







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
YOLO模型已成为计算机视觉领域最先进的实时对象检测和分割任务。YOLO 11代表了Ultralytics YOLO系列的最新进展。YOLO 11增强了早期YOLO模型的显著功能,在其架构和训练技术方面进行了实质性升级,使其成为各种计算机视觉应用的高度适应性解决方案。
在这篇文章中,我们将详细比较YOLOv8和YOLOv11在各个方面的性能。最终,我们将在自定义数据集(火灾和烟雾数据集)上比较两个模型的结果。
用于比较的关键指标
- 型号版本(n,s,m,l,x):由Ultralytics开发的YOLO型号有不同的尺寸,即nano(n),small(s),medium(m),large(l)和extra-large(x)。较大的模型往往更加复杂和强大,但是,它们也需要更多的资源,并且运行速度较慢。
- mAP(Mean Average Precision): mAP**分数告诉我们模型在检测对象方面的准确性。**该计算基于模型识别与图像中存在的实际对象重叠程度不同的对象的能力。更高的平均精度(mAP)表示模型的准确性更高,这意味着其检测和准确定位图像中对象的能力增强。
- 速度(以毫秒为单位):速度告诉我们模型处理图像的速度。有两种类型的速度,CPU速度:这衡量了它在常规计算机处理器(CPU)GPU速度上的运行速度:这衡量了它在A100或T4等特定NVIDIA GPU上的运行速度,这些GPU通常用于高性能AI任务。
- Params(M):这表示特定模型的参数数量(以百万计)。模型越大,参数越多。
- FLOPs(B):FLOPs(浮点运算)表示模型的计算复杂度。更高的FLOP意味着模型需要更多的计算资源。它以十亿为单位来衡量。
YOLOv8与YOLOv11:逐模型比较
现在您已经了解了关键指标,让我们比较一下YOLOv8和YOLOv11的性能,
YOLOv8n vs YOLOv11n
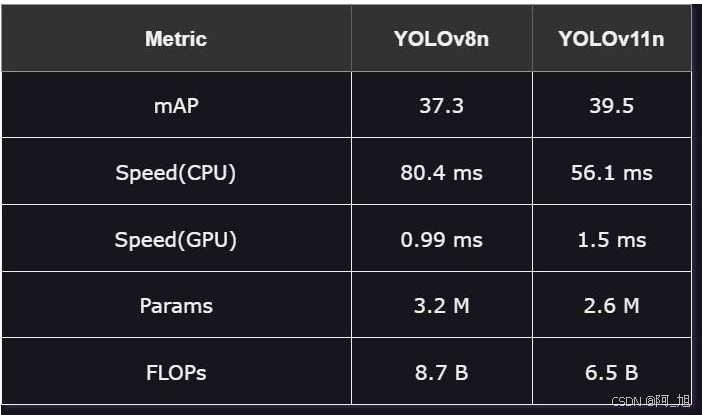
纳米模型最小、最快的模型,参数最少。
1.性能:YOLOv11n在准确性上超过YOLOv8n,平均精度(mAP)为39.5,而YOLOv8n为37.3,这表明YOLOv11n具有上级的图像目标检测能力。
2.速度:在标准CPU上,YOLOv11n的运行速度更快,为56.1 ms,而在高性能GPU上则稍慢。
3.效率:YOLOv11n提供更高的精度,同时使用更少的参数和更低的FLOP,表现出比YOLOv8n更高的效率。
YOLOv8s vs YOLOv11s
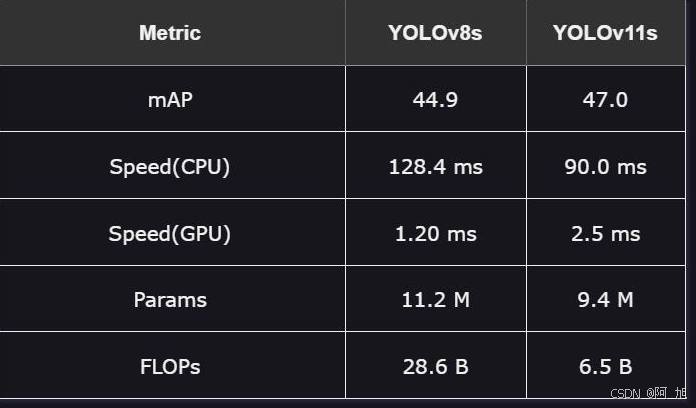
1.性能:YOLOv11在准确性方面优于YOLOv8,平均精度(mAP)为47.0,而YOLOv8为44.9,这使其成为优先考虑精度的首选。
2.速度:YOLOv11 s在CPU性能方面也表现出色,而YOLOv8 s在A100等GPU上表现出上级速度。
3.效率:由于其减少的参数数量和较低的计算需求,YOLOv11以较低的处理能力提供了更高的精度。
YOLOv8m vs YOLOv11m
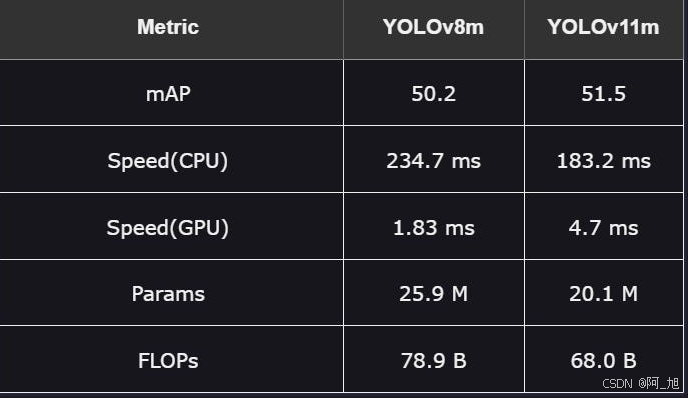
中型型号提供了较小和较大版本之间的权衡。
1.性能:与YOLOv8m相比,YOLOv11m在精度上略有提高。
2.速度:YOLOv11m在CPU上表现出更高的速度**,尽管它在GPU上的执行速度较慢,这可能会影响您的特定应用程序。
3.效率:YOLOv11m在保持更高精度的同时,减少了参数和FLOP的数量,突出了其有效的任务管理。
YOLOv8l vs YOLOv11l
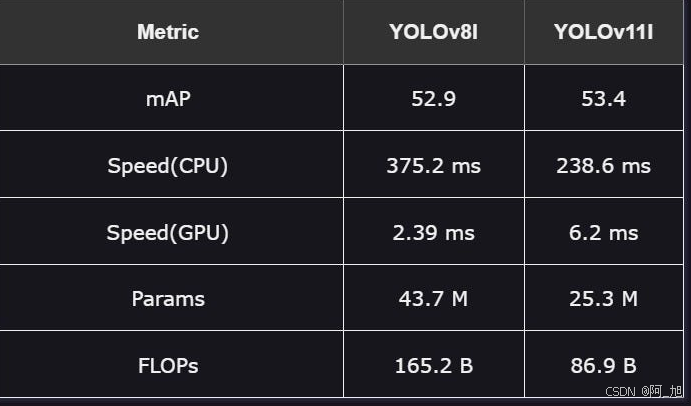
这些较大的型号专为精度比速度更重要的任务而设计。
1.性能:精度上的差异很小,但YOLOv11l保持了微弱的优势。
2.速度:YOLOv11 l在CPU上表现出上级速度,尽管在GPU上要慢得多。
3.效率:YOLOv11l以更少的资源实现更大的结果,减少了参数和FLOP,同时仍然超过YOLOv8l。
YOLOv8x与YOLOv11x
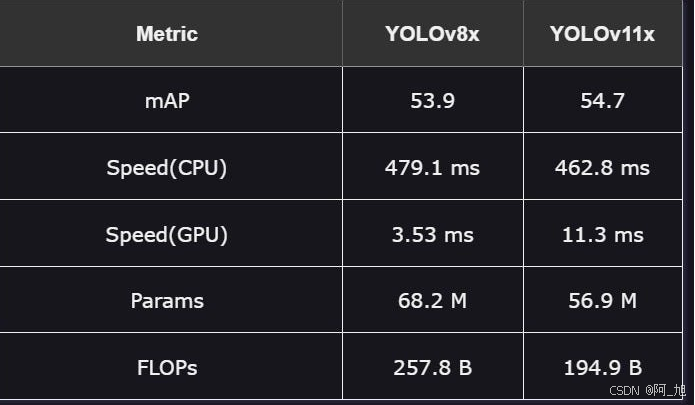
超大型模型是最精确的,但也是最消耗资源的。
1.性能:YOLOv11x在精度上超过YOLOv8x,但差距很小。
2.速度:YOLOv11x在CPU和GPU上表现出较慢的性能,优先考虑准确性而不是速度。
3.效率:YOLOv11x管理相同的任务,减少资源消耗,使用更少的FLOP和参数,同时实现更高的准确性。
自定义训练模型的结果。
我使用相同的数据集(Fire and Smoke数据集)对YOLOv8n和YOLOv11n模型进行了100个epoch的自定义训练,将置信度阈值保持为0.35,并将所有其他超参数设置为默认值。结果出来了。
图像结果:



在某些情况下,YOLOv8识别出YOLOv11遗漏的额外边界框,而在其他情况下,YOLOv11显示出比YOLOv8更高的置信度百分比。但这种变化取决于所分析的特定图像,不同数据集可能会表现出不同的结果。
总结
本文比较了YOLOv8和YOLOv11的性能,强调了YOLOv11在不同模型大小下在准确性、速度和效率方面的改进。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 5245
5245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











