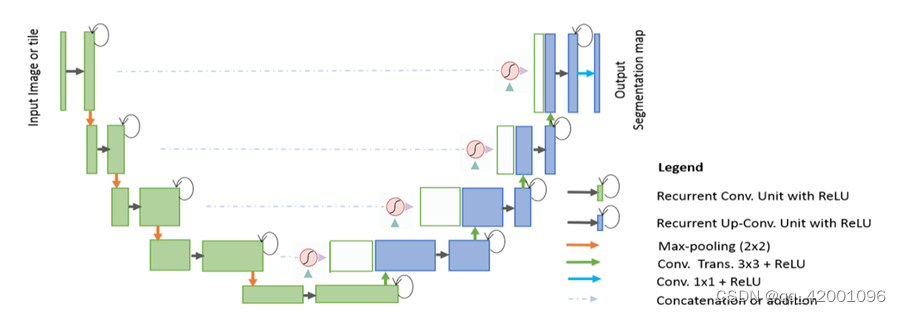
模型优势在于Attention U-Net相较于传统的U-Net模型:
更好的特征提取能力:Attention U-Net在编码器中使用了SE模块,可以自适应地学习每个通道的重要性权重,并将这些权重应用于特征图中的每个位置。这使得Attention U-Net能够更好地捕捉图像中的重要特征,提高特征提取能力。
更准确的分割结果:由于注意力机制的加入,Attention U-Net可以更好地关注图像中的重要区域,从而提高分割精度。
更少的参数和更快的训练速度:由于注意力机制的引入,Attention U-Net可以使用更少的参数来达到更好的分割效果,从而减少了模型的复杂度。此外,Attention U-Net在训练时也可以更快地收敛,加速了训练速度。
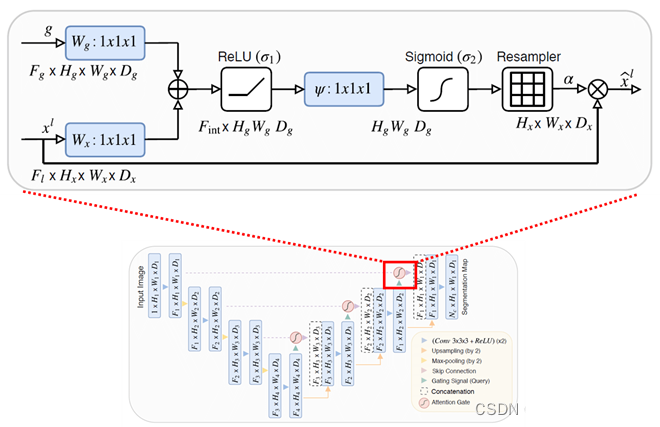
主要工作
1. 数据集的处理
数据准备:下载Cityscapes数据集并进行预处理,包括图像的裁剪、缩放和标签的转换等。
2. 模型的构建和训练
模型选择:选择Attention U-Net作为图像分割模型,并根据需要调整模型的超参数,如学习率、损失函数等。
模型训练:使用准备好的Cityscapes数据集对Attention U-Net模型进行训练,并根据需要进行模型微调。
模型评估:使用测试集对训练好的Attention U-Net模型进行评估,计算分割精度、召回率和F1值等指标。
注意力的本质是神魔?
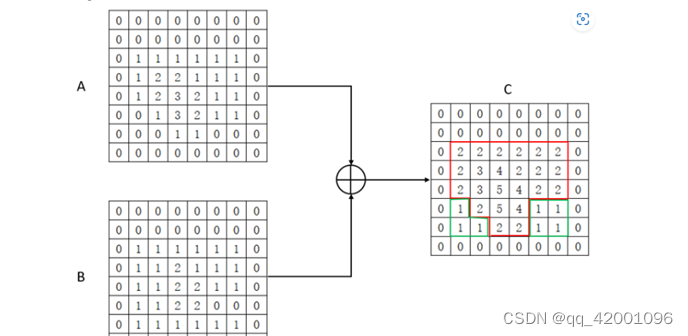
从上图也可以看出
进行卷积操作后的A、B为什么要有相同的尺寸大小,否则无法进行加运算。我们从C中也可以看出,A+B实际上将相同的感兴趣区域的信号加强了(红色部分),各自不同的区域(绿色区域)也在其中作为辅助或是补充存在在C中(这样其实也保存了一定的回旋余地)。
代码详解
Main.py分别加载训练数据集,测试数据集
train_loader = get_loader(image_path=config.train_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
mode='train',
augmentation_prob=config.augmentation_prob)
valid_loader = get_loader(image_path=config.valid_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
mode='valid',
augmentation_prob=0.)
test_loader = get_loader(image_path=config.test_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
mode='test',
augmentation_prob=0.)
Network.py 按照顺序构建上采样和卷积块
class U_Net(nn.Module):
def __init__(self,img_ch=3,output_ch=1):
super(U_Net,self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2)
self.Conv1 = conv_block(ch_in=img_ch,ch_out=64)
self.Conv2 = conv_block(ch_in=64,ch_out=128)
self.Conv3 = conv_block(ch_in=128,ch_out=256)
self.Conv4 = conv_block(ch_in=256,ch_out=512)
self.Conv5 = conv_block(ch_in=512,ch_out=1024)
self.Up5 = up_conv(ch_in=1024,ch_out=512)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512,ch_out=256)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256,ch_out=128)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128,ch_out=64)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0)
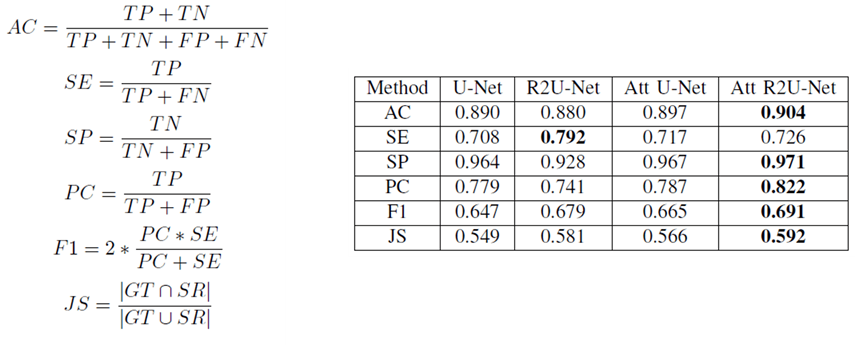
模型测试
论文中和其他网络的对比,可以看到其效果最好


Intel 架构的使用
我用于优化Attention U-Net模型的训练和推理过程,提高模型的性能和效率。使用了Intel Distribution of OpenVINO Toolkit将Attention U-Net模型转换为OpenVINO格式,以便在Intel CPU、GPU和VPU等不同硬件上进行推理。
使用Intel Math Kernel Library (MKL)或Intel oneDNN优化Attention U-Net模型的训练过程,提高训练速度和效率。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









