







写在前面的
上一篇的链接:
《强化学习与最优控制》学习笔记(一):确定性动态规划和随机性动态规划
这篇文章主要讲一下强化学习(RL)和最优控制的一些术语,其实稍微了解强化学习的小伙伴们在学习这本书的时候就会发现,RL和DP虽然优化的目标不一样(RL追寻奖励值的最大化,DP追求开销的最小化),但是无论是在结构上、控制系统上还是在方法上,使用的思想都可以一一对应,如下图所示,这只是我在网上找的一幅图片,本文会就书上1.4节的内容的进行更详细的说明。
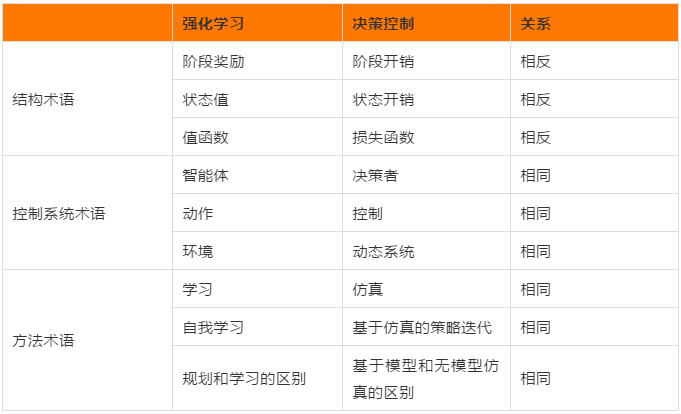
1.4 强化学习与最优控制——相关术语
正如写在前面的所说,在基于RL的讨论(使用人工智能相关术语)和基于DP的讨论(使用最优控制相关术语)中,语言和重点存在重大差异。本书中使用的术语是DP和最优控制中的标准术语,为了防止读者对RL或最优控制术语感到困惑,本书提供了RL中常用的选定术语及其最优控制对应术语的列表。
(a) Agent(智能体) = Decision maker or controller(决策者或控制器,输出决策或控制的模型).
(b) Action(动作) = Decision or control(决策或控制).
(c) Environment(环境) = System(系统).
(d) Reward of a stage (阶段奖励) = (反义) Cost of a stage (阶段花销).
(e) State value (状态值,在这个状态下开始能得到的奖励)= (反义) Cost starting from a state (在这个状态下开始花的开销).
(f) Value (or reward, or state-value) function (价值函数) = (反义) Cost function (成本函数).
(g) Maximizing the value function (最大化价值函数) = Minimizing the cost function (最小化成本函数).
(h) Action (or state-action) value (动作或状态-动作值)= Q-factor (or Q-value) of a state-control pair (Q-value is also used often in RL.)(状态-控制对的Q因子或Q值).
(i) Planning(规划) = Solving a DP problem with a known mathematical model(用已知的数学模型解DP问题,就是知道系统的动态特性,在确定性系统中就是已知).
(j) Learning(学习) = Solving a DP problem without using an explicit mathematical model.(不需要显式的数学模型来解DP问题,在model-free强化学习中其实经常通过采样大量与环境交互的数据来近似系统的动态特性).
(k) Self-learning (or self-play in the context of games)(自学习) = Solving a DP problem using some form of policy iteration.(用某种策略迭代的形式求解DP问题,在强化学习中就是通过策略评估和策略提升来找到最优的策略)
(l) Deep reinforcement learning(深度强化学习) = Approximate DP using value and/or policy approximation with deep neural networks(就是用神经网络来近似DP问题).
(m) Prediction (预测)= Policy evaluation(策略评估).
(n) Generalized policy iteration (广义策略迭代)= Optimistic policy iteration(最优策略迭代).
(o) State abstraction (状态简化)= Aggregation(聚集,个人理解就是将相似的某些状态都当成相同的状态).
(p) Learning a model (学习模型) = System identification(系统识别,就是找系统的动态特性).
(q) Episodic task or episode = Finite-step system trajectory (就是从起始状态到最后状态(有限时间步的系统)的一段轨迹).
(r) Continuing task = Infinite-step system trajectory (就是从起始状态到最后状态(无限时间步的系统)的一段轨迹).
(s) Backup = Applying the DP operator at some state.
(t) Sweep = Applying the DP operator at all states.
(u) Greedy policy with respect to a cost function = Minimizing policy in the DP expression defined by
.(贪婪策略,直接根据当前的
来选择策略,即不考虑未来的
)
(v) Afterstate = Post-decision state.
(w)Experience replay = Reuse of samples in a simulation process.(在学习策略时我们会将与环境交互的一些数据放在经验池里,然后定期从中抽样出来学习)
有些术语会在后面的内容中讲到(我还没看到,所以不太清楚怎么解释,后续会更新一下)。
写在后面的
下一章链接:

















 5311
5311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











