







2018.11
1. Institute for Applied Computational Science 2. Harvard University 3. Google Brain
代码:https://sites.google.com/ view/struct2depth.
论文:https://arxiv.org/pdf/1811.06152.pdf
摘要:
对于室内外的机器人导航来说,学习从RGB图像中估计出场景深度是一个挑战性的任务。本文提出了一个新的方法,能够对移动物体建模并可以在数据领域进行转换(比如从室外场景到室内)。
核心思想:在学习过程中引入一个几何结构,过对场景和单独物体进行建模。 相机的自运动和物体运动从单目视频输入中学习。在此基础上,提出了一种改进的在线学习方法应用到未知领域。
使用神经网络对每张图像进行有监督稠密深度预测已经很成功了(Eigen, Puhrsch, and Fergus 2014; Laina et al. 2016; Wang, Fouhey, and Gupta 2015; Li, Klein, and Yao 2017) ,并且要比手工特征的方法要好很多(Ladicky, Zeisl, and Pollefeys 2014; Karsch, Liu, and Kang 2014a)。然而,监督学习需要的数据很难获得,无监督方法由此开始进行,并证明了无监督深度估计模型要比基于传感器监督的方法要好 (Zhou et al. 2017; Garg, Carneiro, and Reid 2016) ,主要由于传感器的读取问题,如:丢失数据或者产生噪声。这些问题目前已大大解决,通过使用立体对(Godard, Aodha, and Brostow 2017),或者在学习中分别训练光流模型 (Wang et al. 2018)。
我们提出的方法是对运动物体加上相机自运动的明确的3D运动模型,并引入一个多帧图像的在线改进模块进行学习来适应新环境。使用规定的处理运动的方法和一个新引入的物体大小约束(object size constraint),我们是第一个从单目设定中有效学习到高动态场景(highly dynamic scenes),我们的方法是:在学习过程中引入一个将物体在3D空间中进行表示以及将运动模型进行SE3转化的结构,这个过程是完全可微的并且由未标定的单目视频进行训练。
前期工作:
场景深度估计一直是视觉和机器人领域存在的问题,最近对image-to-depth估计问题产生了基于学习的概念,由于图像中含有丰富的特征表达,能够从原始数据中学习到(Eigen, Puhrsch, and Fergus 2014; Lainal 2016)。 这些方法比传统方法(Karsch, Liu, and Kang 2014b)效果更好,最初的无监督方法是由(Zhou et al. 2017; Garg, Carneiro, and Reid 2016) 提出的,并且没有用到深度或自运动作为监督信号。后续的工作使用单目设定(Yang et al. 2017; Yin 2018) 和立体对(Godard, Aodha, and Brostow 2017; Ummenhofer et al. 2017; Zhan et al. 2018; Yang et al. 2018a)来提高最初效果
但依旧没有解决在动态场景存在运动物体的实际问题,因此提出了光流模型(Yin 2018; Yang. 2018b; 2018a),分别进行训练并得到了一定进步 ,我们的方法与之前的相似,使用一个提前训练模型,然后使用场景的几何结构以及对所有物体的运动进行建模其中包括相机的自运动。自修复方法沿用之前的(Bloesch et al. 2018) ,使用低维表示将连续帧信息进行融合。
主要方法:
最主要的学习设置是按照(Zhou et al. 2017)的unsupervised learning of depth and ego-motion from monocular video,其监督的来源就是它的视频本身,我们提出的新方法能够通过物体运动对动态场景进行建模,还能够选择在线调整方法的学习过程。这两项之前没有关系,能够分别或一同进行训练。
-
问题设置
输入的RGB图像至少3帧连续图像,![]() ,以及内参矩阵
,以及内参矩阵![]() 。深度和自运动由学习非线性函数预测。
。深度和自运动由学习非线性函数预测。
深度函数:![]() 一个全卷积的encoder-decoder网络从一个单RGB帧输出一个稠密深度图
一个全卷积的encoder-decoder网络从一个单RGB帧输出一个稠密深度图![]()
自运动网络:![]() 将连续2帧RGB图像作为输入,生成出两帧图像间的SE3变换,如:6维变换矩阵
将连续2帧RGB图像作为输入,生成出两帧图像间的SE3变换,如:6维变换矩阵
![]() 的形状是
的形状是![]() ,指定帧之间的平移和旋转参数,E2→3同理。
,指定帧之间的平移和旋转参数,E2→3同理。
使用一个变换操作,将一帧图像变换到相邻的另一帧上,我们能够想象出一个场景从不同的相机角度看到的画面。由于场景的深度能够通过θ(Ii)得到,到下一帧的自运动ψE能够通过投影将场景变换到下一帧得到下一帧图像。
更具体来说就是使用一个可微图像变换操作(differentiable image warping operator)![]() 这里的
这里的![]() 是第J个重建图像,
是第J个重建图像,
我们可以将任意一个原始图像Ii 在给定相对估计深度Dj 和自运动估计![]() 后变换到Ij!
后变换到Ij!
实际上,φ是通过读取转换的图像像素坐标来完成变换操作,其中设置![]()
这里 ![]()
![]() 是投影的坐标。监督信号于是使用亮度损失对比投影场景到下一帧的
是投影的坐标。监督信号于是使用亮度损失对比投影场景到下一帧的![]() 与真实的RGB图像
与真实的RGB图像![]() ,比如使用重建损失
,比如使用重建损失![]()
-
算法基础
我们对我们的算法在(Zhou et al. 2017; Godard, Aodha, and Brostow 2018)基础上.建立了一个强的标准,其中重建损失计算的是:由前一帧和后一帧向中间帧转换的重建损失最小值:
![]()
由(Godard, Aodha, and Brostow 2018)提出,避免由于明显的遮挡/非遮挡的影响造成的惩罚项。
除此之外还用了SSIM loss(Wang et al. 2004):一个深度平滑项损失 以及在训练中应用深度归一化,在之前的(Zhou et al. 2017; Godard, Aodha, and Brostow 2017; Wang et al. 2018)工作中被证明有效。
其总损失在4个尺度上计算(αj为超参数):
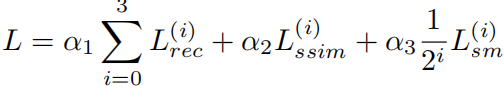
-
运动模型

我们的方法通过对每个物体的运动、自运动以及场景深度按标准进行建模得到一个3D几何结构。并且使用了一个改进方 法进行在线对模型修复,
我们引入了物体运动模型ψM 与自运动网络ψE结构相同,但是不同在于估计每个物体的运动是在3D空间。与自运动模型相似,将一个RGB序列作为输入,但是这是用提前计算好的实例分割mask进行填充。
运动模型:任务是学习去预测3D空间中每个物体的变换矩阵,生成在相对目标图像中可见物体的表现(appearance)。因此,计算变换的图像不仅是(Zhou et al. 2017)一样基于自运动的一个单独投影,而是一个序列的投影并且能够适当地进行结合。
固定的背景:由单张图像基于ψE生成的,然后所有的分割物体先根据ψE然后是ψM最初变化得到的表现被加在一起。
我们的方法:使用在2D图像空间的运动(Yin 2018) 使用光流,或者对3D空间能够明确学习的物体运动使用3D光流(Yang et al. 2018a),我们的方法不仅能够在3D空间对物体进行建模,还能学习到它们的运动,对每个场景和物体的深度进行建模都是有严格标准的。
我们定义instance-aligned segmentation masks(实例分割)对于每个在连续图像![]() 中潜在物体i为
中潜在物体i为![]() ,为了计算自运动,物体运动先从图像中被分割出来,更特别的是,定义了一个二进制mask来处理静态场景
,为了计算自运动,物体运动先从图像中被分割出来,更特别的是,定义了一个二进制mask来处理静态场景![]() 来移除所有与潜在运动物体有关的内容。
来移除所有与潜在运动物体有关的内容。![]() 为代表j>0,返回一个只代表物体j的二进制mask。
为代表j>0,返回一个只代表物体j的二进制mask。
在将序列喂入自运动模型之前,静态场景二进制mask通过元素乘积 应用到序列中的所有图像:
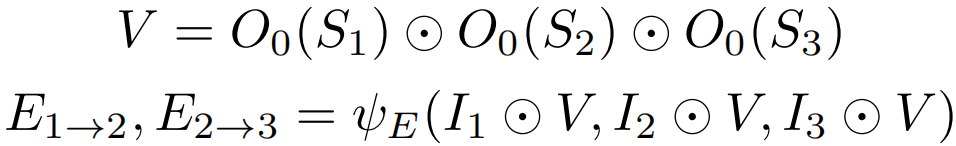
对于运动物体网络,首先应用自运动估计得到变换的序列![]() 以及
以及![]() , 其中自运动的影响已经被去除。假设深度和自运动估计正确,图像序列中未对齐的部分是由运动物体造成的。对潜在的运动物体标注是由一个没有经过相关数据集的训练的离线算法计算(He et al. 2017) (与之前方法相似不过最近使用的是光流 (Yang et al. 2018a))
, 其中自运动的影响已经被去除。假设深度和自运动估计正确,图像序列中未对齐的部分是由运动物体造成的。对潜在的运动物体标注是由一个没有经过相关数据集的训练的离线算法计算(He et al. 2017) (与之前方法相似不过最近使用的是光流 (Yang et al. 2018a))
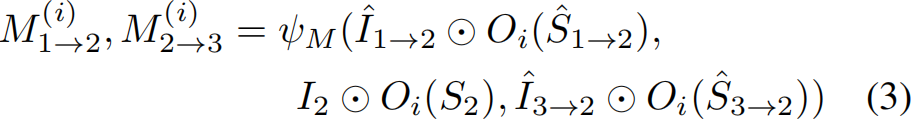
注意:尽管![]() 代表的是物体运动,它们实际上是对相机如何运动来解释物体表现进行建模,而不是直接物体运动进行建模。 实际3D运动向量是由追踪之前的体素(voxel)运动以及在相应区域内的物体运动变换之后获得的。
代表的是物体运动,它们实际上是对相机如何运动来解释物体表现进行建模,而不是直接物体运动进行建模。 实际3D运动向量是由追踪之前的体素(voxel)运动以及在相应区域内的物体运动变换之后获得的。
根据这些运动估计,执行了逆变换操作,根据估计的运动对物体进行移动,最终变换的结果是运动物体![]() 的单独变换以及自运动
的单独变换以及自运动![]() 的结合,整体的变换
的结合,整体的变换![]() 如下:
如下:
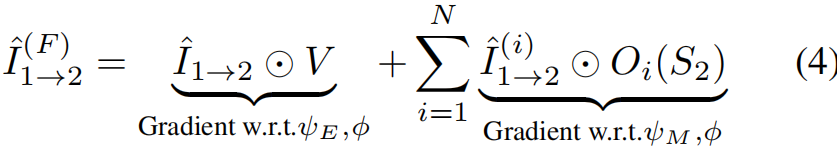
上式中,我们定义了每个部分的梯度。注意使用的mask确保了没有像素在最终变换结果中占用超过一次。然而,可能有些区域没有被填充,这些可以由最小损失计算来解决,我们的算法自动学习对于每个物体的单独3D运动,能够在推论中使用。
-
添加物体大小约束
之前工作的常见问题是:几乎以同样速度在前方运动的车辆总是会投影出无限的深度(比如:Godard, Aodha, and Brostow 2018; Yang et al. 2018a),这是由于在前方的物体显示出几乎没有变化的运动,并且如果网络估计这是无限远的区域,重投影误差减少到0,会认为这是正确的区域。之前的方法指出这一问题但是没有解决,只是使用立体图像来加强训练数据集(Godard, Aodha, and Brostow 2018) (Yang et al. 2018a) (Wang et al. 2018)。然而,立体图像不是和单目视频一样容易获得。
- 把一个物体放得非常远并且预测出非常大的动作,并假设非常大
- 把一个物体放的非常近并且预测出很小的运动,假设它很小
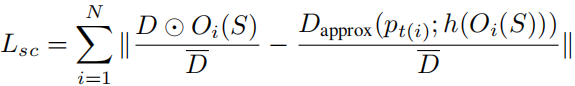
-
测试时间调整模型
有一个单图像深度估计器的好处就是它能够广泛应用,然而,当在图像序列上运行连续深度估计时总是不重合或者不连续,产生原因由两种:
- 相邻图像之间的尺度不一致,由于我们以及有关模型没有对全局尺度进行考虑
- 深度估计的时间连续性低
我们主张修复模型中在推理中不需要的权重,并且能够有效适应在线调整方法,特别是实际的自动系统。我们还在进行推理过程中保持模型的训练,通过有效进行在线优化处理这些问题。在做这些的时候,我们还展示了尽管用了有限时间分辨率(3帧图像)我们能够明显增强深度估计的质量,还能够实时在线进行,一帧的延迟通常不予考虑。在线修复以N步运行(对于所有的实验N = 20);N在充足在线修复和防止过训练上是一个妥协的决定数。在线修复方法能够在上述模型中全部应用。















 1127
1127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









