







 本文介绍了视频特征提取的几种方法,包括基于单帧的CNN识别、CNN扩展网络、双路CNN、LSTM整合帧间信息以及3DCNN。这些方法通过捕捉时空信息、利用光流特征和LSTM的记忆单元来提高识别性能,尤其在运动丰富的视频中表现突出。3DCNN通过3维卷积保持时间域信息,增强了视频的区分度。
本文介绍了视频特征提取的几种方法,包括基于单帧的CNN识别、CNN扩展网络、双路CNN、LSTM整合帧间信息以及3DCNN。这些方法通过捕捉时空信息、利用光流特征和LSTM的记忆单元来提高识别性能,尤其在运动丰富的视频中表现突出。3DCNN通过3维卷积保持时间域信息,增强了视频的区分度。
视频特征提取
1. 基于单帧的识别方法
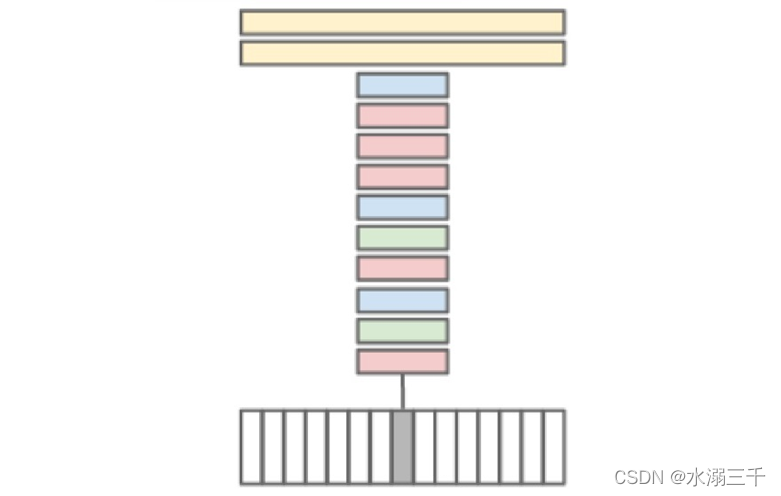
一种最直接的方法就是将视频进行截帧,然后基于图像单帧的进行deep learninig 表达, 如下图所示,视频的某一帧通过网络获得一个识别结果。下图为一个典型的CNN网络,红色矩形是卷积层,绿色是归一化层,蓝色是池化层 ,黄色是全连接层。然而一张图相对整个视频是很小的一部分,特别当这帧图没有那么的具有区分度,或是一些和视频主题无关的图像,则会让分类器摸不着头脑。因此,学习视频时间域上的表达是提高视频识别的主要因素。当然,这在运动性强的视频上才有区分度,在较静止的视频上只能靠图像的特征了。
2. 基于CNN扩展网络的识别方法
它的总体思路是在CNN框架中寻找时间域上的某个模式来表达局部运动信息,从而获得总体识别性能的提升。下图是网络结构,它总共有三层,在第一层对10帧 (大概三分之一秒)图像序列进行MxNx3xT的卷积(其中 MxN是图像的分辨率,3是图像的3个颜色通道,T取4,是参与计算的帧数,从而形成在时间轴上4个响应),在第2、3层上进行T=2的时间卷积,那么在第3层包含了这10帧图片的所有的时空信息。该网络在不同时间上的同一层网络参数是共享参数的。
它的总体精度在相对单帧提高了2%左右,特别在运动丰富的视频,如摔角、爬杆等强运动视频类型中有较大幅度的提升,这从而也证明了特征中运动信息对识别是有贡
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









