







Pytorch笔记:RNN 循环神经网络 (回归)
代码实现
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
TIME_STEP = 10 # rnn time step
INPUT_SIZE = 1 # rnn input size
LR = 0.02 # learning rate
# show data
steps = np.linspace(0, np.pi*2, 100, dtype=np.float32) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
plt.plot(steps, y_np, 'r-', label='target (cos)')
plt.plot(steps, x_np, 'b-', label='input (sin)')
plt.legend(loc='best')
plt.show()
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=32, # rnn hidden unit
num_layers=1, # number of rnn layer
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(32, 1)
def forward(self, x, h_state):
# x (batch, time_step, input_size)
# h_state (n_layers, batch, hidden_size)
# r_out (batch, time_step, hidden_size)
r_out, h_state = self.rnn(x, h_state)
outs = [] # save all predictions
for time_step in range(r_out.size(1)): # calculate output for each time step
outs.append(self.out(r_out[:, time_step, :]))
return torch.stack(outs, dim=1), h_state
# instead, for simplicity, you can replace above codes by follows
# r_out = r_out.view(-1, 32)
# outs = self.out(r_out)
# outs = outs.view(-1, TIME_STEP, 1)
# return outs, h_state
# or even simpler, since nn.Linear can accept inputs of any dimension
# and returns outputs with same dimension except for the last
# outs = self.out(r_out)
# return outs
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
h_state = None # for initial hidden state
plt.figure(1, figsize=(12, 5))
plt.ion() # continuously plot
for step in range(100):
start, end = step * np.pi, (step+1)*np.pi # time range
# use sin predicts cos
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32, endpoint=False) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # shape (batch, time_step, input_size)
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
prediction, h_state = rnn(x, h_state) # rnn output
# !! next step is important !!
h_state = h_state.data # repack the hidden state, break the connection from last iteration
loss = loss_func(prediction, y) # calculate loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
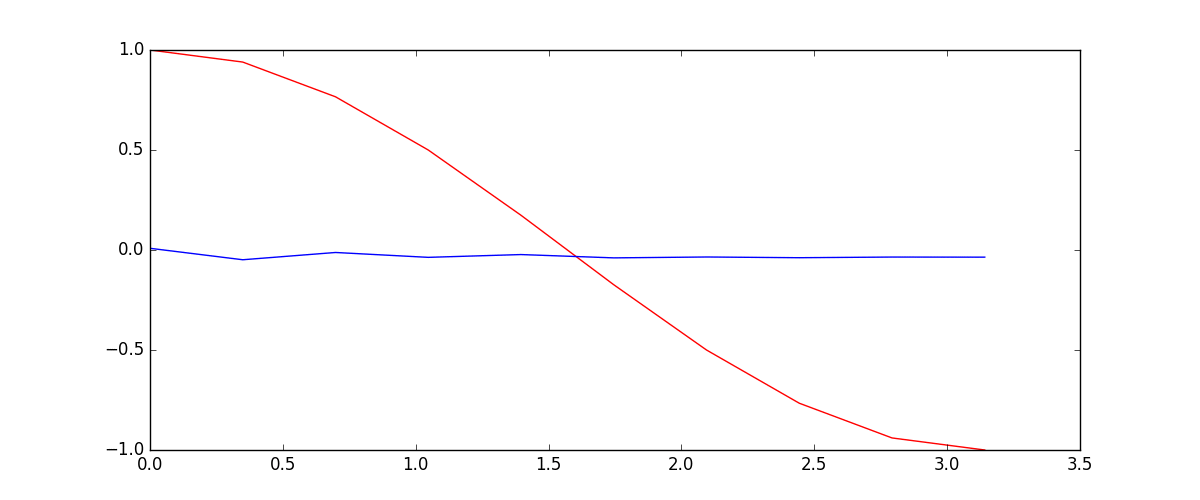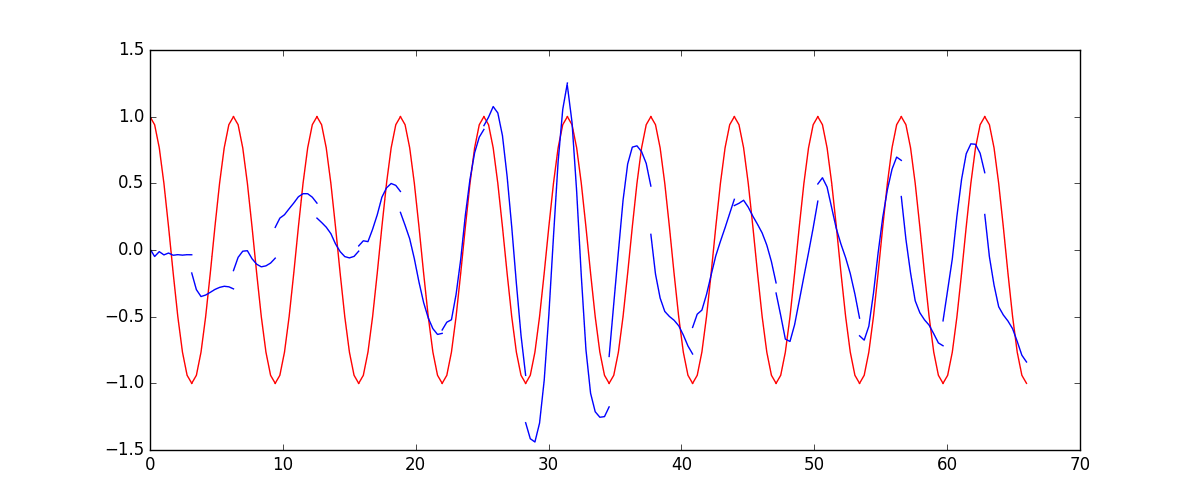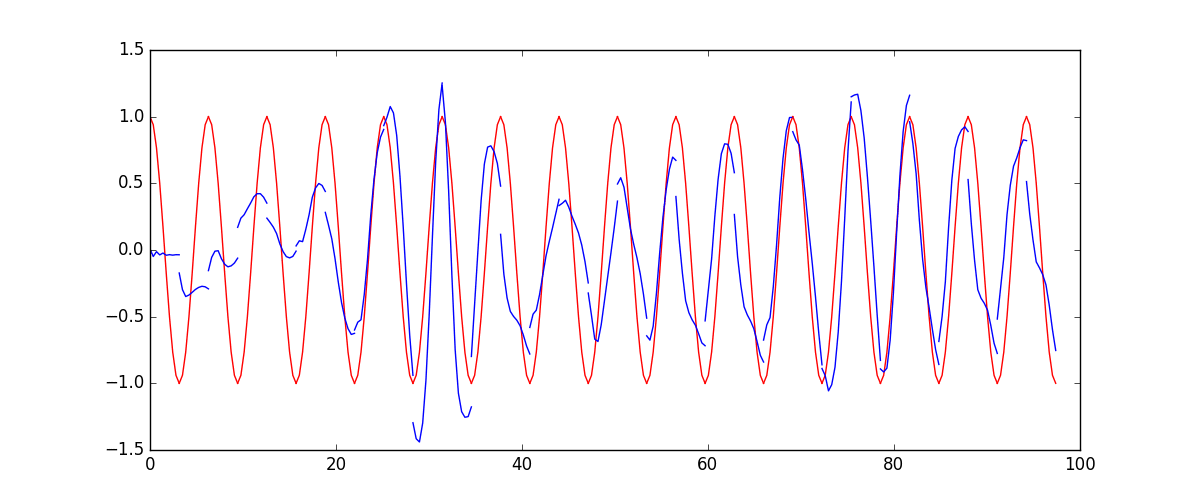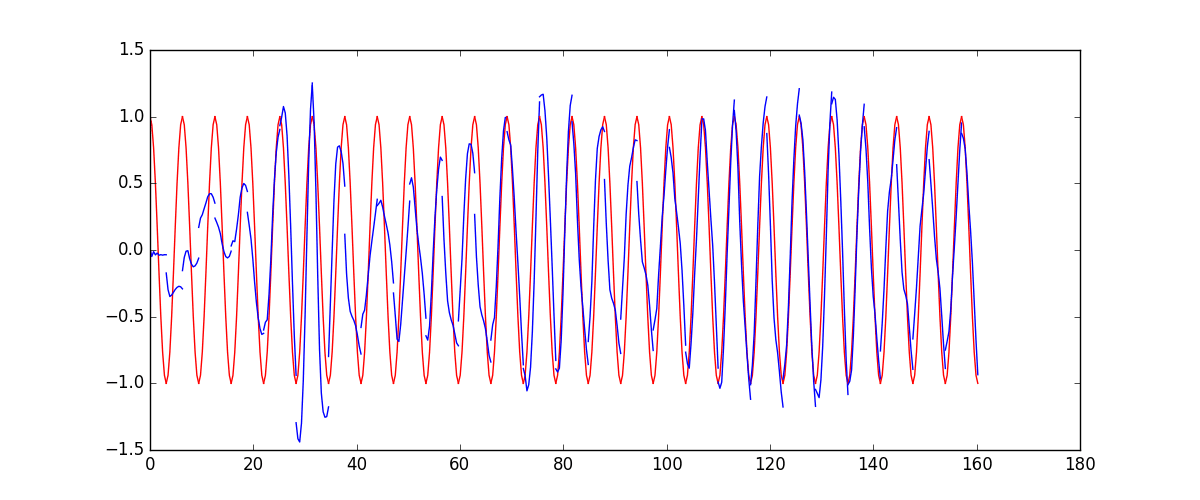
# plotting
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.draw(); plt.pause(0.05)
plt.ioff()
plt.show()
代码链接:莫烦 RNN 循环神经网络 (回归)
程序模型简图:

运行结果:
图片地址
模型参数输出
官网对模型各代码解释:
Variables
~RNN.weight_ih_l[k] – the learnable input-hidden weights of the k-th layer, of shape (hidden_size, input_size) for k = 0. Otherwise, the shape is (hidden_size, num_directions * hidden_size)
~RNN.weight_hh_l[k] – the learnable hidden-hidden weights of the k-th layer, of shape (hidden_size, hidden_size)
~RNN.bias_ih_l[k] – the learnable input-hidden bias of the k-th layer, of shape (hidden_size)
~RNN.bias_hh_l[k] – the learnable hidden-hidden bias of the k-th layer, of shape (hidden_size)
官网链接
系统参数UVW代码输出实现(为何输出只有一组,而不是十组,文末解释):
print(rnn._parameters.keys())
# odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0'])
参数共享
注意:在同一层隐藏层中,不同时刻的W,V,U均是相等地,这也就是RNN的参数共享。即RNN网络中,每一时刻的神经元是完全一样的,仅输入和上一时刻的状态输入h不同。
LSTM实现
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
TIME_STEP = 20 # rnn time step 一次性丢10组数据进行训练
INPUT_SIZE = 1 # rnn input size
LR = 0.02 # learning rate
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM(
input_size=INPUT_SIZE,
hidden_size=32, # rnn hidden unit
num_layers=1, # number of rnn layer
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(32, 1)
print(self.rnn)
def forward(self, x,h_state ,c_state):
r_out, (h_state ,c_state)= self.rnn(x, (h_state,c_state))
outs = [] # save all predictions
for time_step in range(r_out.size(1)): # calculate output for each time step
outs.append(self.out(r_out[:, time_step, :]))
return torch.stack(outs, dim=1), h_state,c_state
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
h_state = torch.randn(1,1,32) # for initial hidden state
c_state= torch.randn(1,1,32)
plt.figure(1, figsize=(12, 5))
plt.ion() # continuously plot
for step in range(100):
start, end = step * np.pi, (step + 1) * np.pi # time range
# use sin predicts cos
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32,
endpoint=True) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # shape (batch, time_step, input_size)
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
prediction, h_state ,c_state= rnn(x, h_state,c_state) # rnn output
# !! next step is important !!
h_state = h_state.data # repack the hidden state, break the connection from last iteration
c_state = c_state.data
loss = loss_func(prediction, y) # calculate loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
# plotting
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.draw();
plt.pause(0.05)
plt.ioff()
plt.show()
RNN与LSTM对比
TIME_STEP 选取20(超过10次,容易造成梯度消失或梯度爆炸),训练100次,结果如下:
RNN

LSTM
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}