







 本文详细探讨Transformer的Encoder和Decoder,包括Add & Norm的目的、Positional Encoding的原理与进化、FFN的作用以及Decoder中的Object query机理。分析了为何在Transformer中不适用BN,并解释了Positional Encoding如何处理不同长度的序列,以及Feed Forward层增强表示能力的重要性。
本文详细探讨Transformer的Encoder和Decoder,包括Add & Norm的目的、Positional Encoding的原理与进化、FFN的作用以及Decoder中的Object query机理。分析了为何在Transformer中不适用BN,并解释了Positional Encoding如何处理不同长度的序列,以及Feed Forward层增强表示能力的重要性。
由于讲解如何搭建Encoder和Decoder的文章有很多,因此本节将围绕为什么做分析而非怎么做。主要涉及到几个细节问题:Encoder中Add操作及目的、Norm操作及目的、不用Norm可不可以、为什么将BN不用于transformer任务、Feed Forward操作及目的、Positional Encoding的原理和进化、Decoder中Object query机理。
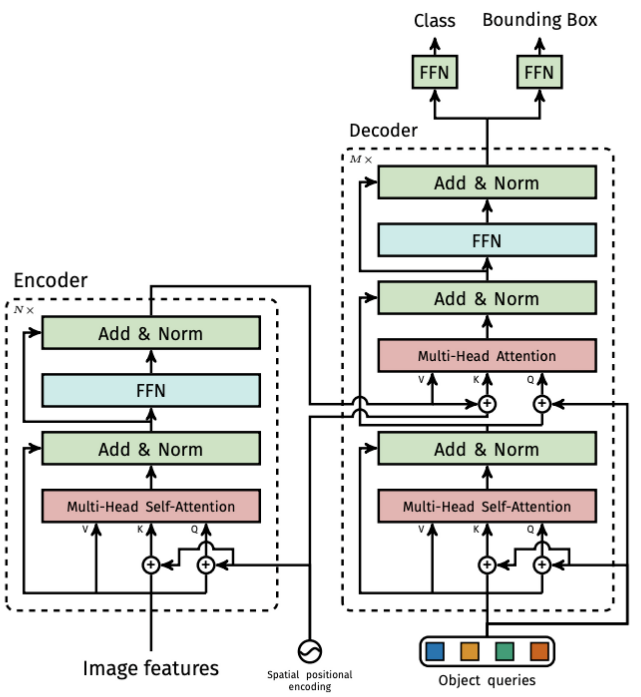
Encoder分解之Add & Norm
- Add操作

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1479
1479







