






问题描述:
YOLOV8作为目前主流的深度学习网络,支持图像分类、目标检测、实例分割、姿态检测、旋转目标检测等功能。
对于目标检测任务官方提供了n/s/m/l/x五个模型,我们在使用YOLOV8模型进行自己任务训练时,应该如何选择YOLOV8的模型以及输入尺寸大小呢?
YOLOV8官网:https://github.com/ultralytics/ultralytics
YOLOV8n/s/m/l/x信息及在coco数据集上训练效果如图所示:
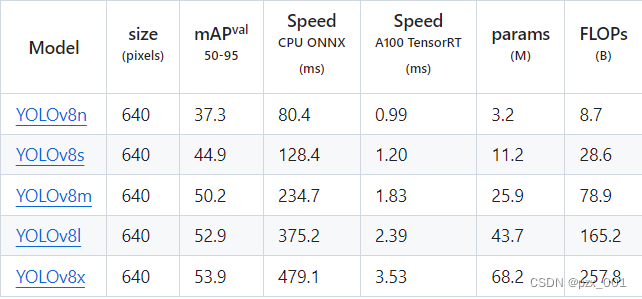
1. 关于模型选择
一般来说选择模型大小原则如下:
- 数据集小(几百张图片):使用yolov8n或yolov8s,过大模型容易产生过拟合
- 数据集中等(几千张图片):使用yolov8s或yolov8m,能够获得较高精度,不易过拟合
- 数据集大(几万张图片):使用yolov8l或yolov8x,模型容量大,充分拟合大量数据,能够发挥模型效果
- 超大数据集(几十万张 图片):使用yolov8x,超大模型才能够处理海量数据并获得最优效果
数据集复杂程度也会影响模型选择,一般对象越多、图像越复杂,需要选择的更大的模型来拟合更复杂的数据保证效果
2. 关于输入尺寸选择
在实际项目中,对于图片输入大小的选择通常要从多方面考虑:
- 目标检测精度的要求:一般来说较小的输入尺寸对大目标的检测效果更好,较大的输入尺寸对较小的目标检测效果更好
- 计算资源的限制:较大的模型、较大输入尺寸会占用更多计算资源,导致推理速度变慢
要根据计算资源、检测速度要求、检测精度要求、检测的目标在实际检测场景中大小和分布情况,选择合适的模型及输入尺寸大小。
注意:以上只是个人的思考和见解,具体关于模型大小与输入尺寸大小的选择,要根据自己项目的具体情况而定。根据项目具体需求进行试验和调优,比较不同模型、不同输入尺寸下检测精度和推理速度, 选择最适合的模型和输入尺寸。
本文参考:https://blog.csdn.net/watson2017/article/details/140010217

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









