







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
深度学习是一种强大而灵活的方法,框架,它提供了一种在 Python 中构建、训练和评估神经网络的无缝方法。在本文中,我们将详细介绍使用 PyTorch 自定义一个深度学习模型框架、并训练深度学习模型的步骤以及一个示例。
神经网络是一种机器学习模型,其灵感来自人脑的结构和功能。它由多层相互连接的节点(称为神经元)组成,用于处理和传输信息。神经网络特别适合图像和语音识别、自然语言处理以及基于大量数据进行预测等任务。
下面是神经网络的基本结构:包含输入层、隐藏层与输出层。

安装PyTorch
要安装 PyTorch,您需要在计算机上安装 Python 和 pip(Python 的包管理器)。
您可以通过在命令提示符或终端中运行以下命令来安装 PyTorch 和必要的库:
pip install torch
pip install torchvision
pip install torchsummary
MNIST 数据集介绍
MNIST 数据集是手写数字的数据集,由 60,000 个训练示例和 10,000 个测试示例组成。每个示例都是一个 28×28 的手写数字灰度图像,值范围从 0(白色)到 255(黑色)。每个示例的标签是图像所代表的数字,值范围从 0 到 9。
它是常用于训练和评估图像分类模型的数据集,尤其是在计算机视觉领域。它被认为是深度学习的“Hello World”数据集,因为它很小且相对简单,但仍需要大量的预处理和模型架构设计才能实现良好的性能。
自定义模型与训练步骤
步骤 1:导入必要的库
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torchsummary import summary
import torch.nn.functional as F
步骤2:加载MNIST数据集
首先,我们需要导入必要的库并加载数据集。我们将使用 PyTorch 中的内置 MNIST 数据集,可以使用 torchvision 库轻松加载该数据集。
注:pytorch内置了Mnist数据集,可以通过以下代码直接下载,也可以直接使用我提供的数据集。
# Load the MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
在上面的代码中,torchvision.datasets.MNIST 函数用于加载数据集,它接受几个参数,例如:
- root:数据集将保存的目录
- train:一个布尔标志,指示是否加载训练集还是测试集。
- transform:应用于数据的变换,变为张量
- download:一个布尔标志,指示如果在根目录中找不到数据集是否下载。
步骤 3:构建自己的分类模型
接下来,我们自己定义一个简单的深度学习模型结构。在这个例子中,我们将使用一个简单的前馈神经网络
- Python3
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.dropout1(x)
x = self.pool(F.relu(self.conv2(x)))
x = self.dropout2(x)
x = x.view(-1, 64 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
Classifier 类继承自 PyTorch 的 nn.Module 类,并定义 CNN 的架构。创建类的实例时会调用 init 方法,并设置网络的各层。
- self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1):此行创建一个 2D 卷积层,该层具有 1 个输入通道、32 个输出通道、内核大小为 3、填充为 1。卷积层将一组过滤器(也称为内核)应用于输入图像以从中提取特征。
- self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1):此行创建另一个 2D 卷积层,具有 32 个输入通道、64 个输出通道、内核大小为 3、填充为 1。该层连接到第一个卷积层的输出,允许网络从前一层的输出中学习更复杂的特征。
- self.pool = nn.MaxPool2d(2, 2):此行创建一个最大池化层,其内核大小为 2,步长为 2。最大池化是一种下采样操作,它从每个输入通道的小邻域中选择最大值。它有助于降低数据的维度,降低计算成本并有助于防止过度拟合。
- self.dropout1 = nn.Dropout2d(0.25):此行创建一个概率为 0.25 的 dropout 层。Dropout 是一种正则化技术,可在训练期间随机丢弃一些神经元,有助于减少过度拟合。
- self.dropout2 = nn.Dropout2d(0.5):此行创建另一个概率为 0.5 的 dropout 层
- self.fc1 = nn.Linear(64 * 7 * 7, 128):此行创建一个完全连接(线性)层,具有 64 * 7 * 7 个输入特征和 128 个输出特征。完全连接层用于根据前面各层学习到的特征做出最终预测。
- self.fc2 = nn.Linear(128, 10):此行创建另一个具有 128 个输入特征和 10 个输出特征的完全连接层。此层将产生具有 10 个类的网络的最终输出。forward 方法定义了
接下来是网络的前向传递方法。它接受输入 x,并应用 init 方法中各层定义的一系列操作。
- x = self.pool(F.relu(self.conv1(x))):此行将 ReLU 激活函数 (F.relu) 应用于第一个卷积层 (self.conv1) 的输出,然后将最大池化 (self.pool) 应用于结果。
- x = self.dropout1(x):此行将 dropout 应用于第一个池化层的输出。
- x = self.pool(F.relu(self.conv2(x))):此行将 ReLU 激活函数应用于第二个卷积层(self.conv2)的输出,然后对结果应用最大池化。
- x = self.dropout2(x):此行将 dropout 应用于第二个池化层的输出。
- x = x.view(-1, 64 * 7 * 7):此行将张量 x 重塑为一维张量,其中 -1 表示张量中元素的数量是从其他维度推断出来的。
- x = F.relu(self.fc1(x)):此行将 ReLU 激活函数应用于第一个全连接层(self.fc1)的输出。
- x = self.fc2(x):此行将最终的全连接层(self.fc2)应用于前一层的输出并返回结果,该结果将成为网络的最终输出。
- 这种 CNN 架构很简单,可以作为更复杂任务的起点。但是,可以通过添加更多层、使用不同类型的层或调整超参数来改进它,以获得更好的性能。
使用GPU 与 CPU
判断使用GPU还是CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
输出:
device(type='cuda')
这段代码用于选择我们应该在哪个设备上运行我们的模型。如果我们在 google colab 中运行我们的代码,我们可以检查“cuda”设备是否可用,如果可用,我们可以使用它,否则我们可以使用普通 CPU。
CUDA 是针对运行 ML 模型而优化的 GPU
查看模型结构
定义模型后,我们可以使用该类创建模型对象并查看模型的基本结构。 summary 选项可用于打印模型的摘要,如下所示。
- Python3
# Instantiate the model
model = Classifier()
# Move the model to the GPU if available
model.to(device)
summary(model, (1, 28, 28))
输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 28, 28] 320
MaxPool2d-2 [-1, 32, 14, 14] 0
Dropout2d-3 [-1, 32, 14, 14] 0
Conv2d-4 [-1, 64, 14, 14] 18,496
MaxPool2d-5 [-1, 64, 7, 7] 0
Dropout2d-6 [-1, 64, 7, 7] 0
Linear-7 [-1, 128] 401,536
Linear-8 [-1, 10] 1,290
================================================================
Total params: 421,642
Trainable params: 421,642
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.43
Params size (MB): 1.61
Estimated Total Size (MB): 2.04
----------------------------------------------------------------
步骤 4:定义损失函数和优化器
现在,我们需要定义一个[损失函数]和一个[优化器]。在这个例子中,我们将使用交叉熵损失和 ADAM 优化器。
# Define a loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
代码定义了神经网络的损失函数和优化器。
nn.CrossEntropyLoss() 是一个 PyTorch 函数,用于创建交叉熵损失函数的实例。交叉熵损失通常用于分类问题,因为它可以测量预测类别概率与真实类别之间的差异。它是通过对真实类别的预测类别概率取负对数来计算的。
optimizer = optim.Adam(model.parameters(), lr=0.001):此行创建 optim.Adam 类的实例,该类是常用于深度学习的优化算法。Adam 优化器是随机梯度下降的扩展,它使用参数的移动平均值来提供梯度二阶原始矩的运行估计;术语 Adam 源自自适应矩估计。它要求将模型的参数作为第一个参数传递,并将学习率设置为 0.001。学习率是一个超参数,它控制优化器更新模型参数的步长。
优化器和损失函数分别用于训练过程中更新模型的参数和评估模型的性能。
步骤 5:训练模型
现在,我们可以使用训练数据集训练我们的模型。我们将使用 100 的批处理大小,并将训练模型 10 个epoch。下面的代码使用循环在数据集上训练神经网络,该循环迭代训练时期的数量和训练数据集中的数据。
- batch_size = 100 和 num_epochs = 10 定义训练过程的批大小和轮数。批大小是用于神经网络一次前向和后向传递的训练数据集样本数。时期数是整个训练数据集通过网络的次数。
- torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) 为训练数据集创建一个 PyTorch DataLoader。DataLoader 将训练数据集作为输入并返回数据集上的迭代器。迭代器将在每次迭代中返回一组样本(图像和标签),其中样本数量由批次大小决定。通过设置 shuffle=True,DataLoader 将在每个时期之前随机打乱数据集。
- 外层循环,for epoch in range(num_epochs),迭代训练周期数。
- 内部循环 for i, (images, labels) in enumerate(train_loader) 遍历 DataLoader,返回一批图像和标签。使用输出 = 模型 (images) 将图像传递给模型,以获取模型的预测。
- 通过将模型的预测和真实标签传递给损失函数来计算损失,使用 loss = criterion(outputs, labels)。
- 优化器用于在最小化损失的方向上更新模型的参数。这通过以下 3 个步骤完成:
- optimizer.zero_grad() 清除所有可优化参数的梯度。
- loss.backward() 计算关于模型参数的损失的梯度。
- optimizer.step() 根据计算的梯度更新模型的参数。
- 每个时期结束后,代码会打印当前时期和时期结束时的损失。
在训练过程结束时,模型的参数将被更新,以最大限度地减少训练数据集的损失。
值得注意的是,在训练期间使用验证集来评估模型性能也很有用,这样我们就可以检测过度拟合并相应地调整模型。我们可以通过将训练集分为两部分来实现这一点:训练和验证。然后,使用训练集进行训练,并使用验证集在训练期间评估模型性能。
batch_size=100
num_epochs=10
# Split the training set into training and validation sets
val_percent = 0.2 # percentage of the data used for validation
val_size = int(val_percent * len(train_dataset))
train_size = len(train_dataset) - val_size
train_dataset, val_dataset = torch.utils.data.random_split(train_dataset,
[train_size,
val_size])
# Create DataLoaders for the training and validation sets
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True)
losses = []
accuracies = []
val_losses = []
val_accuracies = []
# Train the model
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Forward pass
images=images.to(device)
labels=labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, predicted = torch.max(outputs.data, 1)
acc = (predicted == labels).sum().item() / labels.size(0)
accuracies.append(acc)
losses.append(loss.item())
# Evaluate the model on the validation set
val_loss = 0.0
val_acc = 0.0
with torch.no_grad():
for images, labels in val_loader:
labels=labels.to(device)
images=images.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total = labels.size(0)
correct = (predicted == labels).sum().item()
val_acc += correct / total
val_accuracies.append(acc)
val_losses.append(loss.item())
print('Epoch [{}/{}],Loss:{:.4f},Validation Loss:{:.4f},Accuracy:{:.2f},Validation Accuracy:{:.2f}'.format(
epoch+1, num_epochs, loss.item(), val_loss, acc ,val_acc))
输出:
Epoch [1/10], Loss:0.2086, Validation Loss:14.6681, Accuracy:0.99, Validation Accuracy:0.94
Epoch [2/10], Loss:0.1703, Validation Loss:11.0446, Accuracy:0.95, Validation Accuracy:0.94
Epoch [3/10], Loss:0.1617, Validation Loss:8.9060, Accuracy:0.98, Validation Accuracy:0.97
Epoch [4/10], Loss:0.1670, Validation Loss:7.7104, Accuracy:0.98, Validation Accuracy:0.97
Epoch [5/10], Loss:0.0723, Validation Loss:7.1193, Accuracy:1.00, Validation Accuracy:0.96
Epoch [6/10], Loss:0.0970, Validation Loss:7.5116, Accuracy:1.00, Validation Accuracy:0.98
Epoch [7/10], Loss:0.1623, Validation Loss:6.8909, Accuracy:0.99, Validation Accuracy:0.96
Epoch [8/10], Loss:0.1251, Validation Loss:7.2684, Accuracy:1.00, Validation Accuracy:0.97
Epoch [9/10], Loss:0.0874, Validation Loss:6.9928, Accuracy:1.00, Validation Accuracy:0.98
Epoch [10/10], Loss:0.0405, Validation Loss:6.0112, Accuracy:0.99, Validation Accuracy:0.99
在此示例中,我们介绍了使用 PyTorch 在 MNIST 数据集上训练深度学习模型的基本步骤。可以使用更复杂的架构、数据增强和其他技术进一步改进此模型。PyTorch 是一个功能强大且灵活的库,可让您构建和训练各种模型,而此示例只是您可以使用它完成的开始。
步骤 6:绘制训练和验证曲线以检查过度拟合或欠拟合
模型训练完成后,我们可以绘制训练和验证损失和准确率曲线。这可以让我们了解模型在未知数据上的表现,以及模型是否过度拟合或欠拟合。
import matplotlib.pyplot as plt
# Plot the training and validation loss over time
plt.plot(range(num_epochs),
losses, color='red',
label='Training Loss',
marker='o')
plt.plot(range(num_epochs),
val_losses,
color='blue',
linestyle='--',
label='Validation Loss',
marker='x')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# Plot the training and validation accuracy over time
plt.plot(range(num_epochs),
accuracies,
label='Training Accuracy',
color='red',
marker='o')
plt.plot(range(num_epochs),
val_accuracies,
label='Validation Accuracy',
color='blue',
linestyle=':',
marker='x')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()
输出:
训练和验证损失
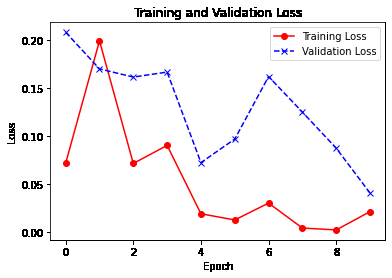
训练和验证准确率

注意,损失通常会随着每个时期而减少,而准确率则会提高,这是预期的情况。
步骤 7:模型评估
另一个重要方面是评估指标的选择。在此示例中,我们使用准确率作为评估指标,这对于许多问题来说都是一个很好的起点。但是,重要的是要注意,在某些情况下,准确率可能会产生误导,尤其是在类别不平衡的情况下。在这些情况下,应使用其他指标,例如准确率、召回率、F1 分数或 AUC-ROC。
训练模型后,您可以通过进行预测并将其与真实标签进行比较来评估其在测试数据集上的性能。评估分类模型性能的一种方法是使用[分类报告],该报告是模型在所有类别中性能的摘要。
首先是在测试数据集上评估模型,并通过使用 torch.max() 函数将预测标签与真实标签进行比较来计算其整体准确性。
然后,它使用 scikit-learn 库中的 分类_report 函数生成分类报告。分类报告通过计算精度、召回率、f1 分数和支持度等多项指标,为您提供模型在所有类别中的表现摘要。
精确度 – 精确度是真阳性数量除以真阳性数量加上假阳性数量。它衡量了阳性预测中有多少是正确的。
召回率 – 召回率是真阳性数量除以真阳性数量加上假阴性数量。它衡量了实际阳性病例中有多少被正确预测。
F1 分数 – F1 分数是精确度和召回率的调和平均值。它是一个代表精确度和召回率之间平衡的数字。
支持度——支持度是测试集中属于特定类别的实例数。
值得注意的是,分类报告是基于对整个测试集的预测计算的,而不仅仅是测试集的样本。
以下是如何评估模型并生成分类报告的示例:
# Create a DataLoader for the test dataset
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=False)
# Evaluate the model on the test dataset
model.eval()
with torch.no_grad():
correct = 0
total = 0
y_true = []
y_pred = []
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
predicted=predicted.to('cpu')
labels=labels.to('cpu')
y_true.extend(labels)
y_pred.extend(predicted)
print('Test Accuracy: {}%'.format(100 * correct / total))
# Generate a classification report
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred))
输出:
Test Accuracy: 99.1%
precision recall f1-score support
0 0.99 1.00 0.99 980
1 1.00 1.00 1.00 1135
2 0.99 0.99 0.99 1032
3 0.99 0.99 0.99 1010
4 0.99 0.99 0.99 982
5 0.99 0.99 0.99 892
6 1.00 0.99 0.99 958
7 0.98 0.99 0.99 1028
8 1.00 0.99 0.99 974
9 0.99 0.99 0.99 1009
accuracy 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
最后,重要的是要记住,深度学习模型需要大量数据和计算资源来训练。在大型数据集上训练模型可能需要很长时间,并且需要强大的 GPU。还有一些家云提供商提供可用于训练深度学习模型的 GPU 实例,如果您没有资源在本地训练模型,这可能是一个不错的选择。
总结
总而言之,使用 PyTorch 进行深度学习是一种强大的工具,可用于构建和训练各种模型。MNIST 数据集是学习基础知识的一个很好的起点,但重要的是要记住,在处理现实世界的数据集和问题时,还有许多其他方面需要考虑。有了正确的知识和资源,深度学习可以成为解决复杂问题和做出高精度预测的强大工具。
关于本文的数据集已经打包好了,需要的小伙伴可以自行获取学习。

















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











