






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者:Sarath Chandra
编译:ronghuaiyang
导读
将配准从2D场景扩展到3D场景。
上周我开发了一个基于深度学习的2D可变形图像配准的基本框架,并演示了如何从MNIST数据集中配准手写数字图像。除了损失函数和架构上的细微差别外,该框架本质上与VoxelMorph框架相同。
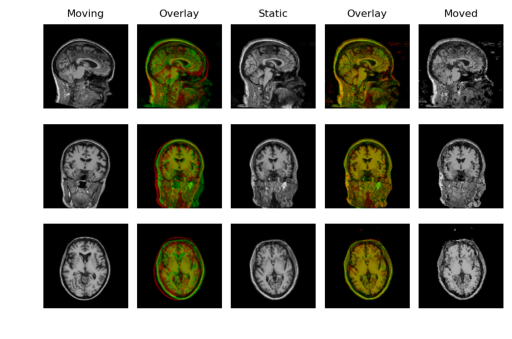
本周,我的任务是将该实现扩展到3D,并在一个包含150个T1-weighted扫描的小数据集上进行试验。通过对现有代码进行一些细微的更改,我能够实现原始的VoxelMorph模型。我使用一个扫描作为静态图像,其余的作为移动图像(125用于训练,25用于测试)。
样本输出
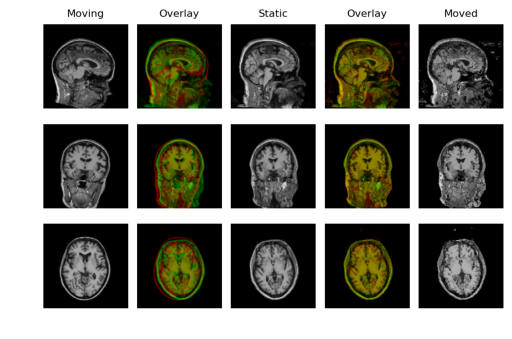
配准效果不佳的原因是这些volumes没有去掉头骨。会议上有人向我指出,脑提取是配准的一个重要预处理步骤,即去除颅骨和眼睛等非脑组织。
基于深度学习的仿射配准
我想看看像刚性变换和仿射变换这样的简单变换是否有效。所以我很快修改了代码来做无监督的2D仿射配准。这个想法是空间变压器网络的一个简单推论。
2D仿射变换配准的Colab notebook:https://colab.research.google.com/drive/1drp2ny2t-nxddkt4pezn6mtjehnfccw
方法
卷积神经网络以移动图像和静态图像为输入,计算使移动图像弯曲和对齐到静态图像所需的仿射变换参数。在二维配准的情况下,这些参数有6个,控制旋转、缩放、平移和剪切。
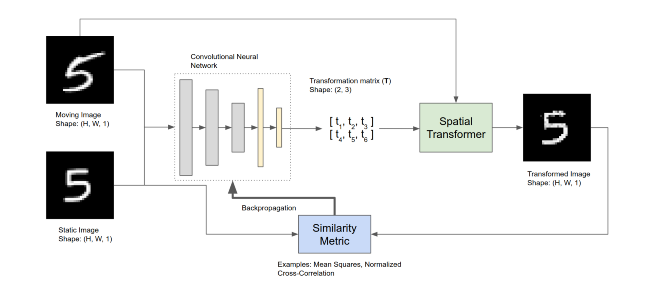
训练卷积神经网络输出两幅输入图像之间的仿射变换参数T,空间变压器网络利用这些参数对运动图像进行变换。
空间变压器block取仿射参数和运动图像,执行两项任务:
计算采样网格
使用采样网格重新采样移动图像
在规则网格上应用仿射变换得到新的采样网格,即运动图像的采样点集。将输出中的每个位置映射到输入中的一个位置,使用如下公式:
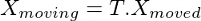
由于新的采样位置可以是非积分的,双线性插值用于可微的采样,并允许梯度流回卷积神经网络,使整个框架端到端可微。
训练
MNIST数据集经过筛选,只保留一类图像,而静态图像是从筛选后数据集的测试集中随机选择的。使用归一化交叉相关(NCC)训练网络。数学上是:
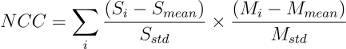
S和M分别代表静态图像和运动图像。下标mea和std分别表示图像的均值和标准差。图像中所有像素的求和。该训练在Tesla K80 GPU上大约需要5分钟,在CPU (i5-8250U)上大约需要10分钟。
2D的结果

扩展到3D
我修改了2D配准的代码,使其适用于3D volumes,并在T1-weighted扫描上进行了尝试。AIRNet的工作,与此相似。但与AIRnet不同的是,它是在监督的方式下训练的,并且需要ground-truth仿射变换参数,这是在无监督的方式下训练的,就像VoxelMorph。
3D的结果
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









