







《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
mAP(mean Average Precision)是目标检测中广泛使用的评价指标,但它不能直接应用于标准的分类问题。
原因如下:
目标检测任务不仅需要考虑检测的目标分类,而且需要考虑目标的定位精度,也就是位置信息。而mAP的主要作用就是用于评估边界框预测的准确性。
常见评估指标
由于目标检测任务包含目标位置检测与分类两项内容。因此目标分类的各项评估指标,同样适用于对于目标检测任务评估,只是在目标检测任务中额外多了一个mAP评估指标。
在分类任务中,我们主要关心的是如何将标签正确地分配给各个数据。分类任务常见的评估指标包括:
-
准确度Accuracy: 正确分类样本的总体比例。
-
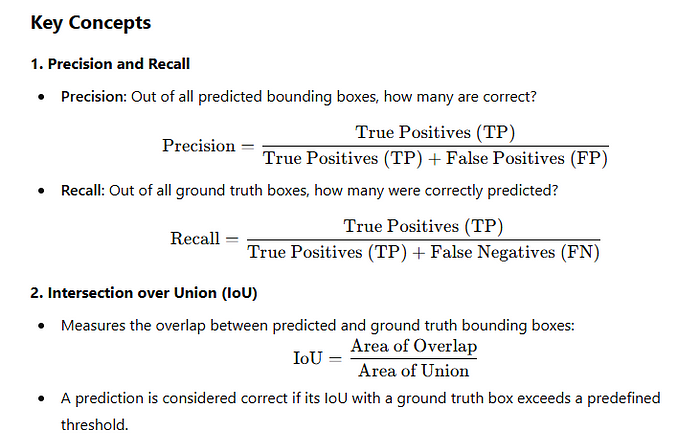
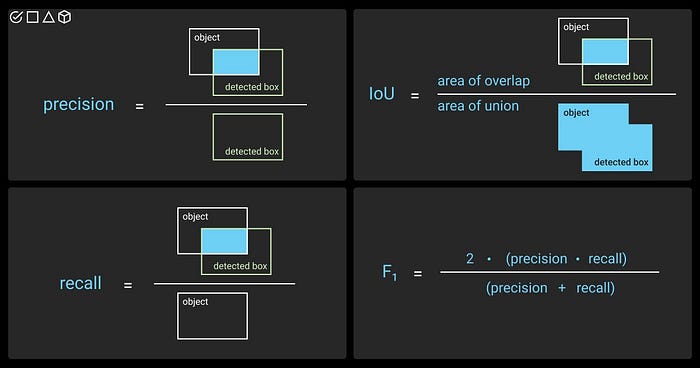
精确度Precision:精确度衡量模型预测为正类的样本中,实际为正类的比例。公式为:
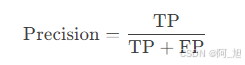
TP(True Positive):模型正确预测为正类的样本数。
FP(False Positive):模型错误预测为正类的样本数。
意义:精确度越高,模型预测为正类的样本中错误越少。
- 召回率Recall: 召回率衡量实际为正类的样本中,模型正确预测为正类的比例。公式为:
FN(False Negative):模型错误预测为负类的样本数。
意义:召回率越高,模型漏掉的正类样本越少。
-
F1分数: 精确度和召回率的调和平均值。

-
混淆矩阵: 真阳性、真阴性、假阳性和假阴性的详细分类。
示例
假设你有一个模型,可以将动物图像分类为“猫”或“狗”。
- **准确度:**在100张图像中,模型正确分类了90张图像。Accuracy= 90/100 = 0.9。
- **精确度:**在50张被预测为“猫”的图片中,有45张是猫。Precision= 45/50 = 0.9。
- **召回率:**在60张真实的猫图像中,模型正确地预测出45张是猫。Recall= 45/60 = 0.75。
总的来说:
- mAP是专门为定位和分类都至关重要的目标检测任务而设计的。
- 对于标准分类问题,准确度、精确度、召回率、F1分数和混淆矩阵等指标更合适,信息量也更大。
目标检测模型评估标准
当我们衡量物体检测器的质量时,我们主要想评估两个标准:
- 模型预测了对象的正确类别。
- 预测的边界框足够接近真实情况。
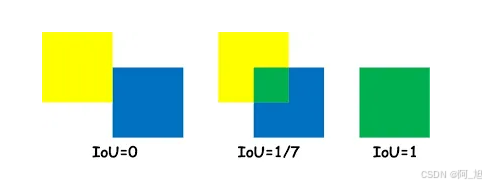
IOU交并比
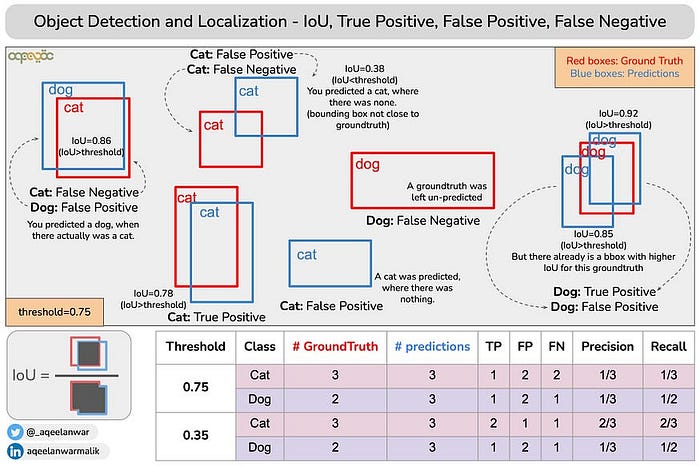
了解mAP之前需要介绍一下IoU【Intersection over Union交并比】。交集/并集是两个边界框对齐程度的度量,它通常用于衡量预测框与真实值的质量。
目标检测器中的真/假阳性和真/假阴性
对象检测器是典型的多类分类器,但也具有对象定位因子。
真阳性
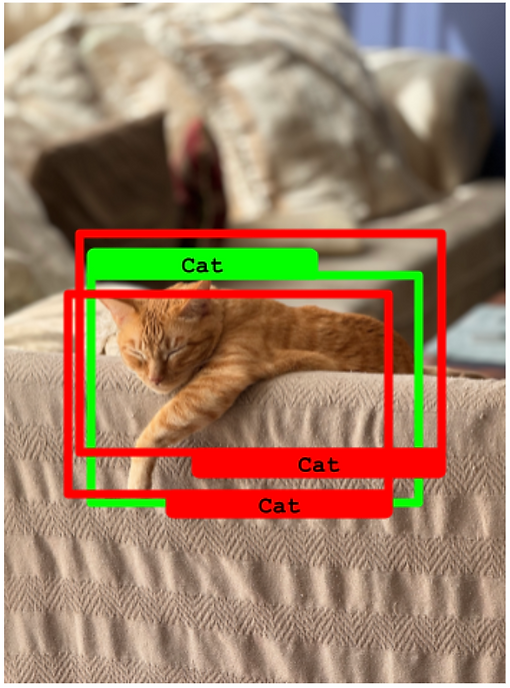
- 预测边界框相对于真实框的IoU高于50%,同时预测类与基本事实相匹配,我们认为是一个真阳性。
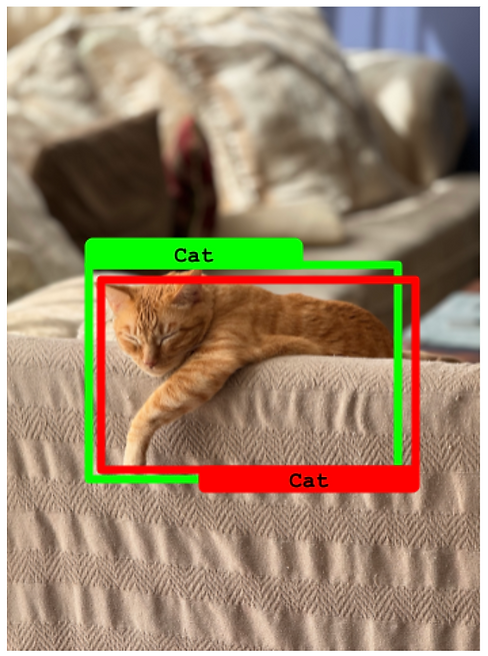
物体检测中的真阳性示例图
假阳性
- 预测边界框的IoU低于50%(相对于实际框**),或没有目标,或者 预测类与实际类别不匹配。
- 预测框和实际框之间的重叠太少,或者预测和实际框根本没有重叠
假阴性
- 定义:当模型未能检测到图像中实际存在的对象时,会发生假阴性。
- 每个没有匹配预测的真实框都被认为是假阴性
- 示例:
- **图像:**包含猫的图像。
- **真实框:**绿色框指示猫的存在和位置。
- **模型预测:**模型没有检测到图像中的猫。
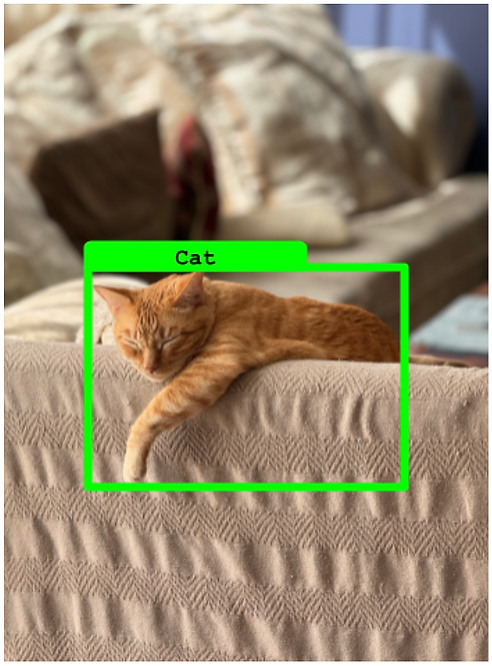
真阴性
在对象检测中,我们通常不会显式地计算True Negatives
- 大量的“Negative Location”: 想象一个图像。有无数潜在的边界框可以画在上面,这些框中的绝大多数将代表“背景”–没有对象存在的区域。
- 专注于检测: 在对象检测中,我们的主要兴趣在于识别和定位对象的存在。我们想知道:
- 真阳性(TP): 模型是否正确检测和定位物体?
- 假阳性(FP): 模型是否预测了不存在的对象?
- 假阴性(FN): 模型是否遗漏了实际存在的对象?
示例
在下图中,有两个实际目标,但只有一个预测框。在这种情况下,预测只能归因于一个目标框(IoU高于50%)。因此,另一个实际框变成了假阴性。
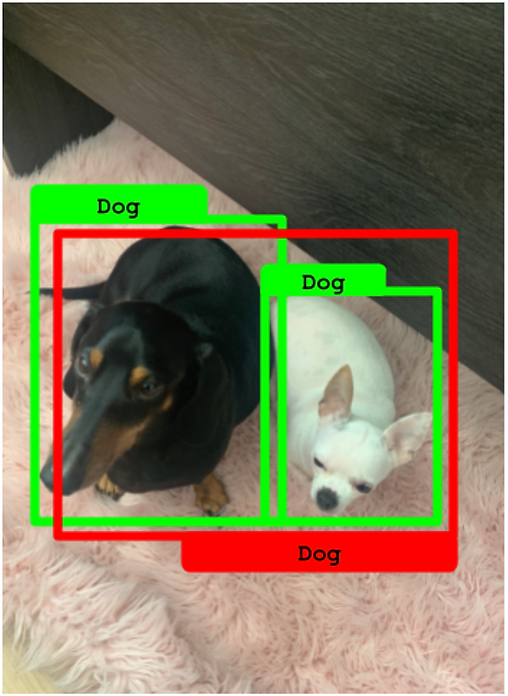
预测只能分配给一个真实框。另一个真实框变成了假阴性。
在下一个例子中,对同一个真实框进行了两次预测。然而,他们两个都有不理想的IoU低于50%。在这种情况下,这两个预测被视为假阳性,而孤立的真实框是假阴性。
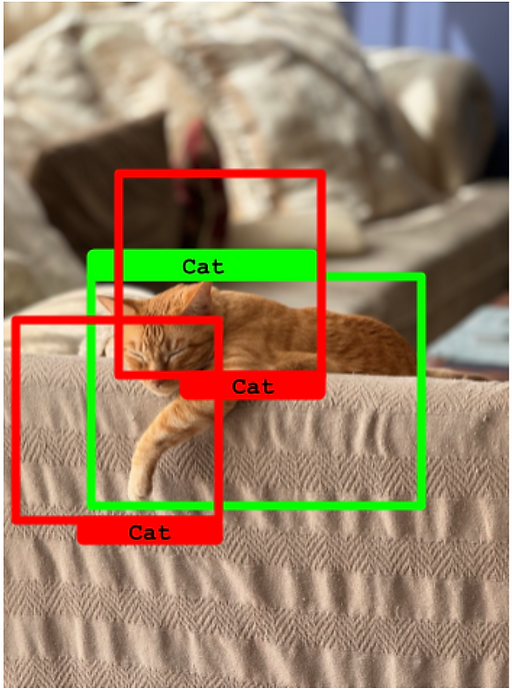
在最后一个例子中,我们有一个类似的场景,两个预测框都有很好的IoU(超过50%)。在这种情况下,具有最佳IoU的一个被认为是真阳性,而另一个则成为假阳性。
置信度: 在输出图像中,您可以看到预测类旁边有一个数字。该数字表示模型对边界框中的对象属于某个类别的置信度。在下图中,你可以看到模型有96%的置信度,框里的物体是一辆汽车。
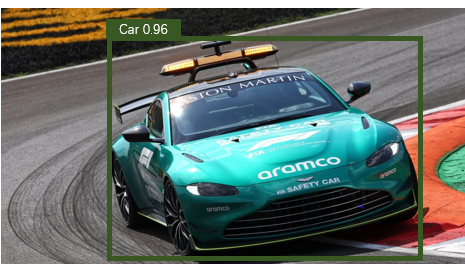
96%置信度预测
精确度、召回率和F1分数
现在我们知道如何将TP、FP、TN和FN应用于对象检测器,我们可以从分类器中借用其他指标。这些是精确度,召回率和**F1分数。**同样,这些指标是按类别衡量的。下表总结了它们:


精确度Precision
对于给定的类,精度告诉我们类预测实际上来自该类的百分比。下图显示了检测器的结果,其中有3个真阳性和1个假阳性,因此精度为:
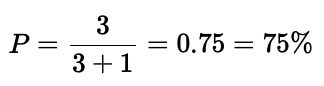

三人,但对于被发现的人
召回率Recall
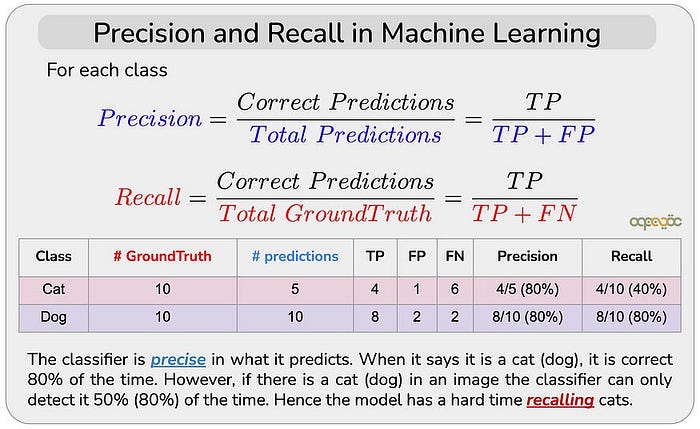
TP、FP、FN、TN、Precision和Recall总结
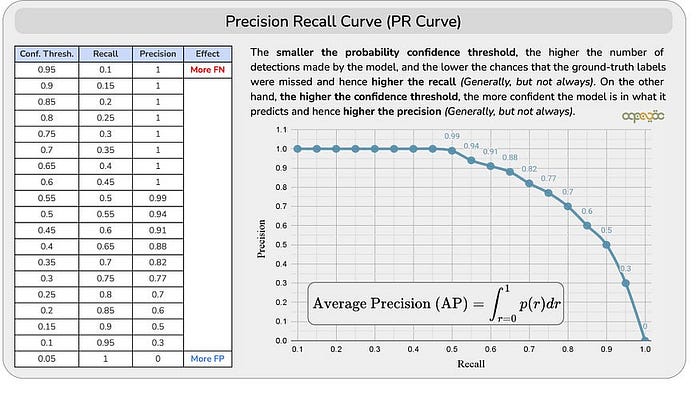
精确度召回率曲线
精确度-召回率曲线绘制了不同置信度阈值下的精确度与召回率的值。
平均精度AP
AP是PR曲线的曲线下面积(AUC)。
理解置信度阈值
- **对象检测模型和置信度得分:**对象检测模型通常为每个检测到的对象输出置信度得分。该分数表示模型确定检测到的对象属于特定类别。
- **选择置信度阈值:**为了确定检测是否有效,我们需要设置置信度阈值。如果模型的检测置信度得分超过此阈值,则该检测被视为阳性预测。
- **置信度的主观性:**选择“最佳”置信度阈值可能是主观的,并且可能会显著影响模型的性能指标。
为什么平均精度(AP)很重要
- 克服阈值依赖性: AP通过计算置信度阈值范围内的平均精度来解决阈值敏感性问题。
- 考虑整个性能曲线: AP不依赖于单一阈值,而是考虑模型在各种置信水平下的性能,从而提供更全面的评估。
- 精确-召回曲线: AP本质上是精确-召回曲线下的面积。这条曲线描绘了随着置信度阈值逐渐降低,精确度与召回率的关系。
AP如何工作:
- 生成检测: 对象检测模型生成一个检测列表,每个检测都有一个置信度得分和边界框坐标。
- 检测排序: 按照置信度分数的降序对检测排序。
- 计算精确度和召回率:
- 对于排序列表中的每个检测:
- 计算精确度:真阳性检测与该点检测总数的比值。
- 计算召回率:真阳性检测与地面真实对象总数的比率。
4.绘制精密度-召回率曲线:
- 在图表上绘制每个检测的精确度和召回率值。
5.计算AP:
- 计算精确度-召回率曲线下面积。此区域表示平均精度。
总之
通过计算AP,我们获得了一个单一的,强大的度量,总结了模型在一系列置信阈值的性能。这消除了与选择单个可能任意的阈值相关联的偏差。mAP(mean Average Precision)则通过对多个类的AP求平均值来扩展此概念,从而提供对模型性能的总体评估。
两种方法计算PR曲线下面积
方法1 -用矩形近似PR曲线
- 对于每个精确度-召回率对(j=0,.,n-1),PR曲线下的区域可以通过使用矩形逼近曲线来找到。
- 这样的矩形的宽度可以通过取两个连续召回值(r(k),r(k-1))的差来找到,并且高度可以通过取所选召回值的精度的最大值来找到,即w = r(k)-r(k-1),h = max(p(k),p(k-1))
- AP可以通过这些矩形的面积之和计算,如下所示
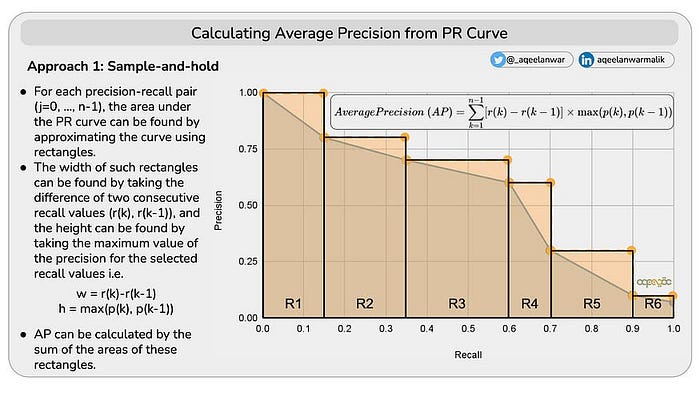
从PR曲线计算平均精度
方法2 -插值和11点平均值
- 计算从0.0到1.0的11个查全率值的精度值,增量为0.1
- 这11个点在右图中可以看作是橙色样本
- AP可以通过取这11个精度值的平均值来计算,如下所示
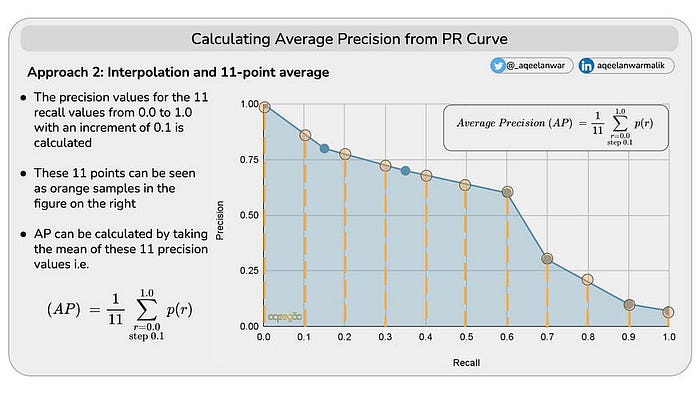
精确度-召回率曲线下的面积(AUC-PR)表示特定类别的对象检测模型的整体性能
- AP不直接提供最佳阈值。
- 它提供了对模型在一系列阈值上的性能的全面理解。
- 这种理解有助于您做出明智的决定,确定最适合您特定应用需求的置信度阈值。
- 例如,如果高精度是至关重要的(例如,在医疗成像应用中,误报会产生严重后果),您可以选择更高的阈值以最大限度地减少误报。
- 如果高召回率更重要(例如,在监视系统中,检测所有潜在威胁至关重要),您可以选择较低的阈值以最大化检测数量
mAP(mean Average Precision)
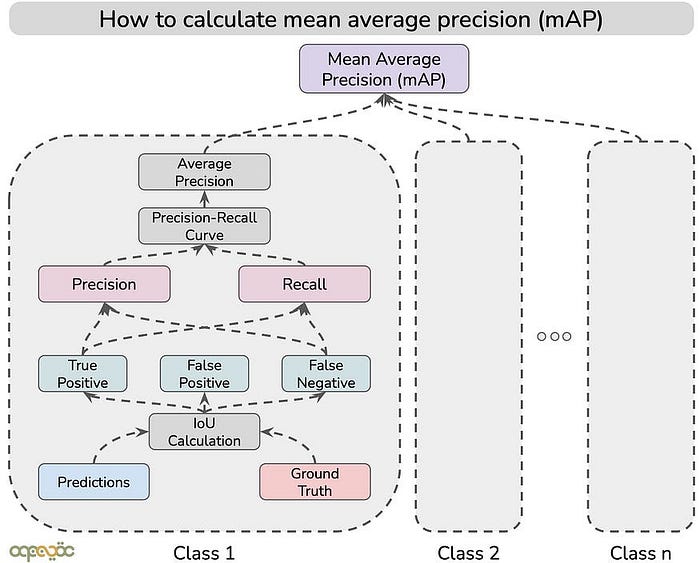
简单来说:
假设您有一个检测汽车和行人的模型。
- “汽车”的AP衡量模型检测汽车效果。
- “行人”的AP表示模型检测行人的能力。
- mAP对“汽车”和“行人”的AP分数取平均值,为您提供模型在两个类别中的总体性能分数。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 4160
4160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











