






前言
RAG虽然强大,但是并不能满足企业所有的需求,比如某公司,做财务的,所以会有很多发票数据,相信大家也经历过公司复杂的报销流程,发票通常又分为交通票、餐饮票、文具票等等类型,所以,某公司希望能对发票进行智能分类,而这就属于机器学习任务中的分类任务,相信大家结合所在公司的情况,可能也能想到一些类似的场景,比如比较经典的有商品评论智能分类,也就是利用机器学习模型来判断一段评论是好评还是差评,接下来,就来看看如何利用大模型来实现企业自己的分类任务。
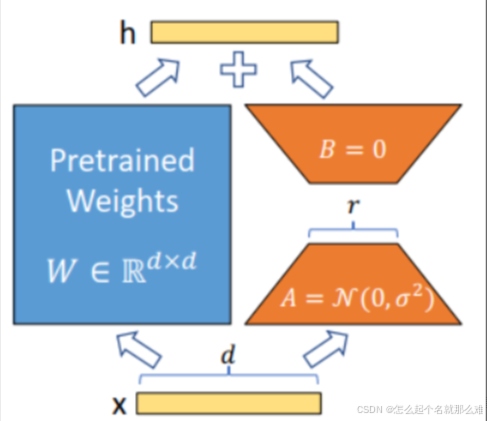
大模型的参数量很大,如果我们基于大模型进行全量的训练,那就需要很多的GPU资源,所以需要微调,而基于Lora的微调则更轻量
一、量化介绍
fp16和int8量化是两种用于优化深度学习模型性能的技术,它们通过减少模型中使用的数据类型的精度来减少计算资源的需求和加速推理过程。
fp16是指使用16位浮点数(half-precision floating-point)格式来表示模型的权重和激活值。标准的32位浮点数(single-precision floating-point,或fp32)使用1位表示符号,8位表示指数,以及23位表示尾数(有效数字)。相比之下,fp16使用1位表示符号,5位表示指数,以及10位表示尾数。
使用fp16的好处包括:
● 减少模型的内存占用,因为每个数字只使用16位而不是32位。
● 加速计算,因为在相同的硬件资源下,可以在同一时间内处理更多的16位数。
● 降低能耗,因为进行运算所需的能量更少。
然而,fp16的缺点是精度降低,可能会导致训练过程中的数值不稳定性。为了缓解这个问题,通常会结合使用fp16和fp32,这种方法被称为混合精度训练(mixed precision training)。
int8量化是指将模型的权重和激活值从浮点数(如fp32)转换为8位整数。这种转换通常在模型训练完成后进行,作为模型部署前的一个优化步骤。
使用int8量化的好处包括:
● 进一步减少模型的内存占用,因为每个数字只使用8位。
● 加速推理过程,因为整数运算通常比浮点运算更快。
● 降低能耗,因为整数运算通常更加能效。
int8量化的挑战在于如何在不显著降低模型性能的情况下选择合适的量化策略。量化可能会导致信息损失,因此需要仔细选择量化参数,以及可能需要对量化后的模型进行校准。
总的来说,fp16和int8量化都是为了在保持模型性能的同时,减少模型的大小和加速推理过程。这些技术在部署到资源受限的设备(如移动设备和嵌入式系统)时尤其有用
二、微调过程
选择机器
GPU RTX 4090 内存64G
下载模型
pip install modelscope
pip install transformers
执行代码
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
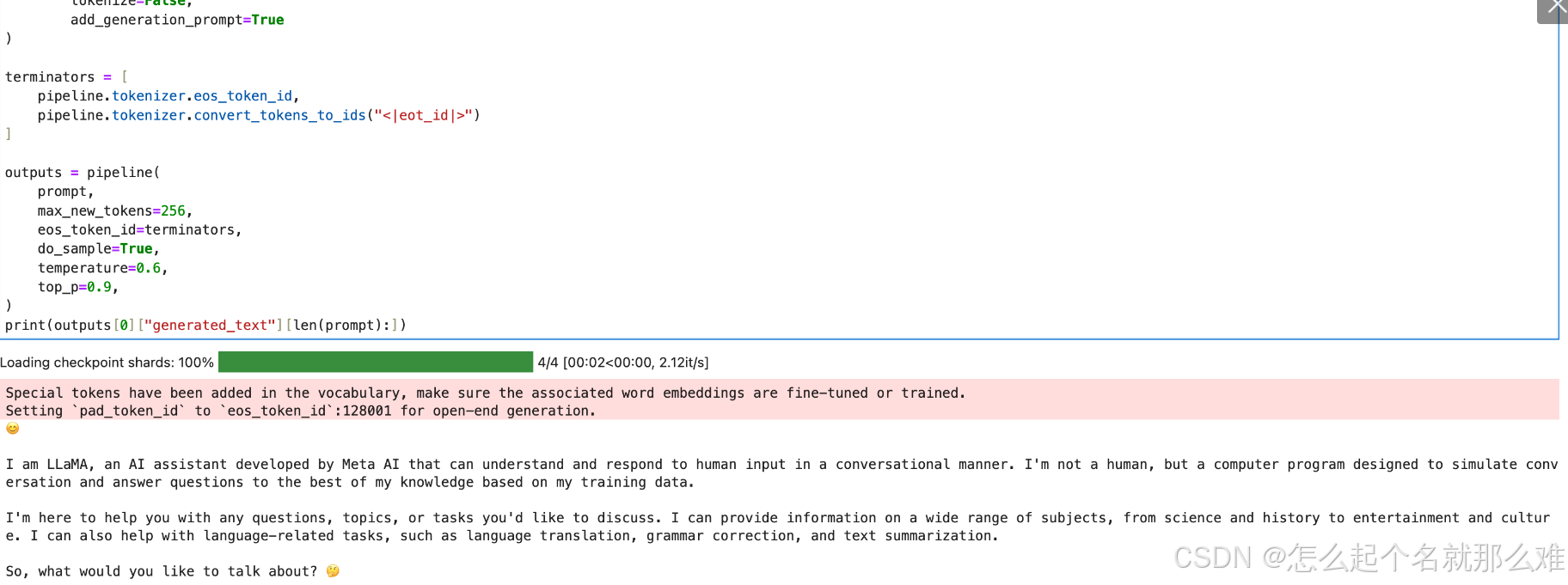
使用ModelScope进行推理
import transformers
import torch
pipeline = transformers.pipeline(
"text-generation",
model="/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "user", "content": "你是谁?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
准备微调数据
搞笑:弱智AI
这里有对应的json数据,请自己获取
https://modelscope.cn/datasets/baicai003/Llama3-Chinese-dataset/files
[
{
"instruction": "爸爸再婚,我是不是就有了个新娘?",
"output": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"
},
{
"instruction": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买",
"output": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"
},
{
"instruction": "马上要上游泳课了,昨天洗的泳裤还没干,怎么办",
"output": "游泳时泳裤本来就会湿,不用晾干。"
},
{
"instruction": "为什么没人说ABCD型的成语?🤔",
"output": "这是因为中文成语一般都是四字成语,每个字都有其特定的含义,四个字合在一起构成一个完整的意思。而ABCD型的成语最常见,所以大家不会刻意强调。"
},
{
"instruction": "我只出生了一次,为什么每年都要庆生",
"output": "庆生并不是为了庆祝出生,而是为了庆祝每一次的生日,也就是出生后的每一年。这是一个纪念自己在过去一年中成长和经历的方式,也是对未来一年的期待和祝福。"
},
{
"instruction": "我25岁 我爸50岁 那我爸两岁就生了我啦?",
"output": "不对,你25岁,你爸50岁,那么你爸在你出生时应该是25岁,而不是两岁。"
},
{
"instruction": "为什麽我老婆内裤拔下来没有马赛克?",
"output": "因为现实生活中并没有马赛克这种东西,马赛克是电视、网络等媒体为了遮挡一些不适宜公开的画面或者保护隐私而使用的一种手段。"
}]
训练
pip install peft
pip install accelerate
from datasets import Dataset
import pandas as pd
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer, GenerationConfig
import torch
from peft import LoraConfig, TaskType, get_peft_model
# 将JSON文件转换为CSV文件
df = pd.read_json('./ruozhi.json')
ds = Dataset.from_pandas(df)
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct')
tokenizer.pad_token = tokenizer.eos_token
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
f"<|start_header_id|>user<|end_header_id|>\n\n{example['instruction']}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens
response = tokenizer(f"{example['output']}<|eot_id|>", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)
print(tokenizer.decode(tokenized_id[0]['input_ids']))
tokenizer.decode(list(filter(lambda x: x != -100, tokenized_id[1]["labels"])))
model = AutoModelForCausalLM.from_pretrained('/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct',
device_map="auto", torch_dtype=torch.bfloat16)
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1 # Dropout 比例
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
args = TrainingArguments(
output_dir="./output/llama3",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=10,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()
peft_model_id = "./llama3_lora"
trainer.model.save_pretrained(peft_model_id)
tokenizer.save_pretrained(peft_model_id)
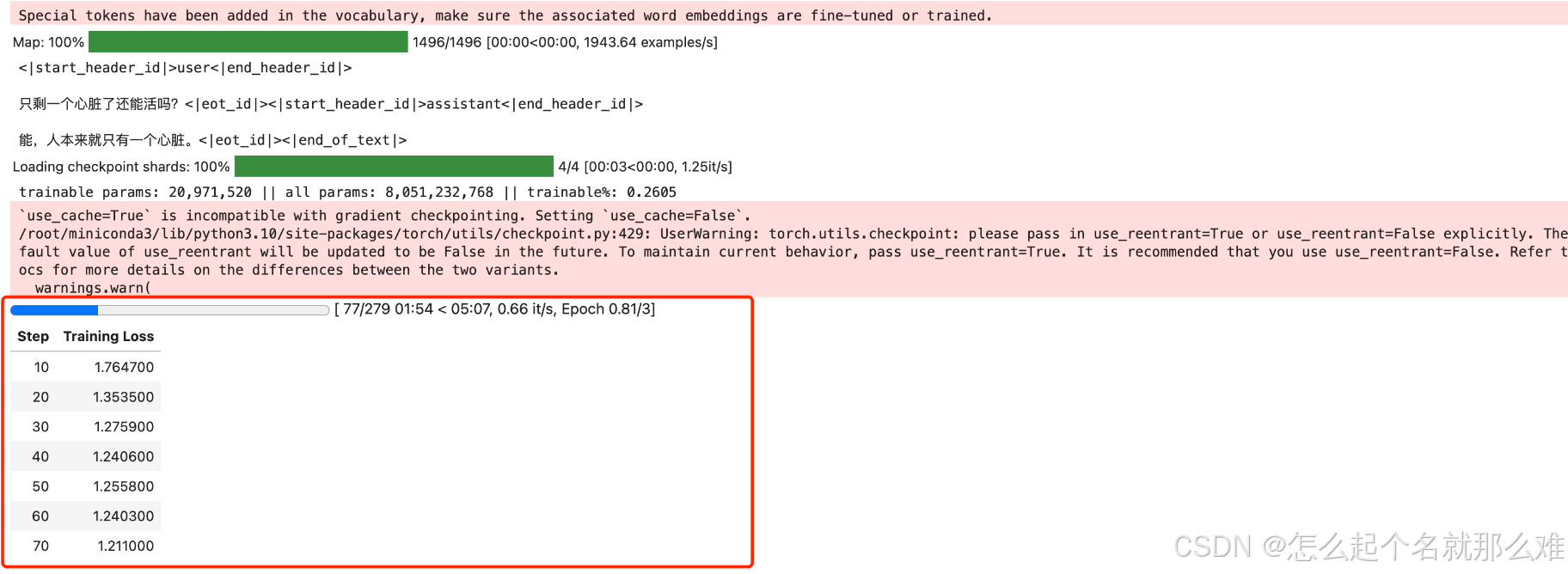
训练过程截图
推理
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, TaskType, get_peft_model
import torch
from peft import PeftModel
mode_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct'
lora_path = './llama3_lora'
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, torch_dtype=torch.bfloat16)
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1# Dropout 比例
)
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path, config=config).to("cuda:0")
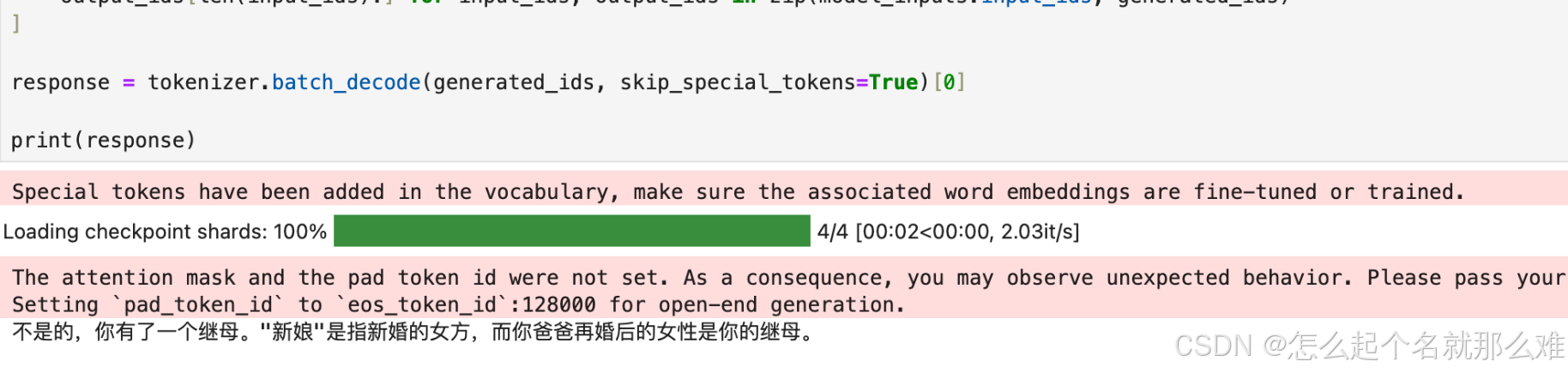
prompt = "只剩一个心脏了还能活吗?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda:0")
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
eos_token_id=tokenizer.encode('<|eot_id|>')[0]
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
微调结果



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











